Command Palette
Search for a command to run...
ABot-M0:基于动作流形学习的机器人操作视觉-语言-动作基础模型
ABot-M0:基于动作流形学习的机器人操作视觉-语言-动作基础模型
摘要
在多样化硬件平台上构建通用具身智能体(embodied agents)仍是机器人领域的核心挑战,通常被概括为“一脑多形”(one-brain, many-forms)范式。当前进展受限于数据碎片化、表征不一致以及训练目标错位等问题。本文提出ABot-M0框架,通过建立系统化的数据治理流程,协同优化模型架构与训练策略,实现从异构原始数据到统一、高效表征的端到端转换。基于六个公开数据集,我们对数据进行清洗、标准化与均衡化处理,构建了UniACT-dataset——一个包含超过600万条轨迹、累计9500小时数据的大型数据集,覆盖多种机器人形态与任务场景。统一的预训练显著提升了跨平台、跨任务的知识迁移能力与泛化性能,为通用具身智能的实现提供了坚实基础。为进一步提升动作预测的效率与稳定性,我们提出“动作流形假设”(Action Manifold Hypothesis):有效的机器人动作并非分布于高维全空间,而是位于由物理规律与任务约束所支配的低维、平滑流形上。基于此假设,我们引入动作流形学习(Action Manifold Learning, AML),采用DiT(Diffusion Transformer)作为骨干网络,直接预测清晰、连续的动作序列。该方法将学习过程从去噪转向对可行流形的投影,显著提升解码速度与策略稳定性。ABot-M0支持模块化感知,通过双流机制融合视觉语言模型(VLM)语义信息与几何先验,并接入即插即用的3D模块(如VGGT与Qwen-Image-Edit)提供的多视角输入,增强空间理解能力,同时无需修改主干网络,有效缓解了传统VLM在三维推理中的局限性。实验表明,各模块可独立运行并带来叠加性增益。我们承诺开源全部代码与数据处理流程,以支持研究的可复现性及未来研究发展。
