Command Palette
Search for a command to run...
强化学习如何提升视觉推理能力?一种“怪物合成式”的分析
强化学习如何提升视觉推理能力?一种“怪物合成式”的分析
Xirui Li Ming Li Tianyi Zhou
摘要
基于可验证奖励的强化学习(Reinforcement Learning, RL)已成为提升视觉-语言模型视觉推理能力的标准后训练阶段,然而,相较于以监督微调作为冷启动初始化(IN)的方法,RL究竟在哪些具体能力上带来了改进,目前仍不清晰。端到端基准测试的提升结果往往混杂了多种因素,难以将性能增益准确归因于特定技能。为填补这一空白,我们提出了一种“弗兰肯斯坦式”(Frankenstein-style)的分析框架,包含三个核心组件:(i)通过因果探针实现功能定位;(ii)通过参数对比进行更新特征刻画;(iii)通过模型融合开展可迁移性测试。研究发现,RL主要在中层到深层网络中引发一致的推理时态迁移,而这些中层至深层的优化既可通过模型融合实现可迁移性,又在冻结模型后对RL性能提升具有必要性。总体而言,我们的结果表明,RL在视觉推理中的可靠贡献并非对视觉感知能力的普遍增强,而是一种系统性的中层至深层Transformer计算过程的精细化优化,其核心作用在于提升视觉信息到推理过程的对齐程度,从而增强推理性能。这一发现揭示了仅依赖基准测试评估难以充分理解多模态推理能力提升的局限性。
一句话总结
李曦睿与李明(马里兰大学)联合周天毅(MBZUAI)提出一种“弗兰肯斯坦式”框架,揭示强化学习(RL)在视觉推理任务中优化的是中后段 Transformer 层——而非视觉感知模块——从而提升视觉到推理的对齐能力,该结论通过因果探测、参数分析和模型合并验证。
主要贡献
- 视觉语言模型(VLM)的 RL 后训练并未均匀提升视觉感知能力,而是引发中后段 Transformer 层的一致性、特定层优化,从而提升视觉到推理的对齐能力。
- 通过结合因果探测、参数比较和模型合并的“弗兰肯斯坦式”框架,研究定位了 RL 的功能影响,并证明这些中后段层更新既可迁移,又是性能提升所必需的。
- 多种训练策略实验表明,在 RL 训练中冻结中段或后段层会大幅消除性能增益,证实 RL 的可靠贡献在于优化后期计算,而非早期视觉编码或独立推理。
引言
