Command Palette
Search for a command to run...
DreamVideo-Omni:基于潜在身份强化学习的 Omni-Motion 控制多主体视频定制
DreamVideo-Omni:基于潜在身份强化学习的 Omni-Motion 控制多主体视频定制
摘要
尽管大规模扩散模型已彻底变革了视频合成领域,但在同时实现多主体身份精确控制与多粒度运动操控方面,仍面临严峻挑战。近期相关研究虽试图弥合这一差距,却往往受限于运动粒度过粗、控制意图模糊以及身份特征退化等问题,导致在身份保持与运动控制方面的表现未能达到最优。为此,本文提出 DreamVideo-Omni,这是一个统一的框架,能够通过渐进式两阶段训练范式,实现多主体定制与全维度运动控制的和谐统一。在第一阶段,我们整合了涵盖主体外观、全局运动、局部动态及相机运镜的综合控制信号,进行联合训练。为确保控制的鲁棒性与精确性,我们引入了“条件感知三维旋转位置编码”(condition-aware 3D rotary positional embedding)以协调异构输入,并采用分层运动注入策略以增强全局运动引导。此外,为解决多主体歧义问题,我们设计了“组与角色嵌入”(group and role embeddings),将运动信号显式锚定于特定身份,从而有效地将复杂场景解耦为独立的可控实例。在第二阶段,为缓解身份退化问题,我们设计了一种潜在身份奖励反馈学习范式。该范式基于预训练的视频扩散骨干网络,训练了一个潜在身份奖励模型,从而在潜在空间内提供具备运动感知能力的身份奖励,优先保障符合人类偏好的身份保持效果。依托我们精心构建的大规模数据集以及专为多主体与全维度运动控制评估而设计的 DreamOmni 基准测试(DreamOmni Bench),DreamVideo-Omni 在生成高质量视频及实现精确可控性方面展现了卓越性能。
一句话总结
阿里巴巴与香港科技大学的研究人员提出了 DreamVideo-Omni,这是一个统一的框架,通过引入组嵌入(group embeddings)来解决歧义问题,并采用潜在身份奖励模型(latent identity reward model)在复杂运动中保持保真度,从而实现了具有全向运动控制(omni-motion control)的精确多主体视频定制。
主要贡献