一句话总结
AMAP CV 实验室团队推出了 ABot-M0,这是一个统一框架,通过动作流形学习和 UniACT 数据集,使不同机器人平台上的通用具身智能体实现高效运行;它将动作预测转移到低维流形上,整合模块化 3D 感知,并在不修改主干网络的前提下提升稳定性。
主要贡献
- ABot-M0 引入了一个统一框架,将异构机器人数据集标准化为 UniACT 数据集(600 万+轨迹,9500 小时),并联合优化架构与训练,实现跨具身泛化,无需定制硬件或专有数据。
- 它提出了动作流形假设与动作流形学习(AML),使用 DiT 主干网络直接在低维流形上预测干净、连续的动作,相比传统去噪方法,提升了解码速度与策略稳定性。
- 该框架通过即插即用模块(如 VGGT 和 Qwen-Image-Edit)将模块化 3D 感知集成到双流 VLM 架构中,在保持主干完整性的同时增强空间推理能力,并在 Libero、RoboCasa 和 RoboTwin 基准上取得最先进成果。
引言
作者利用统一框架应对构建跨多种硬件平台通用机器人智能体的挑战,这是具身人工智能的核心目标。先前方法受限于碎片化数据集、不一致的表示和训练对齐问题,限制了跨平台泛化能力。其主要贡献是 ABot-M0,它结合大规模整理数据集(UniACT,600 万+轨迹)与新颖的动作流形学习模块,将动作预测为平滑的低维序列——相比传统去噪方法,提升了效率与稳定性。他们还引入了双流感知系统,将 VLM 语义与即插即用 3D 模块集成,增强空间推理能力而不修改主干网络。实验表明,在多个基准测试中达到最先进性能,证明高质量具身智能可从系统化构建的公共资源中涌现。