作者利用强化学习(RL)增强视觉语言模型(VLM)的视觉推理能力,基于广泛采用的两阶段流程:监督微调后接可验证奖励的 RL。尽管先前研究报告了基准提升,但尚不清楚 RL 是否改善视觉感知、推理或二者对齐——端到端指标掩盖了这些差异。作者的主要贡献是一种“弗兰肯斯坦式”分析框架,按 Transformer 层分解 VLM,通过因果探测、参数比较和模型合并隔离 RL 的功能影响。他们发现 RL 一致优化中后段层——而非早期视觉模块——从而提升视觉到推理的对齐与推理性能,且这些变化既可迁移又对增益必要。这挑战了“RL 均匀提升视觉能力”的假设,强调需超越聚合基准进行分析。
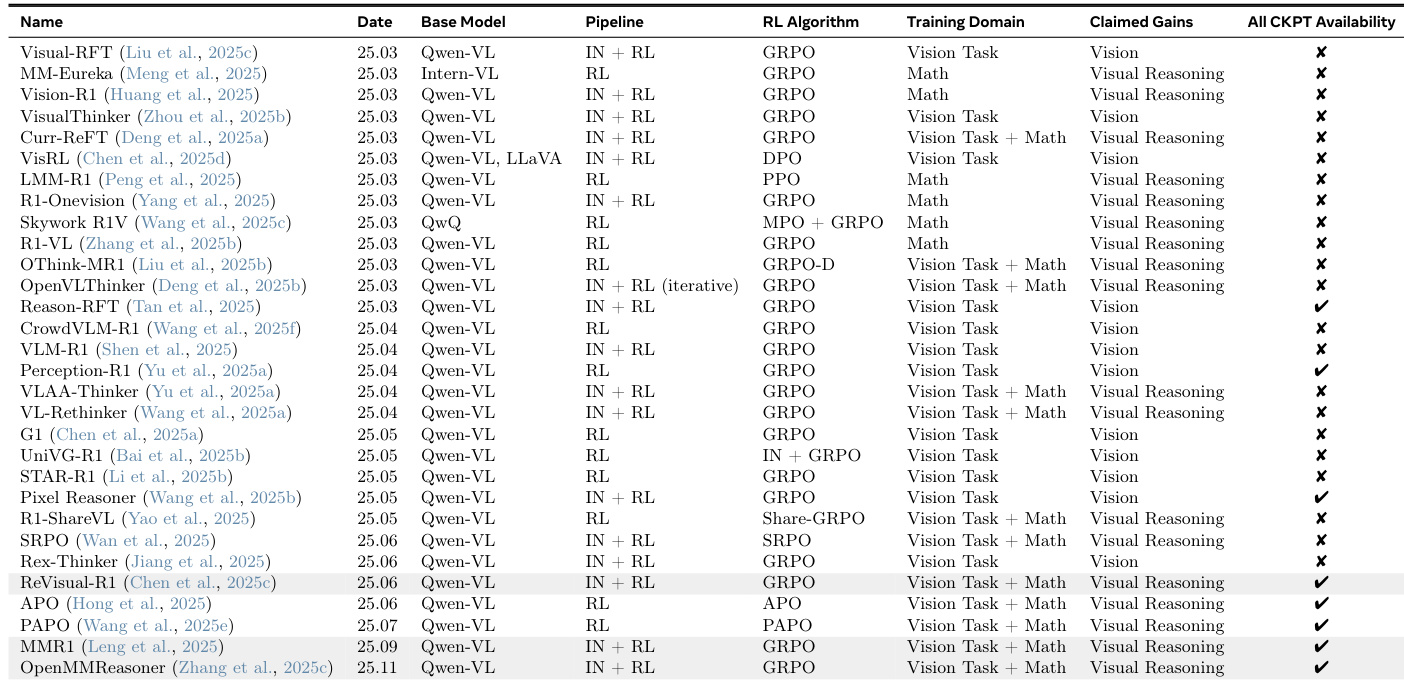
数据集
作者使用多组件数据集评估模型在视觉、推理及视觉到推理任务中的能力:
-
视觉(通用 VQA):使用 AI4Math/MathVista 的 testmini 分割,按 metadata['category'] = 'general-vqa' 过滤。测试广义视觉问答能力。
-
视觉到推理(数学 VQA):使用相同 AI4Math/MathVista testmini 分割,但按 metadata['category'] = 'math-targeted-vqa' 过滤。聚焦需推理的视觉数学问题。
-
推理(文本数学):使用 HuggingFaceH4/MATH-500 测试分割。评估无视觉输入的纯数学推理能力。
-
成对图像数据集(用于功能归因):通过构造仅在单一属性上不同的图像对,隔离特定视觉功能:
-
OCR:空白背景上文字不同的图像,采样自去重的 arXiv 语料库。查询要求文本内容;变化率通过文本输出差异衡量。
-
物体计数:改编自 CLEVR。图像对仅物体数量不同,外观与背景固定。变化率通过预测计数是否不同衡量。
-
物体定位:相同物体置于干净背景的不同位置。查询要求边界框;变化通过预测与交换后真值的 IoU < 0.5 衡量。
-
物体识别:COCO 图像与其目标物体配对空白画布。查询要求物体是否存在;变化率为 token 交换后“否”响应比例。
-
-
推理基准:GSM8k 和 MATH500 用于评估推理敏感性。这些纯文本基准要求多步推理与符号操作,隔离推理与感知。
