Command Palette
Search for a command to run...
MosaicMem:用于可控视频世界模型的混合空间记忆机制
MosaicMem:用于可控视频世界模型的混合空间记忆机制
摘要
视频扩散模型正从生成简短且合理的片段,迈向能够应对相机运动、场景回溯及干预操作的世界模拟器。然而,空间记忆仍是关键瓶颈:显式三维结构虽能提升基于重投影的一致性,却难以刻画移动物体;而隐式记忆即便在相机姿态准确的情况下,也常导致相机运动轨迹失真。为此,我们提出 Mosaic Memory(MosaicMem),一种混合式空间记忆机制。该机制将图像块(patches)提升至三维空间以实现可靠的定位与定向检索,同时利用模型原生的条件生成能力,确保对提示词(prompt)的遵循。MosaicMem 通过“分块与组合”(patch-and-compose)接口,在查询视图中合成空间对齐的图像块,在保留应持久化内容的同时,允许模型对需演化的部分进行修复(inpainting)。结合 PRoPE 相机条件机制与两种新型记忆对齐方法,实验结果表明:相较于隐式记忆,MosaicMem 在姿态遵循方面表现更优;相较于显式基线,其动态建模能力显著增强。此外,MosaicMem 还支持分钟级导航、基于记忆的 scene 编辑以及自回归 rollout。
一句话总结
来自多伦多大学、佐治亚理工学院和大阪大学的研究人员提出了 MosaicMem,这是一种混合空间记忆机制,它将图像块提升至 3D 以实现精确定位,同时利用隐式条件处理动态演化,从而在可控的视频世界模型中实现分钟级的导航和场景编辑。
主要贡献
- 本文介绍了 MosaicMem,这是一种混合空间记忆机制,它将图像块提升至 3D 以实现精确定位和定向检索,同时利用模型的原生条件处理动态场景变化。
- 该工作引入 PROPE 作为相机条件接口,实现了相机控制的视频生成,显著提升了视角可控性和姿态遵循度。
- 实验表明,该方法在动态建模方面比显式基线更稳健,在运动一致性方面比隐式记忆更准确,并得到了一个专为测试复杂重访场景下检索能力的新基准的支持。
引言
视频扩散模型正演变为能够进行长视野规划和交互式探索的世界模拟器,但其有效性目前受限于不足的空间记忆系统。先前的显式方法依赖于僵化的 3D 结构,难以表示移动物体;而隐式方法将状态存储在潜在表示中,却常受相机漂移和低效上下文利用的困扰。为了解决这些权衡,作者提出了 MosaicMem,这是一种混合空间记忆机制,它将图像块提升至 3D 以实现精确定位,同时保留模型的原生条件以处理动态变化。这种“块与组合”接口实现了可靠的检索和定向修复,从而在分钟级导航和场景编辑中实现了卓越的姿态遵循度和稳健的动态建模。
数据集
-
数据集构成与来源:作者推出了 MosaicMem-World,这是一个基准数据集,聚合了四个互补来源的数据,以解决标准第一人称视频数据集中缺乏显式重访的问题。这些来源包括:用于解耦控制和长距离检索的精选 Unreal Engine 5 场景、用于复杂动态的商业游戏环境(如《赛博朋克 2077》)、用于真实外观变化的真实世界第一人称捕捉数据,以及基于高重访频率从现有 Sekai 数据集中精选的序列。
-
各子集的关键细节:每个来源贡献了数十小时的影像数据。Unreal Engine 5 子集包含具有单一和混合动作的轨迹以及显式的重访片段。商业游戏子集捕捉了密集交互,而真实世界子集引入了噪声和光照变化。Sekai 子集则根据相机轨迹专门筛选出重访频率最高的序列。
-
模型使用与训练策略:该数据集支持针对视角变化下的空间记忆的训练和评估。作者利用该数据评估模型在保持场景结构稳定性、在大幅相机运动后重新定位以及重用存储几何结构方面的能力。为了实现组合式训练,作者将连续片段上的动态描述连接起来,构建任意长度的训练片段。
-
