Command Palette
Search for a command to run...
行动前审视:增强面向视觉 - 语言 - 动作模型的视觉基础表征
行动前审视:增强面向视觉 - 语言 - 动作模型的视觉基础表征
摘要
视觉 - 语言 - 动作(VLA)模型近期已成为机器人操作领域极具前景的范式,其可靠的动作预测高度依赖于对基于语言指令的视觉观测进行准确解读与融合。尽管已有研究致力于增强 VLA 模型的视觉能力,但大多数方法将大语言模型(LLM)骨干网络视为黑盒,难以深入洞察视觉信息如何被映射至动作生成过程。为此,我们对多种基于不同动作生成范式的 VLA 模型进行了系统性分析,发现随着动作生成过程的推进,模型深层对视觉 token 的敏感度逐渐降低。基于这一发现,我们提出了 DeepVision-VLA,该模型构建于视觉 - 语言混合 Transformer(VL-MoT)框架之上。该框架实现了视觉基础模型与 VLA 骨干网络之间的共享注意力机制,将来自视觉专家模型的多层级视觉特征注入 VLA 骨干网络的深层,从而增强视觉表征,以支持更精准、更复杂的操作任务。此外,我们引入了动作引导的视觉剪枝(Action-Guided Visual Pruning, AGVP)方法,该方法利用浅层注意力机制剪除与任务无关的视觉 token,同时保留关键信息,在最小化计算开销的前提下强化了对操作至关重要的视觉线索。实验结果表明,DeepVision-VLA 在仿真任务与真实世界任务中分别超越了现有最先进方法 9.0% 和 7.5%,为设计视觉增强的 VLA 模型提供了新的见解。
一句话总结
来自北京大学、Simplexity Robotics 和香港中文大学的研究人员提出了 DeepVision-VLA,这是一种视觉 - 语言混合 Transformer 框架。该框架将多层级视觉特征注入到更深层中,并采用动作引导的视觉剪枝技术,在复杂的机器人操作任务中显著优于先前的方法。
主要贡献
- 本文介绍了 DeepVision-VLA,这是一个基于视觉 - 语言混合 Transformer 架构的框架。它将来自专用视觉专家的多层级视觉特征注入到 VLA 主干网络的更深层中,以抵消动作生成过程中视觉敏感性的逐渐丧失。
- 提出了一种动作引导的视觉剪枝策略,通过利用浅层注意力来识别并保留与任务相关的视觉 token,同时以最小的计算开销移除无关的背景数据,从而优化信息流。
- 实验结果表明,所提出的方法在模拟任务上比之前的最先进方法高出 9.0%,在真实世界操作基准测试上高出 7.5%,验证了增强视觉定位在复杂机器人控制中的有效性。
引言
视觉 - 语言 - 动作(VLA)模型对于机器人操作至关重要,因为它们将视觉观察和语言指令转化为精确的物理动作。然而,先前的方法通常将底层的大语言模型(LLM)主干视为黑盒,未能解决一个关键限制:模型对任务相关视觉 token 的敏感性在更深层中逐渐退化。为了解决这一问题,作者引入了 DeepVision-VLA,该模型利用视觉 - 语言混合 Transformer 框架,将来自专用视觉专家的多层级视觉特征直接注入到 VLA 主干的更深层中。他们进一步通过动作引导的视觉剪枝技术增强了该架构,该技术利用浅层注意力过滤无关的视觉 token,确保只有关键线索影响动作生成。