本节未指定训练分割、混合比例或裁剪策略。元数据用于过滤(如类别标签),成对数据集为合成构造,以实现模型行为对特定视觉功能的因果归因。
方法
作者利用“弗兰肯斯坦式”分析框架,剖析强化学习(RL)如何在不同训练策略下一致修改视觉推理行为。该框架以 Transformer 层为粒度,围绕三个核心组件构建:通过因果探测进行功能定位、通过参数比较进行更新表征、通过模型合并测试迁移性。每个组件旨在隔离并验证 RL 对模型特定计算区域的一致影响。
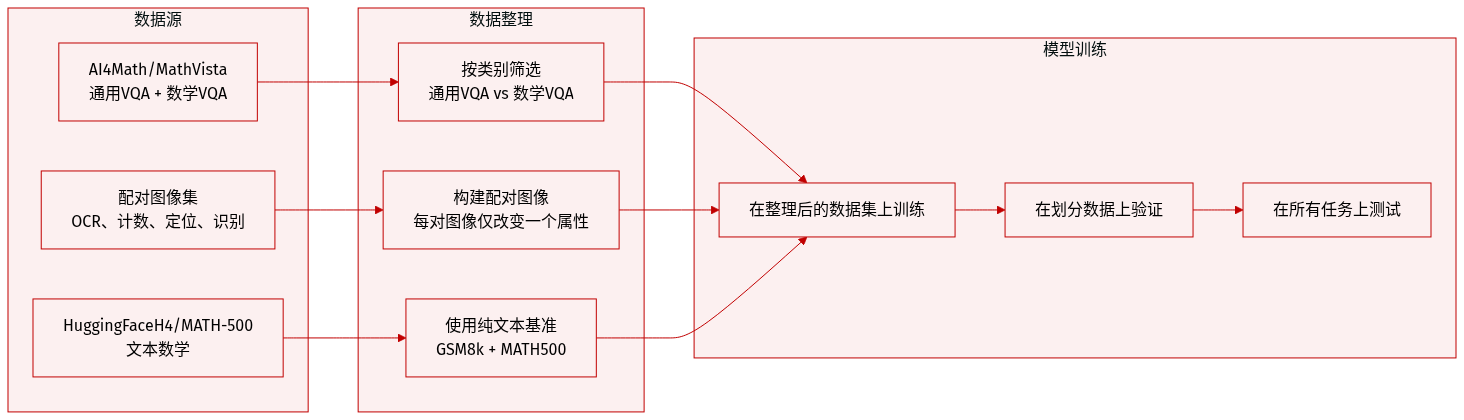
第一组件“功能定位”识别哪些 Transformer 层负责处理视觉信息,哪些参与高层推理。通过目标视觉标记干预策略实现:对于每对仅在单一视觉属性(如 OCR 任务中的文字或物体计数)上不同的图像,作者在特定层 ℓ 交换视觉标记表示,同时保留所有其他隐藏状态和提示。若模型预测因此改变,则该层被认定对该属性功能敏感。敏感性通过变化率量化:
Change Rate(ℓ)=N1n=1∑NI[f(in(ℓ),pn)=f(in′(ℓ),pn)],其中 f(⋅) 表示模型预测答案,pn 为提示,in(ℓ) 和 in′(ℓ) 分别表示视觉标记源自原始图像与配对图像的输入。此干预保留架构结构与数值稳定性,确保输出变化真实反映视觉证据处理的变化。如下图所示,该方法使作者能将识别、OCR、定位和计数等不同视觉任务映射到特定层区域。
基于这些干预,作者将 Transformer 划分为三个功能区域:早期、中期和后期层。早期层主要处理基础视觉识别,中期层参与更复杂的视觉任务(如 OCR 和物体计数),后期层关联依赖较少原始视觉输入、更多语言推理的任务。这种分层使作者能在 VLM 中解耦视觉与推理功能。
第二组件表征 RL 如何相对于初始训练(IN)修改各区域的参数更新。作者计算各层参数更新的 Frobenius 范数,观察到 IN 与 RL 均集中优化于中期层,但 RL 展现出不同的更新幅度再分配:RL 将更多能量分配给中期层,且在早期到后期层表现出更陡峭的秩谱,表明参数适应更具结构性与针对性。参见框架图以可视化比较 IN 与 RL 的更新能量与多样性。

第三组件通过合并 IN 训练与 RL 训练模型的层测试 RL 引发改进的可迁移性。作者通过组合不同训练策略的早期、中期和后期层构建混合模型并评估性能。结果表明,RL 在中期-后期层引发的改进可迁移并持续提升跨任务性能,验证 RL 系统性修改这些区域以提升视觉推理。框架图说明合并过程及相应性能增益。