- DreamVideo-Omni 解决了同时保持多个主体身份并实现精确、多粒度运动控制的关键挑战,现有方法在此任务中往往受限于信号类型单一、控制歧义以及身份退化等问题。
- 该框架引入了一种渐进式两阶段训练范式,包含条件感知的 3D 旋转位置嵌入和组 - 角色嵌入,以将异构运动信号显式地锚定到特定主体上;同时结合潜在身份奖励模型,使生成结果与人类偏好对齐,防止身份丢失。
- 在精心构建的大规模数据集和全面的 DreamOmni Bench 上的验证表明,与以往方法相比,该方法在生成具有和谐多主体定制和鲁棒全向运动控制的高质量视频方面表现出更优越的性能。
引言
视频扩散模型已彻底改变了合成技术,但现实世界的应用要求同时保持多个主体身份,并对全局运动、局部动态和相机移动进行精确控制。先前的方法难以实现这一双重目标,因为它们通常依赖单一运动信号,未能将运动与特定主体显式绑定从而导致歧义,并且在协调静态外观与动态运动时 suffers 身份退化。作者利用一个名为 DreamVideo-Omni 的统一框架,采用渐进式两阶段训练范式来解决这些问题。他们引入了架构创新,如组和角色嵌入以消除多主体信号的歧义,并建立了一个潜在身份奖励反馈学习系统,使优化过程与人类偏好对齐,从而在复杂运动中保持身份保真度。
数据集
-
数据集构成与来源:作者构建了一个大规模、密集标注的视频数据集,专门用于 DreamVideo-Omni 的监督微调(SFT)阶段。该语料库旨在支持多主体定制和全面的运动控制,这与以往往往缺乏这些综合能力的数据集形成了鲜明对比。
-
各子集的关键细节:
- 训练数据集:通过自动化流水线过滤原始视频数据,以确保高质量和显著的时间动态。其中包括具有精确全局边界框、主体掩码和运动轨迹标注的视频。
- DreamOmni Bench:一个独立的评估集,包含 1,027 个高质量现实世界视频,其来源独立于训练数据,以确保零样本评估。该基准测试分为 436 个单主体样本和 591 个多主体样本,涵盖人类、动物、一般物体和人脸。
-
数据使用与处理流水线:
- 运动过滤:作者使用 RAFT 估计稠密光流,并丢弃运动幅度较低的视频,以专注于有意义的动态。
- 主体发现:通过 RAM++ 提取语义标签,经 Qwen3 Max 细化以识别显著的运动主体,随后由 Qwen3-VL 生成详细描述。
- 时空标注:Grounding DINO 检测边界框,并将其输入 SAM 2 以生成精确的二值分割掩码。CoTracker3 执行稠密点跟踪,根据掩码将轨迹分类为物体运动或相机运动。
