HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

Triton-distributed:使用 Triton 编译器在分布式 AI 系统中编程重叠内核
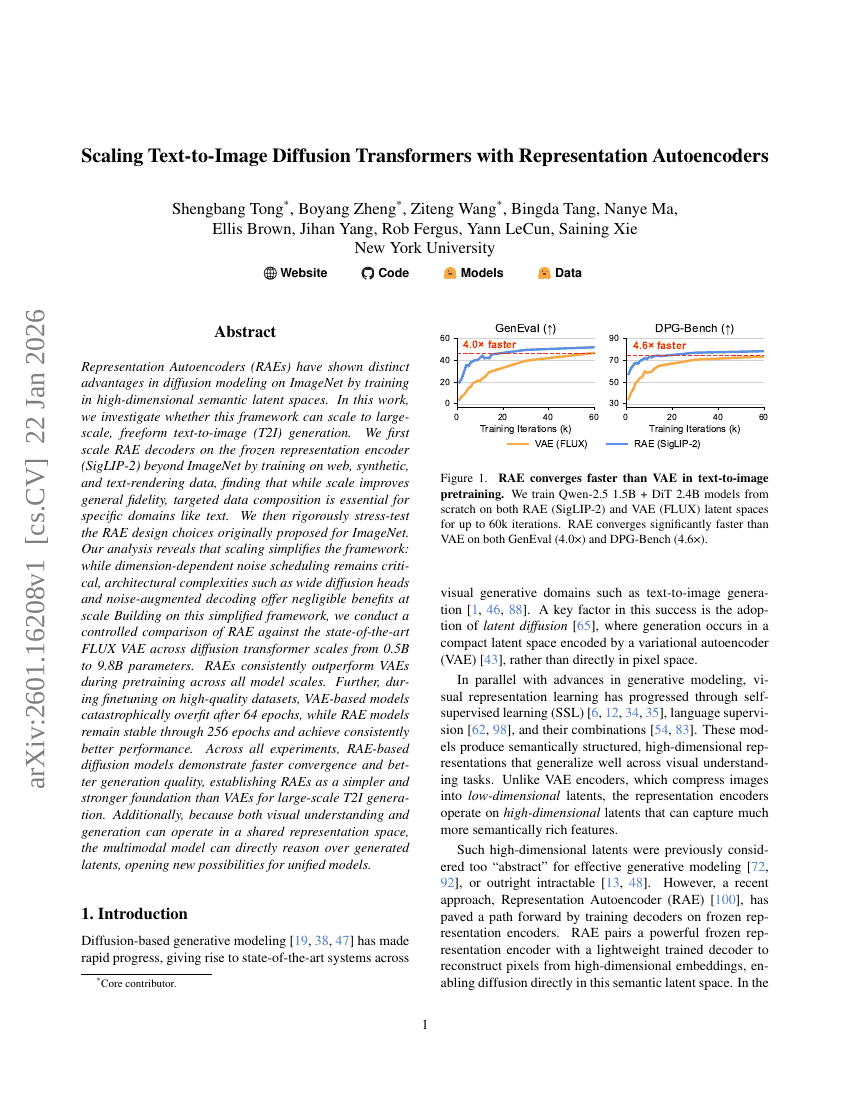
基于表征自编码器的文本到图像扩散Transformer的扩展

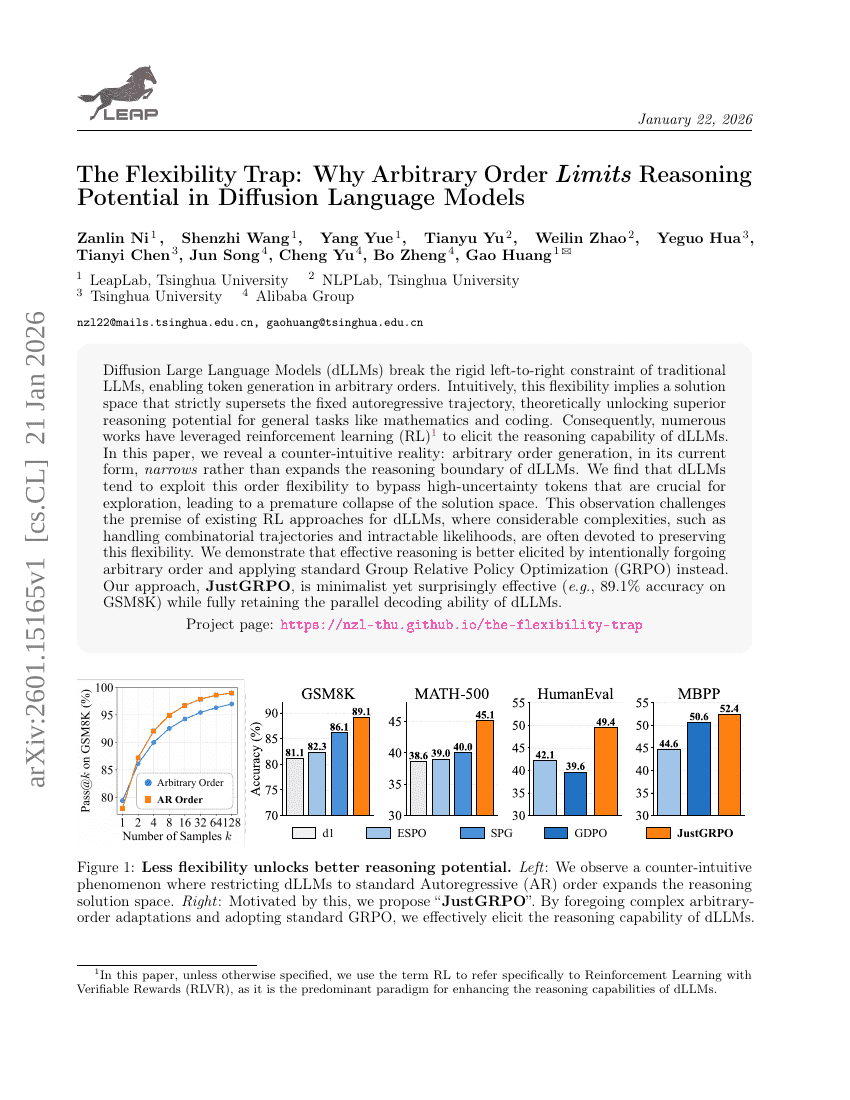
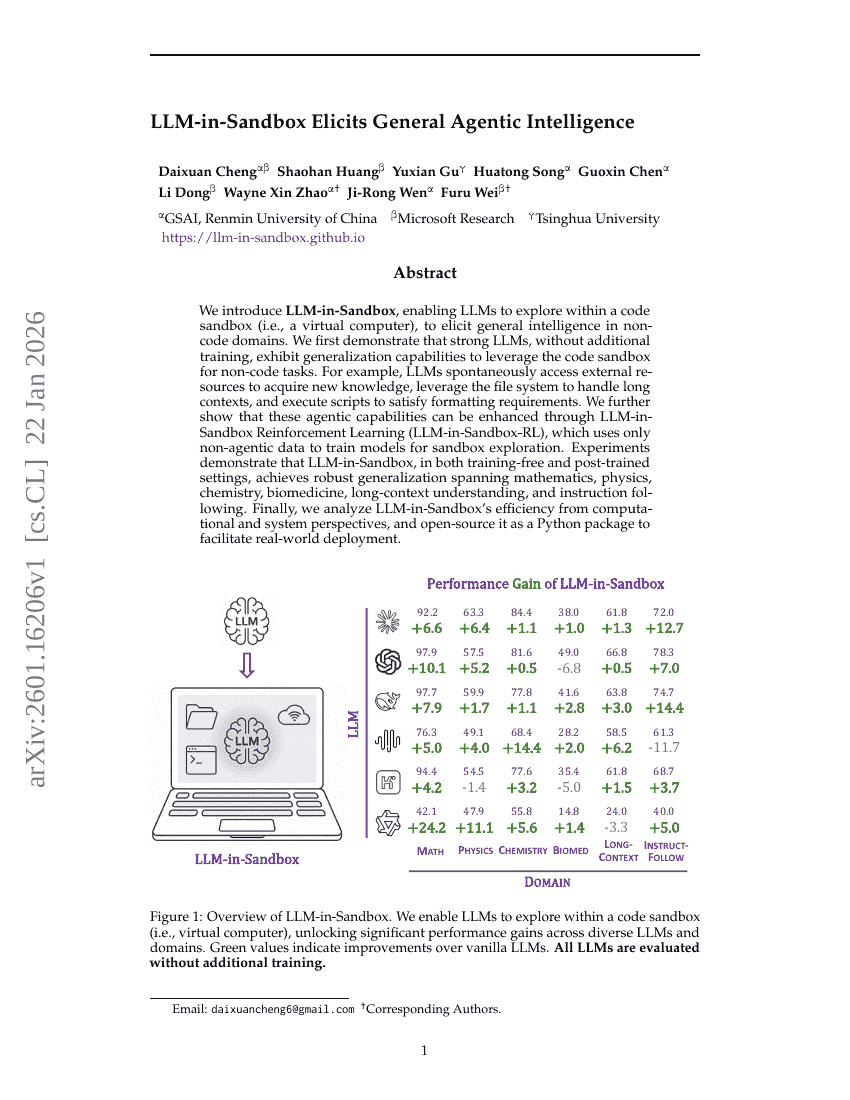


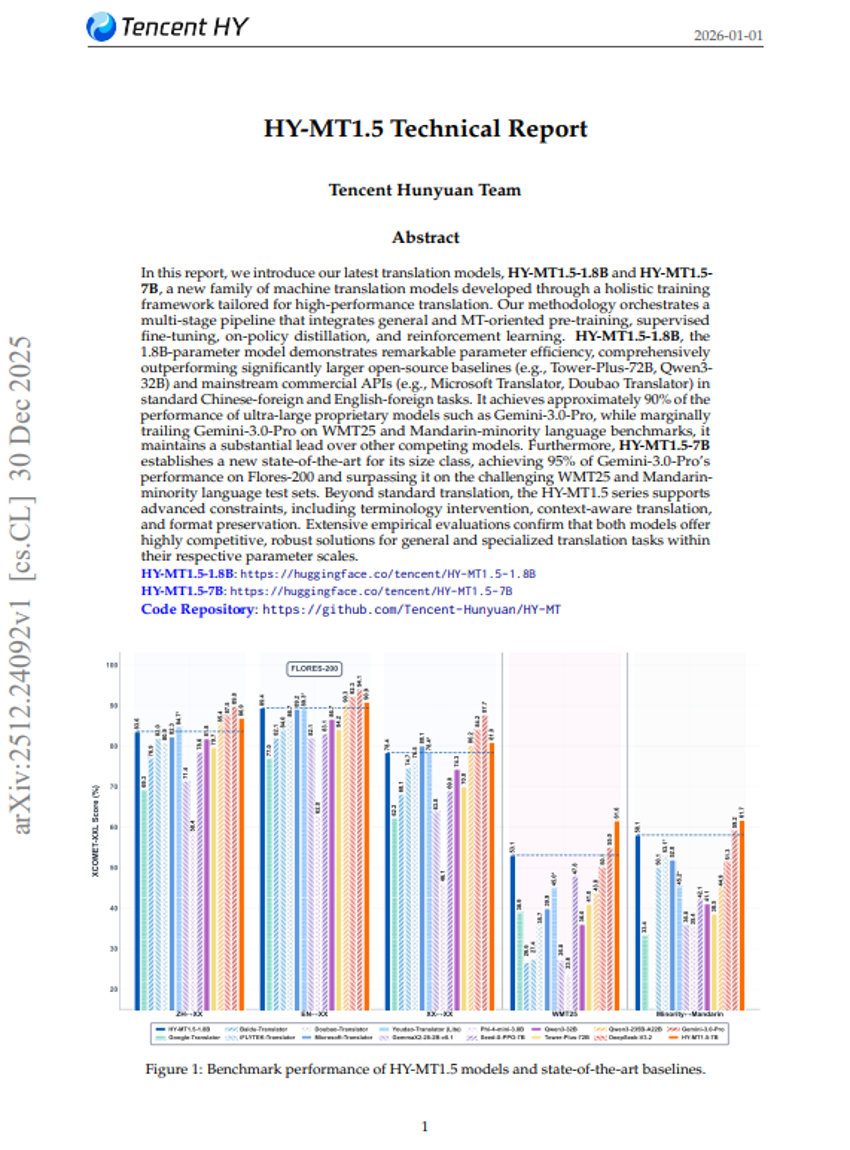























Triton-distributed:使用 Triton 编译器在分布式 AI 系统中编程重叠内核
基于表征自编码器的文本到图像扩散Transformer的扩展