数据集
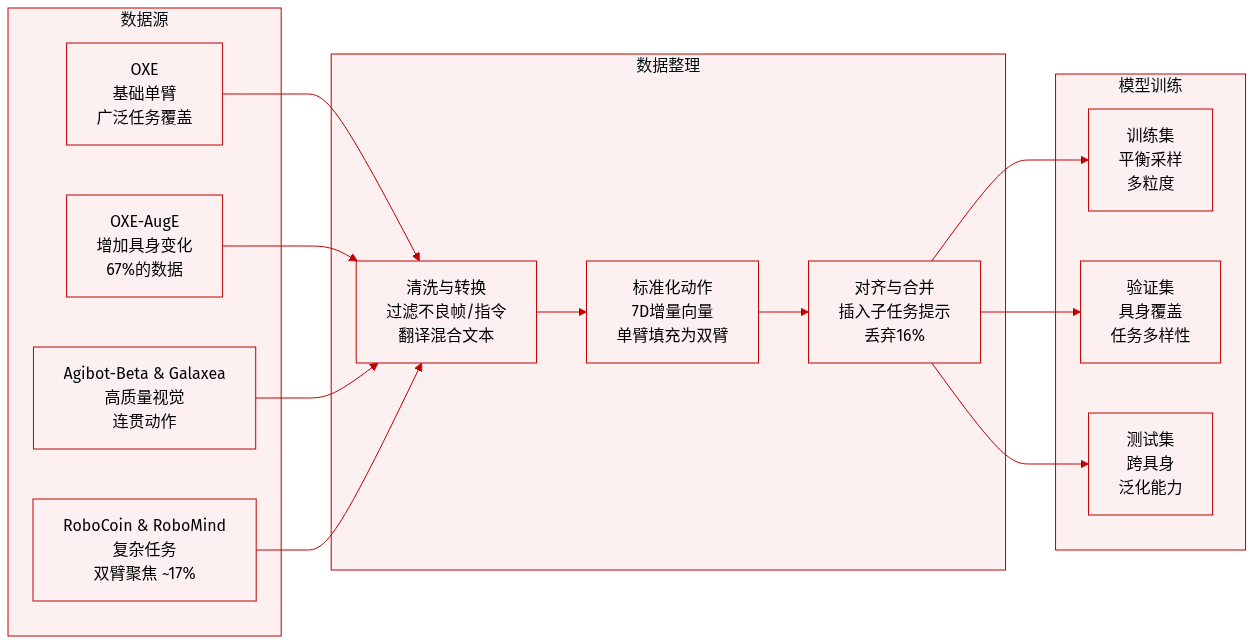
作者使用一个整理过的大型数据集 UniACT-dataset 来训练通用视觉-语言-动作(VLA)模型,以支持具身智能。以下是其构建与使用方式:
-
数据集组成与来源:
整合六个开源数据集:OXE、OXE-AugE、Agibot-Beta、RoboCoin、RoboMind 和 Galaxea。这些数据集合计提供超过 700 万原始轨迹,涵盖多样化的机器人具身形态、任务类型和视觉条件。最终清洗后的数据集包含超过 600 万轨迹,跨越 9500+ 小时和 20+ 种独特机器人形态。 -
关键子集详情:
- OXE:作为基础单臂数据集,涵盖广泛任务。
- OXE-AugE:在单臂设置内增强具身形态变化;贡献总数据量的 67%。
- Agibot-Beta 与 Galaxea:提供高质量视觉观测和连贯动作序列;Agibot-Beta 经下采样以减少具身形态偏差。
- RoboCoin 与 RoboMind:优先用于复杂任务规划与跨具身泛化(双臂);合计贡献约 17.2%。
- 所有数据集均清洗并转换为 LeRobot v2 格式以保证一致性。
-
清洗与过滤规则:
- 移除指令为空、乱码或非英文的轨迹;翻译混合语言提示。
- 舍弃视觉退化帧(全黑、模糊、遮挡)或无效相机视角。
- 过滤异常轨迹(长度错误、动作差值过大、帧率不匹配)。
- 拒绝模糊或不完整的动作标注(如缺失维度、旋转格式不明确)。
- 通过插入帧对齐的细粒度指导解决子任务级指令对齐问题。
- 清洗过程中约 16% 的轨迹被丢弃;其余轨迹经精修后合并。
-
标准化与处理:
- 所有动作标准化为每臂 7D 增量向量:[Δx, Δy, Δz, 旋转向量, 夹爪]。旋转向量(轴角)替代欧拉角/四元数以提高稳定性。