- 参考图像构建:为防止简单的复制粘贴解决方案并实现零样本定制,参考图像从与训练片段在时间上不相交的帧中采样,利用分割掩码进行隔离,并经过 extensive 数据增强。
-
基准构建与过滤:对于 DreamOmni Bench,作者应用人工过滤以保留具有有意义运动的高分辨率视频,同时明确排除静态内容、文本叠加层和水印。所得数据集提供了一个统一的评估框架,用于身份保持和运动控制精度,使用边界框和轨迹准确性的指标。
方法
作者提出了 DreamVideo-Omni,这是一个统一的视频扩散 Transformer 框架,旨在实现具有全向运动控制的和谐多主体定制。该系统遵循渐进式两阶段训练范式,以解决身份保持与复杂运动控制之间的冲突。请参阅框架图以了解整体架构,该图展示了从监督微调(SFT)到强化学习的过渡。
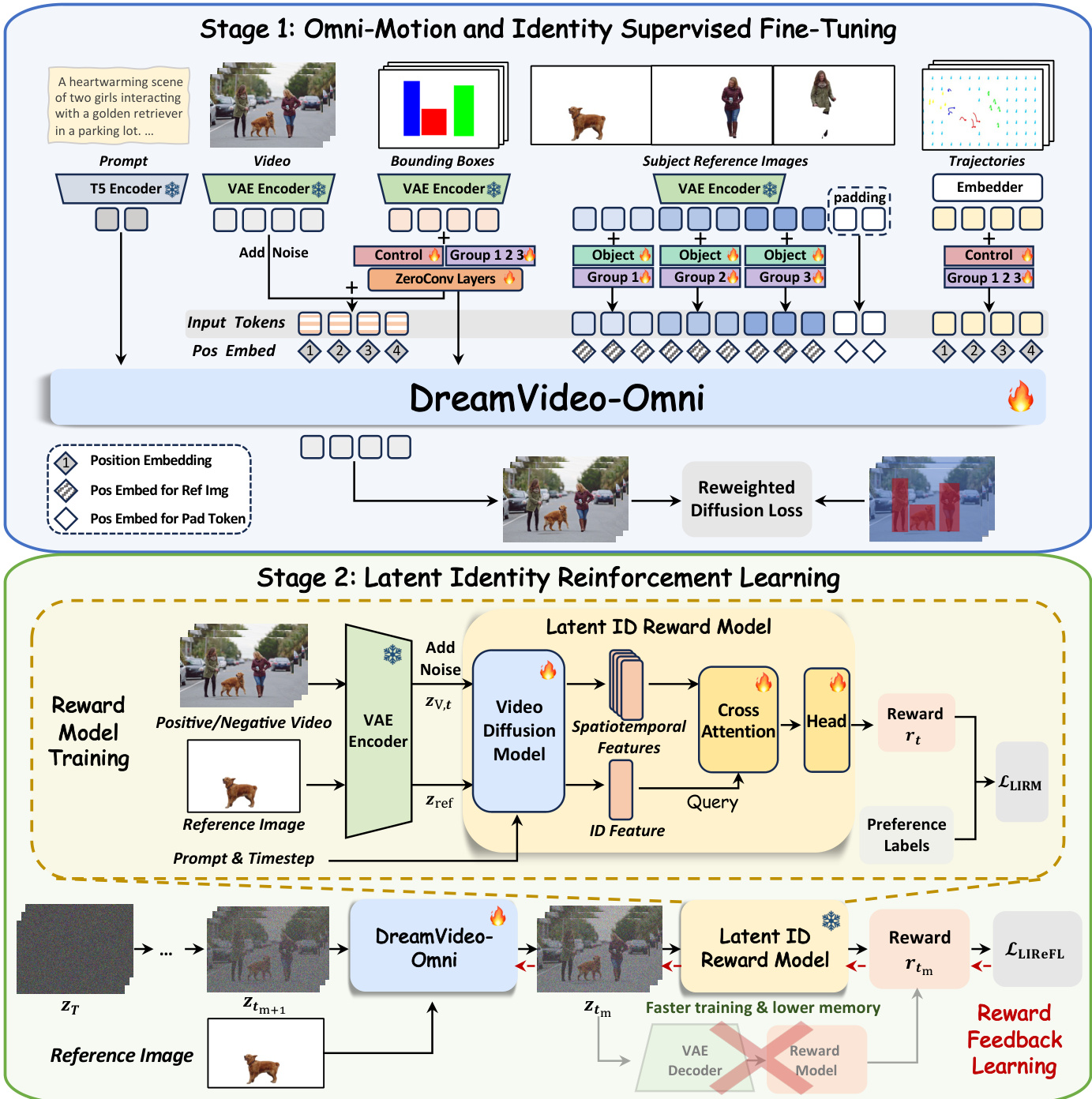
在第一阶段,即全向运动与身份监督微调(Omni-Motion and Identity Supervised Fine-Tuning),模型在包括单主体和多主体定制、全局和局部物体运动控制以及相机移动的综合任务集上进行训练。为了实现精确的组合,作者设计了四个紧凑的条件信号。这些信号的数据准备涉及严格的自动化流水线。
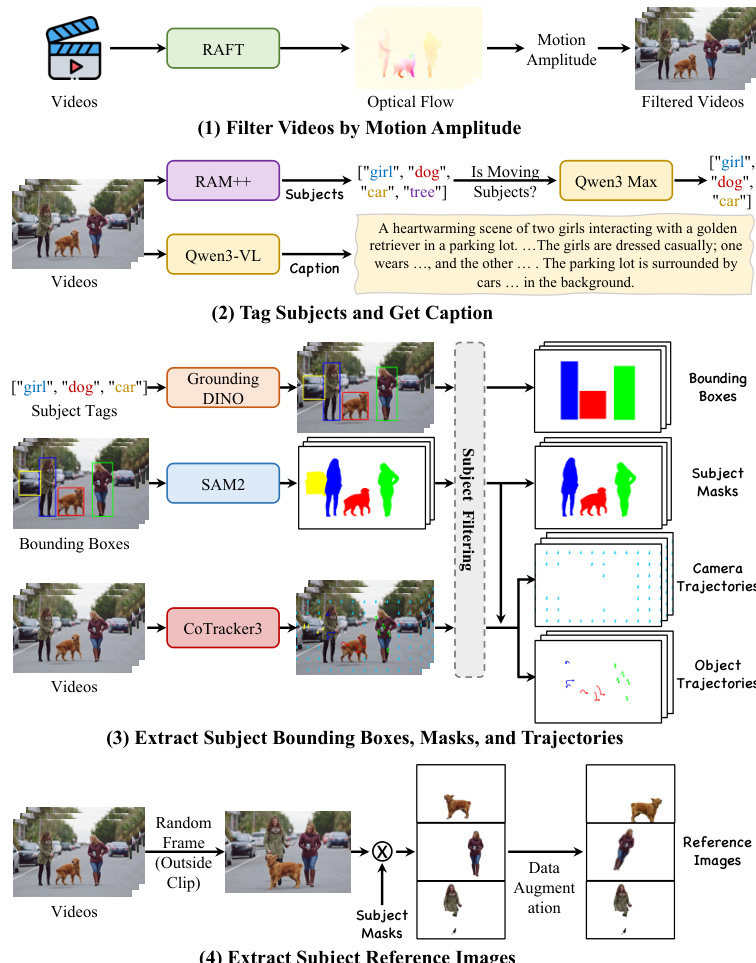
该流水线根据运动幅度过滤视频,标记主体,并提取边界框、掩码和轨迹。生成的综合标注为训练提供了详细的描述、边界框、轨迹和主体掩码。

模型架构采用条件感知的 3D 旋转位置嵌入(RoPE)来处理异构输入。视频帧令牌接收序列时间索引,而参考图像令牌被分配一个共享的独立时间索引,以将其与视频序列解耦。轨迹令牌继承视频帧索引以确保时空对齐。为了减轻控制歧义,作者引入了组和角色嵌入。唯一的组嵌入将参考主体与其对应的边界框和轨迹绑定,而角色嵌入则区分视觉外观资产和运动控制引导。
对于条件信号注入,作者为边界框实现了分层运动注入策略。边界框潜在变量通过可学习的、层特定的零卷积(zero-convolutions)添加到噪声输入潜在变量和每个 DiT 块的输出中,公式如下:
h0=zt+Zin(zbox),hl+1=Blockl(hl)+Zl(zbox).其中 zt 和 zbox 分别是输入噪声视频潜在变量和边界框潜在变量。局部物体运动和相机移动通过点轨迹进行控制,采用混合采样策略,在随机网格采样和物体感知采样之间交替。训练目标利用重加权扩散损失,放大边界框内的贡献以增强主体学习:
Lsft=Ez,ϵ,C,t[(1+λ1M)⋅∣∣ϵ−ϵθ(zt,C,t)∣∣22],其中 C 代表综合条件集,M 表示二值边界框掩码。
第二阶段,即潜在身份强化学习(Latent Identity Reinforcement Learning),解决了低级重建损失在保持细粒度外观细节方面的不足。作者引入了一个直接在潜在空间运行的潜在身份奖励模型(LIRM),以减轻计算开销。LIRM 架构包括一个视频扩散模型骨干网络、一个身份交叉注意力层和一个奖励预测头。来自参考图像的身份特征作为查询 Q,用于关注作为键 K 和值 V 的视频时空特征:
hattn=Attention(Q,K,V)=Softmax(dQK⊤)V,生成的表示通过轻量级 MLP 头传递,以预测标量奖励 rt:
rt=H(hattn+Q).利用该模型,作者执行了潜在身份奖励反馈学习(LIReFL)。这种方法通过在中间噪声潜在变量上直接执行奖励反馈,绕过了昂贵的 VAE 解码器。模型执行单个启用梯度的去噪步骤以导出预测的潜在变量 ztm,该变量由冻结的 LIRM 进行评估。强化损失被构建为最大化预期的身份保真度:
LLIReFL=−Etm,cixt,zref[rtm].为了防止奖励黑客攻击(reward hacking),最终训练目标将监督 SFT 目标与奖励反馈损失相结合:
L=Lsft+λ2LLIReFL,其中 λ2 控制奖励反馈的强度。这种平衡策略确保模型与人类身份偏好保持一致,同时保持精确的运动控制。
实验
- 联合主体定制与运动控制实验验证了所提出的框架成功地在高保真身份保持与精确轨迹遵循之间取得了平衡,优于那些在身份退化或运动漂移方面表现不佳的基线模型。
- 纯主体定制评估证实了该方法在多主体场景中防止身份混合和泄露的能力,同时与现有方法相比保持了更优越的文本对齐和面部细节。
- 运动控制基准测试表明,该模型在空间布局准确性和轨迹精度方面显著优于参数量更大的模型,证明了其在复杂运动任务中的效率和鲁棒性。
- 涌现能力测试揭示,统一的训练范式实现了零样本图像到视频生成和首帧条件轨迹控制,而无需针对特定任务进行微调。
- 消融研究确立了条件感知的 3D RoPE、组和角色嵌入以及分层边界框注入是关键组件,而潜在身份强化学习阶段对于细化身份细节和避免奖励黑客攻击至关重要。