Command Palette
Search for a command to run...
视觉 - 语言模型能否破解“三仙归洞”难题?
视觉 - 语言模型能否破解“三仙归洞”难题?
Tiedong Liu Wee Sun Lee
摘要
视觉实体追踪是人类与生俱来的认知能力,然而它仍是视觉 - 语言模型(Vision-Language Models, VLMs)面临的关键瓶颈。现有视频基准测试中,这一缺陷常被视觉捷径所掩盖。为此,我们提出了 VET-Bench:一种合成诊断测试平台,其特点是包含视觉外观完全相同的物体,迫使模型必须仅依赖时空连续性进行追踪。实验结果表明,当前最先进的 VLMs 在 VET-Bench 上的表现接近或等同于随机猜测水平,揭示了其根本性局限:过度依赖单帧静态特征,且无法在时间维度上维持实体表征。我们进一步提供了理论分析,将其与状态追踪问题建立关联,证明:受限于表达能力,基于固定深度 Transformer 架构的 VLMs 在缺乏中间监督的情况下,本质上无法追踪不可区分的物体。针对这一挑战,我们提出了时空 grounded 思维链(Spatiotemporal Grounded Chain-of-Thought, SGCoT)方法,其核心在于将物体轨迹生成作为显式的中间状态。借助 Molmo2 模型已有的物体追踪能力,我们通过仅在合成纯文本数据上进行微调以实现对齐,从而激发 SGCoT 推理机制。所提方法在 VET-Bench 上取得了超过 90% 的准确率,达到当前最优水平,证明 VLMs 能够在无需外部工具辅助的情况下,端到端地可靠解决视频“空手套白狼”(shell-game)任务。我们的代码与数据已公开于 https://vetbench.github.io。
一句话总结
新加坡国立大学的研究人员推出了 VET-Bench,旨在揭示视觉 - 语言模型(VLM)在目标跟踪方面的失败,并提出了时空 grounded 思维链(Spatiotemporal Grounded Chain-of-Thought)技术。该技术通过生成显式的物体轨迹来克服表达能力限制,在不可区分物体的跟踪任务中实现了超过 90% 的准确率。
主要贡献
- 现有的视频基准测试允许模型依赖静态外观线索,从而掩盖了视觉实体跟踪这一关键瓶颈,促使我们推出了 VET-Bench。这是一个合成测试平台,包含视觉上完全相同的物体,迫使模型仅依靠时空连续性进行跟踪。
- 理论分析证明,视觉实体跟踪是 NC1 完全问题,表明由于表达能力受限,固定深度的基于 Transformer 的 VLM 在没有中间监督的情况下,从根本上无法解决此任务。
- 提出的时空 grounded 思维链(SGCoT)方法能够激发显式的物体轨迹生成作为中间推理状态,使 Molmo2 模型在不借助外部工具的情况下,在 VET-Bench 上实现了超过 90% 的最先进准确率。
引言
视觉实体跟踪是具身智能和游戏代理的基础能力,但当前的视觉 - 语言模型(VLM)由于过度依赖静态外观线索而非真正的时空连续性,在此任务上表现挣扎。现有的基准测试往往通过包含视觉捷径(如独特的物体特征)来掩盖这一缺陷,使得模型无需在帧间进行实际跟踪即可获得高分。作者通过引入 VET-Bench 解决了这些局限性,这是一个使用视觉上相同物体的合成测试平台,迫使模型仅依赖运动连续性,同时也证明了固定深度的 Transformer 在没有中间计算的情况下,理论上无法解决此类任务。为了克服这些表达能力限制,他们提出了时空 grounded 思维链(SGCoT),该方法通过激发显式的物体轨迹生成作为中间推理步骤,使模型在不借助外部工具的情况下在基准测试中实现了超过 90% 的准确率。