BayesianVLA:通过潜在动作查询对视觉-语言-动作模型进行贝叶斯分解
灵活性陷阱:为何任意顺序限制制约了扩散语言模型的推理潜力
沙箱中的LLM激发通用代理智能
HERMES:将KV缓存作为分层内存以实现高效的流式视频理解
EvoCUA:通过从可扩展的合成经验中学习来演化计算机使用代理
HY-MT1.5 技术报告
代码的缩放定律:每种编程语言都至关重要
Qwen3_TTS 技术报告
小模型,大成果:通过分解实现卓越的意图抽取
FinVault:面向执行基础环境的金融Agent安全基准测试
MMDeepResearch-Bench:多模态深度研究Agent基准测试
DARC:面向LLM演化的解耦非对称推理课程
面向具身世界的视频生成模型再思考
Paper2Rebuttal:一种用于透明化作者回复辅助的多智能体框架
LLM的智能体推理
PERSONAPLEX:用于全双工对话语音模型的语音与角色控制
FlashLabs Chroma 1.0:具备个性化语音克隆能力的实时端到端语音对话模型
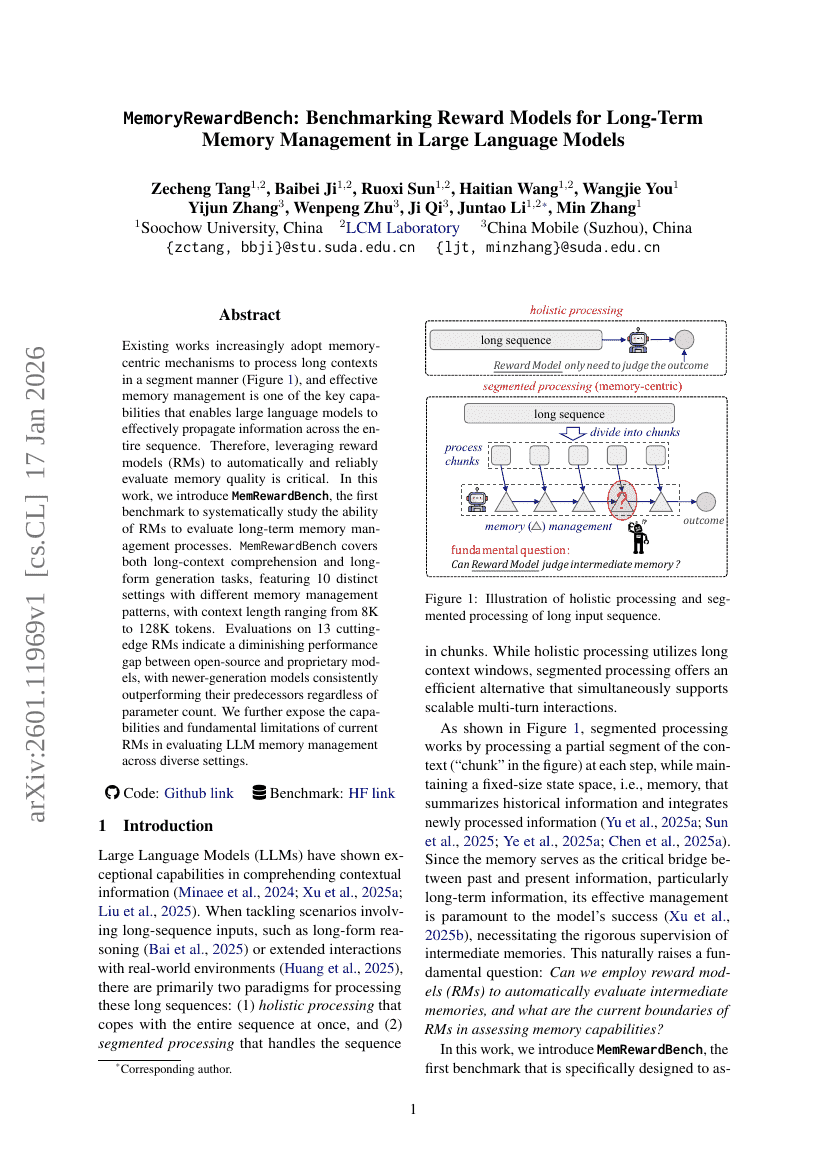
MemoryRewardBench:面向大型语言模型长期记忆管理的奖励模型基准测试
OmniTransfer:面向时空视频迁移的统一框架
面向高效智能体:记忆、工具学习与规划
FutureOmni:基于多模态上下文的未来预测评估方法在多模态LLM中的应用
Being-H0.5:面向跨体感泛化的以人为本机器人学习扩展
基于LLM的软件工程问题求解进展与前沿:一项综合调查
Nemotron-Math:基于多模态监督的高效长 Context 数学推理能力蒸馏
为Gemini构建可投入生产的探测器
LFM2 技术报告
CoDance:一种用于鲁棒多主体动画的解绑-重绑范式
助手轴:语言模型默认人格的定位与稳定化
ABC-Bench:面向真实世界开发中的智能体后端编码基准测试