这三个组件共同构成一套连贯方法,用于隔离、表征和验证 RL 在基于 Transformer 的 VLM 中对视觉推理的一致影响。该方法支持对训练动态如何重塑模型功能区域的细粒度分析,提供对 RL 驱动性能增益机制的洞察。
实验
- 细粒度分析揭示视觉推理基准掩盖了不一致的改进:从基础模型到 IN 再到 RL 模型,视觉与推理能力并未单调提升。
- RL 一致通过增加推理标记对视觉标记的注意力来改变推理行为,集中于中后段 Transformer 层。
- RL 在中后段层引发结构化参数更新,表现为集中、低多样性的优化,提升视觉到推理的对齐与推理能力。
- 模型合并证实这些中后段层优化可迁移,且足以在不同训练策略下保持对齐与推理的增益。
- 在 RL 训练中冻结中后段层会消除性能增益,确立这些区域的优化对 RL 改进具有因果必要性。
- 功能定位表明视觉处理锚定于早期-中期层,而推理计算集中于后期层,为解释 RL 效果提供参考框架。
作者使用模型合并隔离强化学习在 Transformer 各层的功能影响,揭示视觉到推理对齐与推理的改进主要源于中后段层的优化。这些增益可迁移,当将这些层的 RL 训练参数移植到其他模型时持续保留,而早期层贡献极小。结果表明 RL 并未均匀增强所有能力,其益处因果依赖于后期层的更新,而非整体模型规模或训练时长。
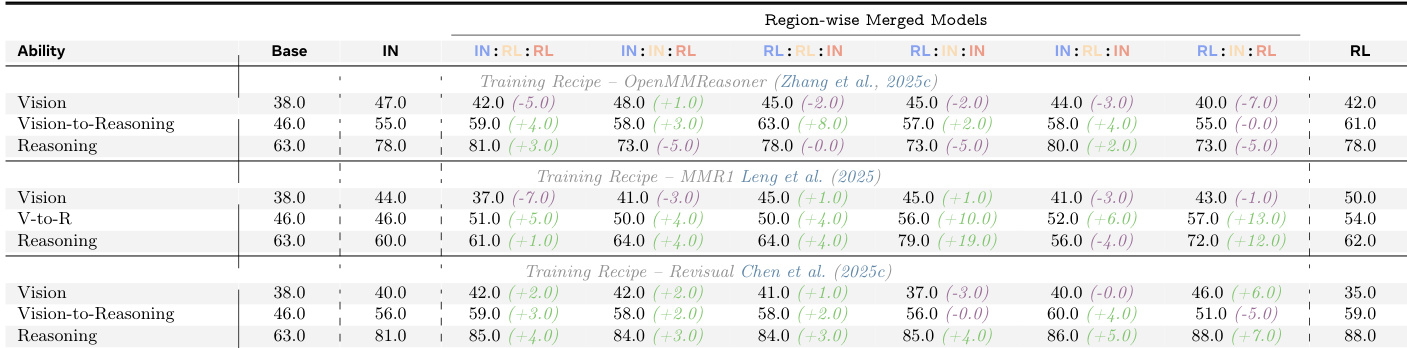
结果表明,尽管端到端基准分数随 RL 训练提升,细粒度分析揭示视觉或推理能力本身并无一致增益。相反,RL 通过优化中后段 Transformer 层持续提升视觉到推理对齐与推理性能,这些改进既可迁移又对整体增益因果必要。在 RL 训练中冻结后期层会消除大部分益处,确认其在介导 RL 引发改进中的关键作用。
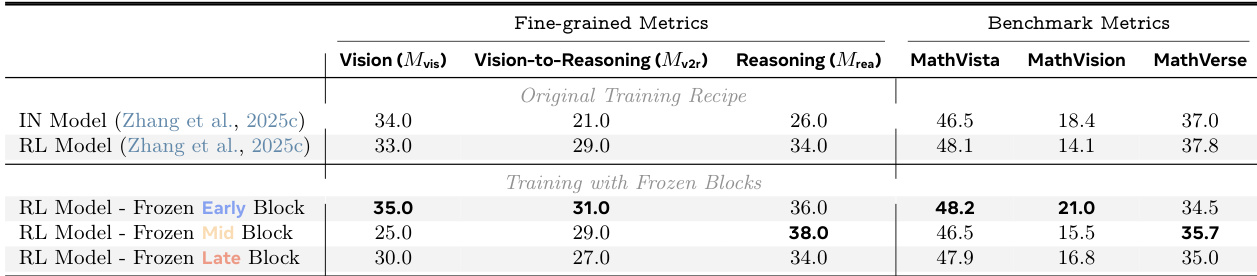
作者通过跨多种训练策略的系统分析表明,强化学习通过优化推理标记对视觉信息的关注方式(主要在中后段 Transformer 层)提升视觉推理,而非孤立增强视觉或推理能力。这些优化结构一致,可通过模型合并迁移,且对性能增益因果必要,表明 RL 优化的是视觉到推理的对齐,而非原始感知或语言能力。