- 单臂数据填充至双臂格式(未使用臂设为零),实现统一训练。
- 模型始终输出双臂动作,但执行时仅激活相关通道。
- 训练采用多粒度均匀采样,以平衡具身覆盖与技能学习,尽管数据存在不平衡。
-
在模型训练中的应用:
清洗并标准化的 UniACT-dataset 被划分为训练、验证与测试集。模型在该混合数据集上端到端训练,采样策略确保跨具身形态与任务类型的均衡暴露。该数据集的规模、质量与多样性共同支持跨具身泛化与精确的视觉-语言-动作对齐。
方法
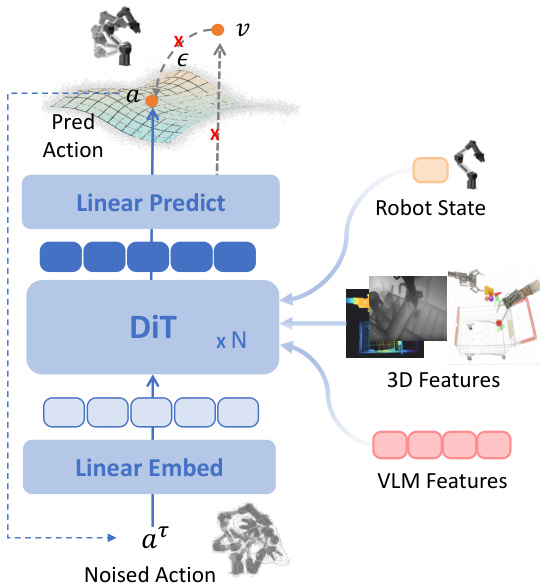
作者为 ABot-M0 模型设计了一个双组件架构,旨在将多模态感知直接映射为机器人动作生成。框架将视觉-语言理解与动作生成分别分离为视觉语言模型(VLM)与动作专家。VLM 使用 Qwen3-VL 实现,处理多视角图像序列(通常来自正面、腕部和俯视摄像头)及自然语言指令。这些模态独立分词后融合为统一标记序列,以支持跨模态推理。VLM 输出空间对齐的多模态表示,作为动作专家进行动作预测的上下文输入。
参考框架图,该图展示了从数据预处理经两阶段训练到动作生成的端到端流程。模型输入多视角图像与文本,通过预训练 VLM 处理,并将结果特征(可选增强 3D 空间信息)路由至动作专家。动作专家基于 Diffusion Transformer(DiT)构建,直接预测去噪后的动作块而非速度或噪声,符合动作流形假设。该设计使模型专注于学习有意义动作序列的内在结构——假设其位于低维流形上,而非回归高维、流形外目标。

动作专家在流匹配范式下运行,但直接预测去噪动作块 A^t,给定噪声动作 Atτ、机器人状态 qt 以及来自 VLM 和可选 3D 模块的上下文特征 ϕt:
A^t=Vtheta(phit,Attau,qt).尽管模型预测动作,训练损失仍基于速度计算以提升性能。估计与真实速度推导如下:
beginarrayrhatv=(hatAt−Attau)/(1−tau),v=(At−Attau)/(1−tau)endarray损失函数为加权均方误差,等价于重加权动作损失:
mathcalL(theta)=mathbbE∣vmathrmpred−vmathrmtarget∣2=mathbbEleft[w(tau)∣Vtheta(phit,Attau,qt)−At∣2right],其中 w(tau)=frac1(1−tau)2。该权重动态调整不同噪声水平的学习信号强度,当 τ 趋近 1 时强调细粒度优化。
推理阶段,模型遵循基于 ODE 的轨迹生成动作。从纯噪声 At0simmathcalN(0,mathbfI) 开始,通过预测速度 v^ 迭代去噪动作,并通过数值积分更新状态:
Attau+Deltatau=Attau+Deltataucdothatv.该方法保留流模型的平滑轨迹生成特性,同时在模型层面实现直接动作预测。
训练过程遵循两阶段范式。第一阶段在 UniACT 数据集上进行大规模预训练,该数据集包含 20+ 种具身形态的 600 万+轨迹。动作表示为末端执行器坐标系下的增量动作,单臂为 R7,双臂为 R14。填充至双臂策略确保跨具身形态参数共享,双加权采样策略平衡任务与具身形态分布以缓解长尾偏差。
第二阶段引入监督微调(SFT),注入 3D 空间先验以支持高精度任务。VLM 与动作专家联合微调,使用小学习率、Dropout 和动作噪声扰动以增强鲁棒性。该阶段保留泛化能力,同时提升对插入或双手协调等需要度量空间推理任务的性能。
为增强空间推理能力,作者引入模块化 3D 信息注入模块,与 VLM 协同运行。它整合前馈单图像 3D 特征(通过 VGGT)和隐式多视角特征(通过 Qwen-Image-Edit),以几何先验丰富 VLM 的语义特征。如下图所示,这些 3D 特征通过交叉注意力与 VLM 最后一层特征融合,再传递给动作专家。该融合策略协调语义与几何流,实现精确且空间锚定的动作生成。