处理与标注流程:作者应用了统一的预处理流程,利用 Depth Anything V3 或 VIPE 重建深度和相机运动,以创建一致的几何骨架。视频被划分为固定长度(32 帧)的片段,其中 Gemini 3 为每个片段生成两个互补的文本描述:一个用于静态场景内容,另一个用于时间动态。最后,数据集经过过滤,移除了 3D 估计不准确或运动模糊过度的视频。
方法
作者将任务形式化为:在输入图像 I、文本提示 L 和相机姿态 C 的条件下,生成长视野视频 rollout X。他们基于文本 + 图像到视频(TI2V)模型,通过流匹配(Flow Matching)学习整个视频的联合分布。生成过程遵循概率流 ODE,其中神经向量场 uθ 将高斯噪声 X0 传输到目标视频状态 X1:
dλdXλ=uθ(Xλ,λ∣I,L,C,M),X1=X0+∫Λ1uθ(Xλ,λ∣I,L,C,M) dλ其中 M 表示空间记忆。为了解决现有空间记忆范式的局限性,作者提出了 Mosaic Memory,这是一种超越显式和隐式方法之间权衡的混合设计。
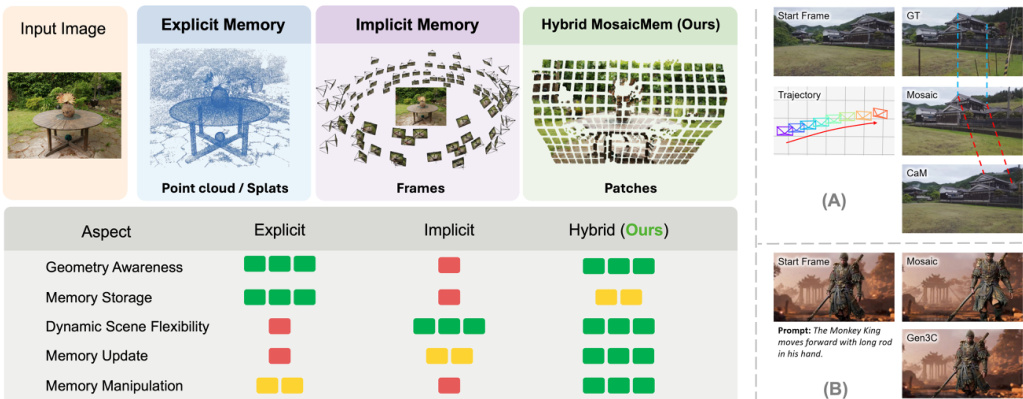
如比较图所示,显式方法将场景证据存储为点或泼溅(splats)等 3D 原语,而隐式方法则以整个视频帧的粒度保留记忆。Mosaic Memory 利用图像块作为记忆的基本单元,整合了两者互补的优势。对于给定的块 P,作者首先执行类似于显式记忆流程的几何提升步骤,利用现成的 3D 估计器推断深度并将块提升至 3D。当观察者移动到新的视角时,检索到的块将作为上下文提供给 DiT,类似于隐式记忆条件。一种改进的 RoPE 机制传达了该记忆块与查询相机下的噪声潜在令牌之间的对应关系。这种有机的组合使得生成器能够灵活地决定是依赖空间记忆进行一致重建,还是根据文本提示合成未见过的内容和新的动态。
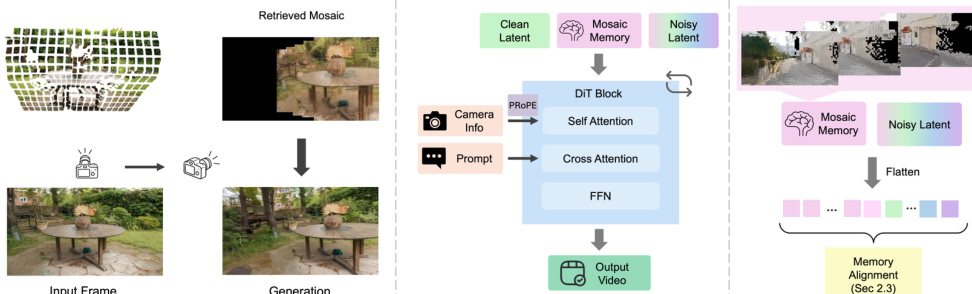
流程概览展示了检索到的马赛克块如何被展平并连接到令牌序列中作为条件。为了在检索到的记忆块与当前视图之间建立几何一致的对应关系,作者利用两种扭曲机制改进了对齐。扭曲 RoPE(Warped RoPE)是一种新的位置编码机制,它在潜在空间中跨时间和相机运动对齐块。每个检索到的记忆块 P 都与深度 D 以及相机内参/外参相关联。给定其原始 RoPE 坐标 (u,v),该块被反投影到 3D 世界空间,并重新投影到目标相机以确定新坐标 (u′,v′):
(u′,v′)=Π(KjTjTi−1Ki−1(u,v,D)),其中 Π(⋅) 表示透视投影。或者,扭曲潜在(Warped Latent)提供了一种互补的对齐机制,它通过重新投影坐标在特征空间中直接对检索到的记忆块进行空间重采样变换。
尽管 Mosaic Memory 隐式地提供了一些相机运动线索,但为了实现可靠的轨迹控制,作者引入了专用的相机控制模块。作者采用投影位置编码(PROPE)作为基于 DiT 的视频生成的原则性相机条件接口。PROPE 通过投影变换编码两个视图之间的完整相对关系,并通过变换注意力应用该关系。给定每帧的相机投影矩阵 P~i,该模块将相对相机视锥几何直接注入自注意力中。由于 3D VAE 的时间压缩,作者展开一个额外的子索引,以确保每个时间压缩的潜在帧都能以正确的每帧投影条件进行注意力计算,同时在注意力算子层面保持 PROPE 接口不变。
实验
- 空间记忆对比表明,MosaicMem 通过实现动态场景演化、精确的相机控制以及对长视野下先前观察到的物体的忠实重建,优于显式和隐式基线。
- 消融研究证实,与使用单个组件或更简单的控制方法相比,将 PROPE 与双重扭曲机制相结合显著提高了相机运动精度和记忆检索的鲁棒性。
- 长视野生成实验验证了该方法能够生成具有空间一致对齐的分钟级导航视频,而基线模型则遭受累积伪影和生成崩溃的困扰。
- 记忆操纵测试表明,编辑存储的时空块可以实现无缝的场景拼接和超现实的空间排列,使用户能够在不同的环境之间切换。
- 自回归生成评估证明,Mosaic Forcing 变体在实现实时性能的同时,具有卓越的视觉质量和时间一致性,有效解决了单策略模型中发现的边界重生成问题。