方法
作者基于 QwenVLA-OFT 基线进行构建,该基线利用视觉编码器(SigLIP2-Large)和 LLM 主干(Qwen3-VL)将观察和指令映射为动作。然而,标准的 VLA 模型通常在深层中遭受敏感性衰减,导致视觉定位变得弥散,难以支持精确操作。为了解决这一问题,作者提出了 DeepVision-VLA 框架,通过将来自视觉专家的多层级知识注入到 VLA 的深层来增强视觉定位。
请参阅框架图,以直观对比原始架构与所提出的 DeepVision-VLA。虽然原始模型仅依赖 LLM 主干,但所提出的方法引入了一个视觉专家分支,用于处理高分辨率输入以捕捉细粒度的空间细节。该设计旨在抵消深层网络中视觉敏感性的丧失。
详细的架构如下图所示。该模型由一个视觉专家分支(使用 DINOv3)和标准的 LLM 主干组成。视觉专家仅连接到 VLA 的最深 n 层,因为视觉定位在这些层中通常最弱。为了整合这些特征,作者采用了视觉 - 语言混合 Transformer(VL-MoT)设计。不同于简单的拼接,来自视觉专家的中间查询(Query)、键(Key)和值(Value)(QKV)表示被暴露出来,并通过共享注意力机制与深层 VLA 层中对应的 QKV 进行整合。
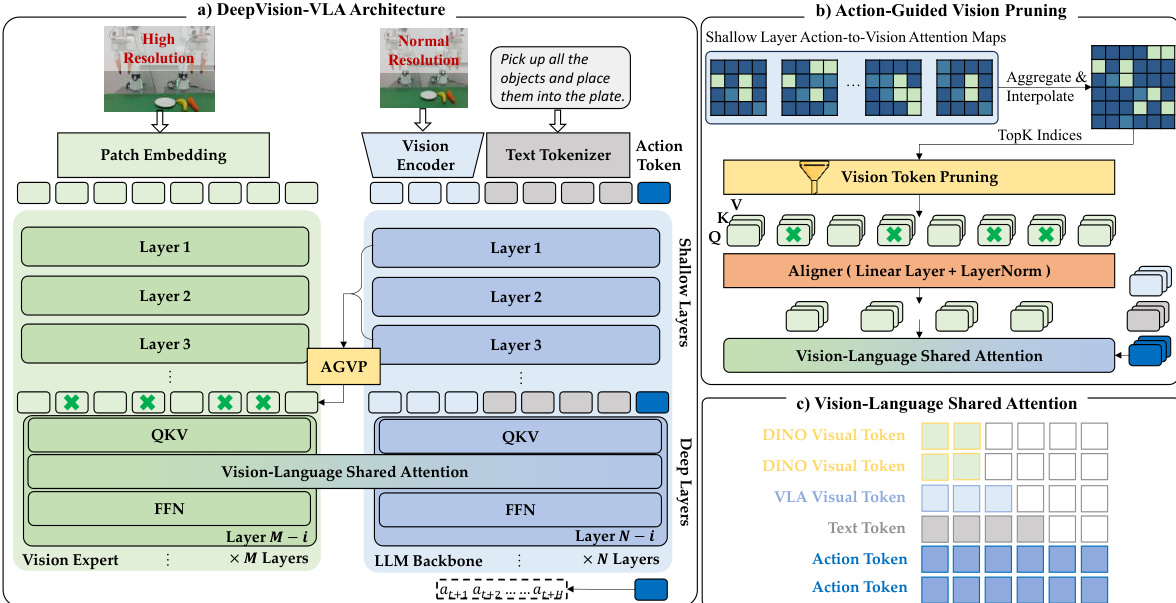
为了确保模型专注于与任务相关的区域,作者引入了动作引导的视觉剪枝(AGVP)。该策略利用 VLA 浅层的注意力图(此处视觉定位最可靠)来识别感兴趣区域(ROIs)。这些注意力线索在浅层上进行聚合,并经过插值以匹配视觉专家的分辨率。随后,模型仅保留前 K 个最相关的视觉 token,从而在将这些 token 整合到深层之前有效过滤掉冗余的背景特征。
这些剪枝后的视觉 token 的整合通过视觉 - 语言共享注意力机制处理。在该模块中,来自视觉专家和 LLM 主干的 QKV 投影被拼接在一起。注意力计算基于这个组合集合进行,实现了跨分支的信息交换,同时保留了独立的处理路径。这使得深层能够访问来自视觉专家的高级、以对象为中心的表示,显著提高了动作预测的精度。该模型在大规模跨具身数据集上进行端到端训练,在推理过程中,整个流程无需额外外部监督即可完全执行。
实验
- 对现有 VLA 模型的逐层分析表明,虽然浅层能有效将动作定位在任务相关的视觉区域,但深层越来越依赖弥散且相关性较低的特征,导致动作可靠性降低。
- 仿真实验表明,通过整合视觉 - 语言混合 Transformer 框架和动作引导的视觉剪枝策略,所提出的 DeepVision-VLA 在多种操作任务中显著优于多个基线模型。
- 消融研究证实,将高分辨率视觉专家与深层 LLM 层耦合,并利用动作到视觉的注意力进行 token 剪枝,对于保持强大的视觉定位和实现卓越性能至关重要。
- 在复杂单臂任务上的真实世界评估显示,该模型在精确操作场景(如书写和倾倒)中实现了高成功率,即使在多阶段序列中也能保持稳定性和准确性。
- 在未见过的背景和不同光照条件下的泛化测试表明,该模型能有效将任务相关物体与环境噪声解耦,并在基线方法失效的情况下保持鲁棒性能。