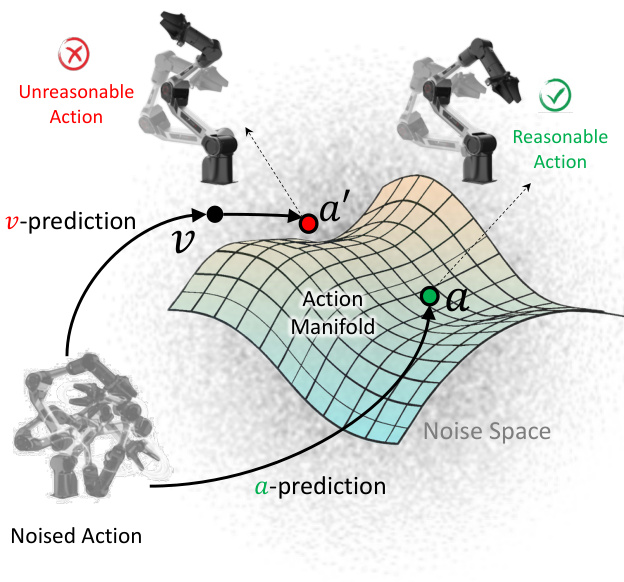
动作流形假设支撑动作专家的设计。如下图所示,传统速度预测(v-pred)可能因投影到低维动作流形外而导致不合理动作。相比之下,直接动作预测(a-pred)约束模型学习位于流形上的有意义、连贯动作序列,减轻学习负担并提升动作质量。
实验
- 任务均匀采样优于轨迹均匀与具身均匀策略,通过平衡具身覆盖与技能多样性,实现更强的跨具身、跨数据集与下游任务泛化能力。
- 使用任务均匀采样预训练可减少冗余并增强对稀有技能与具身形态的暴露,提升整体模型鲁棒性,无需严格具身级平衡。
- 预训练于机器人数据的 VLM 最后一层特征对动作预测最有效——优于中间层、多层拼接及动作查询增强,表明其内部已充分对齐动作语义。
- 动作流形学习(AML)直接预测动作而非噪声,在不同去噪步数与动作块大小下始终优于噪声预测范式,尤其在高维或长时域条件下表现更佳。
- 通过交叉注意力注入 3D 空间特征,在 LIBERO 与 LIBERO-Plus 上均提升性能,多视角合成进一步增强对相机视角扰动的鲁棒性。
- ABot-M0 在多个基准测试(LIBERO、LIBERO-Plus、RoboCasa、RoboTwin2.0)上取得最先进结果,展现强大泛化能力、对扰动的鲁棒性及扩展至复杂高维操作任务的潜力。
作者在预训练阶段采用任务均匀采样策略,以平衡具身形态多样性与技能覆盖,相比轨迹或具身均匀方法,实现更强的跨具身与跨数据集泛化。结果表明,该策略减少技能采样冗余,同时提升对稀有具身形态的暴露,转化为多个基准测试上的更好下游性能。基于此基础构建的 ABot-M0 模型,在单臂与多臂操作任务中持续优于先前方法,展现卓越的泛化与鲁棒性。