多路思维:通过逐token分支与合并进行推理
BayesianVLA:通过潜在动作查询对视觉-语言-动作模型进行贝叶斯分解
灵活性陷阱:为何任意顺序限制制约了扩散语言模型的推理潜力
沙箱中的LLM激发通用代理智能
HERMES:将KV缓存作为分层内存以实现高效的流式视频理解
EvoCUA:通过从可扩展的合成经验中学习来演化计算机使用代理
HY-MT1.5 技术报告
代码的缩放定律:每种编程语言都至关重要
Qwen3_TTS 技术报告
小模型,大成果:通过分解实现卓越的意图抽取
FinVault:面向执行基础环境的金融Agent安全基准测试
MMDeepResearch-Bench:多模态深度研究Agent基准测试
DARC:面向LLM演化的解耦非对称推理课程
面向具身世界的视频生成模型再思考
Paper2Rebuttal:一种用于透明化作者回复辅助的多智能体框架
LLM的智能体推理
PERSONAPLEX:用于全双工对话语音模型的语音与角色控制
FlashLabs Chroma 1.0:具备个性化语音克隆能力的实时端到端语音对话模型
MemoryRewardBench:面向大型语言模型长期记忆管理的奖励模型基准测试
OmniTransfer:面向时空视频迁移的统一框架
面向高效智能体:记忆、工具学习与规划
FutureOmni:基于多模态上下文的未来预测评估方法在多模态LLM中的应用
Being-H0.5:面向跨体感泛化的以人为本机器人学习扩展
基于LLM的软件工程问题求解进展与前沿:一项综合调查
Nemotron-Math:基于多模态监督的高效长 Context 数学推理能力蒸馏
为Gemini构建可投入生产的探测器
LFM2 技术报告
CoDance:一种用于鲁棒多主体动画的解绑-重绑范式
助手轴:语言模型默认人格的定位与稳定化
ABC-Bench:面向真实世界开发中的智能体后端编码基准测试
多路思维:通过逐token分支与合并进行推理