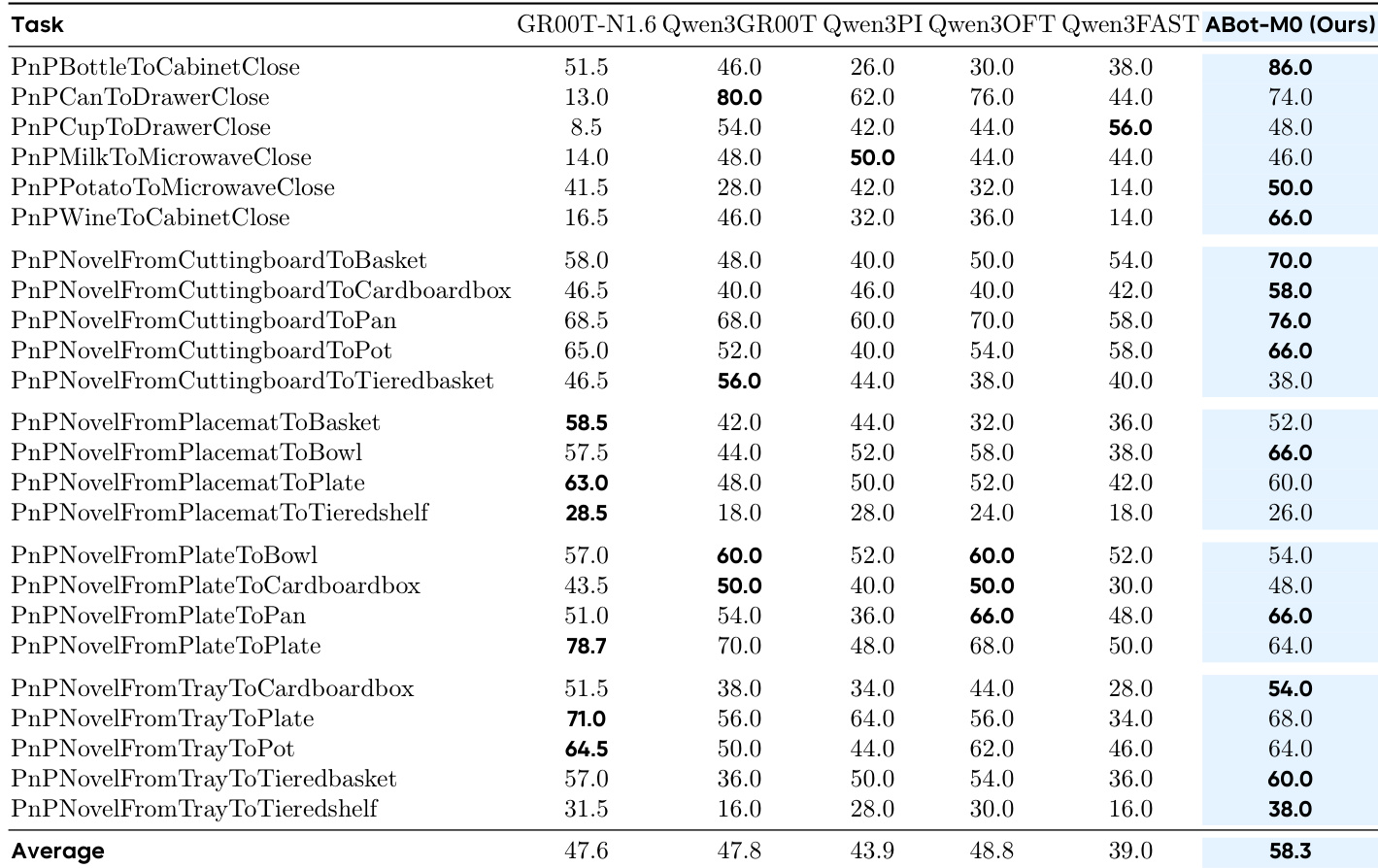
作者使用 ABot-M0 评估在 LIBERO-Plus 基准中,不同动作块大小与去噪步数在扰动下对性能的影响。结果表明,ABot-M0 在大多数扰动维度上持续优于 Qwen3-VL-GR00T,尤其在较小块大小时表现更佳,且在块大小增加时仍保持鲁棒性,而 GR00T 性能急剧下降。这支持了直接动作预测在不同条件下处理高维动作空间的有效性。
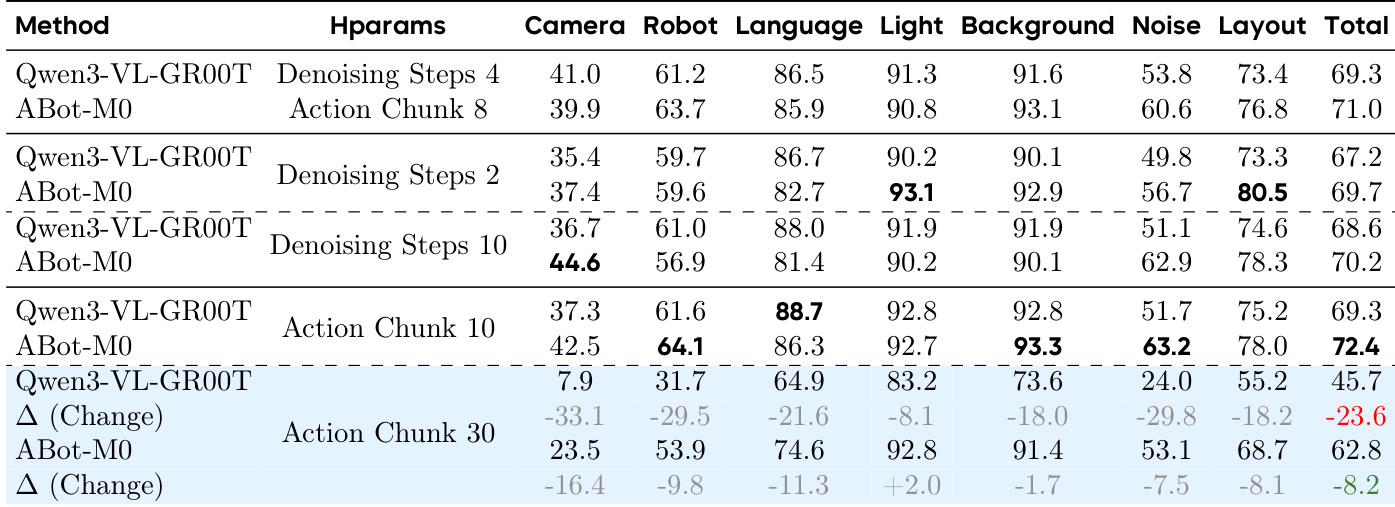
作者评估不同 VLM 特征层与查询机制在机器人预训练后对动作预测性能的影响。结果表明,使用无动作查询的最终层特征始终获得最高成功率,表明深层表示已编码足够的动作相关语义。引入中间层或动作查询未提升性能,甚至可能降低,表明预训练模型内部结构已最优对齐动作空间,无需额外适配。
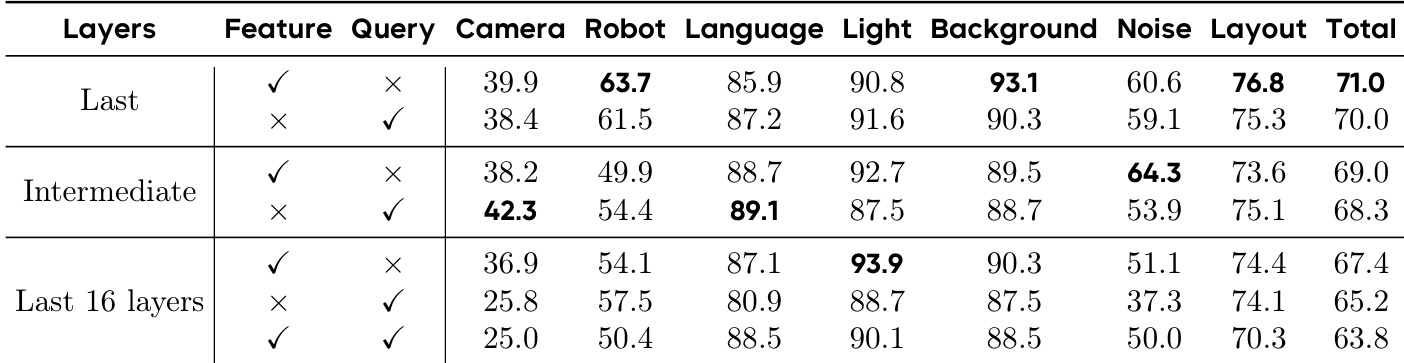
作者使用三种采样策略——轨迹均匀、具身均匀与任务均匀——在多具身机器人数据集上预训练模型,并在 Libero Plus 上评估下游性能。结果表明,任务均匀采样获得最高整体成功率,表明其在训练中更好地平衡具身形态多样性与技能覆盖。该策略在跨具身泛化与下游任务适应中始终优于其他方法。

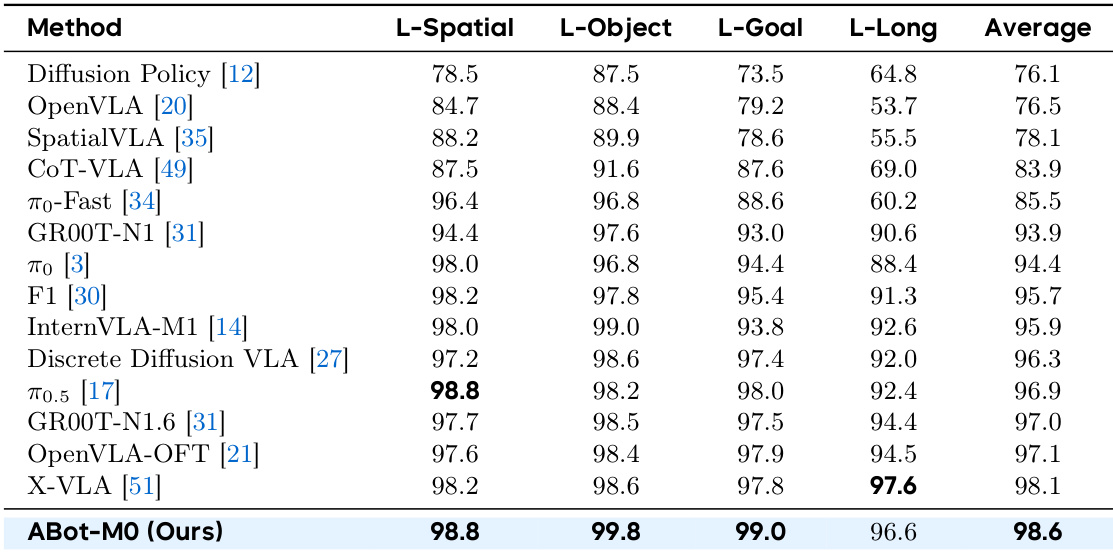
作者使用跨多个套件训练的统一模型评估 LIBERO 基准性能,在所有任务类别中取得最先进成功率。结果表明,相比先前方法持续优越,尤其在长时域与目标条件任务中,体现强大的空间推理与多步规划能力。模型的高平均性能反映其在无需任务特定调优情况下,对多样化操作场景的稳健泛化能力。