数据集
-
数据集构成与来源:作者推出了 VET-Bench,这是一个通过 three.js 管道生成的完全合成数据集,用于评估视觉实体跟踪。与现实世界的基准测试不同,这种方法提供了对环境参数(如颜色、材质、纹理、光照和相机视角)的细粒度控制,以防止数据泄露和过拟合。
-
关键子集详情:该基准测试专注于两个典型任务:
- 杯子游戏:模仿“三仙归洞”(Shell Game),该任务要求跟踪隐藏在相同不透明容器下的球,这些容器会进行位置交换。
- 纸牌游戏:灵感来源于“三牌戏法”(Three-Card Monte),该任务涉及跟踪一张被翻面并洗牌的纸牌。
- 该管道允许精确调整物体数量和交换次数,以创建无限多的剧集,并实现对特定因素的诊断评估。
-
使用与训练策略:该数据集旨在用于诊断评估而非标准训练,迫使模型完全依赖细粒度的时空感知。作者利用它证明,在其他基准测试中取得高分的模型在此处往往失败,因为它们无法在没有显式帧级线索的情况下解决该任务。
-
处理与过滤规则:为了确保真实性和防止捷径,生成过程执行了严格的约束:
- 没有任何单帧能揭示目标身份或交换操作。
- 所有容器在视觉上完全相同且不透明,以阻断基于外观的重识别。
- 数据集移除了其他基准测试(如 VideoReasonBench)中发现的静态线索和符号注释(如箭头)。
- 这种设计确保了正确答案依赖于利用帧间的时空连续性,而非帧内的静态信息。
方法
作者将视觉实体跟踪任务形式化为:在包含 N 个视觉上不可区分物体的视频序列 V={F0,…,FT} 中,确定目标物体 i 的终端索引 π(i)。为了确保问题定义良好,强制执行连续性约束,即连续帧之间的最大位移 d 满足 2d<Δ,从而防止物体交叉时的身份混叠。如下面的基准测试概览图所示,视觉实体跟踪基准(VET-Bench)通过“杯子游戏”和“纸牌游戏”等场景评估这种能力,其中物体会经历洗牌置换。该图强调,虽然人类可以直观地跟踪这些实体,但标准的视觉 - 语言模型(VLM)即使尝试逐步推理,也往往无法提供正确答案。
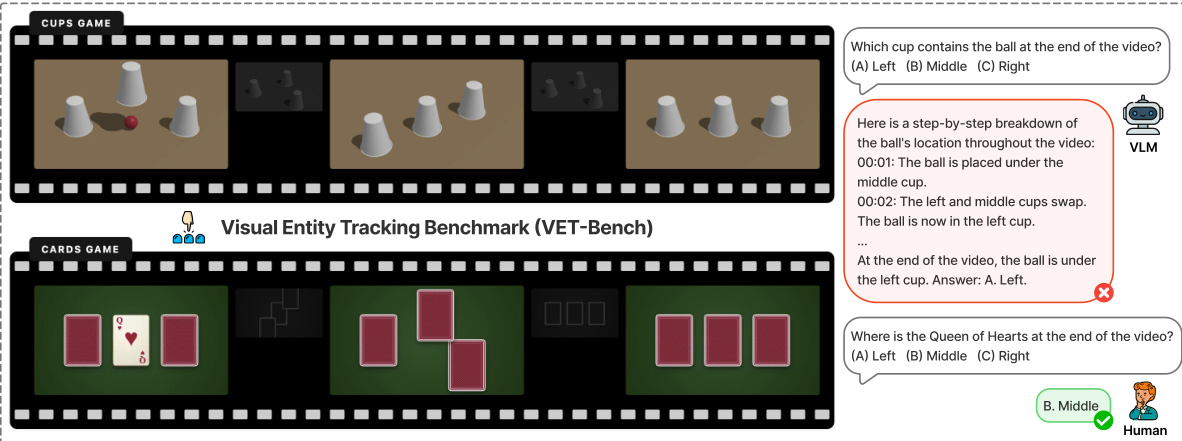
理论分析表明,对于 k≥5 个物体,跟踪问题是 NC1-完全的,这超出了恒定深度 Transformer 通过直接端到端训练解决该问题的理论能力。实验结果证实,使用直接答案监督进行训练会导致损失停滞在随机猜测水平。为了克服这些限制,作者提出了时空 grounded 思维链(SGCoT)。该方法利用在视频物体跟踪上预训练的 Molmo2 模型,生成显式的时空轨迹作为中间推理步骤。
模型不是直接提供答案,而是被提示以 <tracks coords="timestamp object_idx x y;..."> 的格式输出结构化轨迹,其中时间戳以 0.5 秒为间隔,坐标经过归一化。该轨迹作为思维链,明确对齐事件发生的时间和实体所在的位置。训练过程被设计为高效且仅基于文本。作者使用 Python 脚本合成轨迹,并通过屏蔽生成轨迹 token 的损失来对齐模型,同时仅监督最终答案。这种方法鼓励模型在保留其 grounding 能力的同时,学习从 SGCoT 提供的显式状态表示中推导最终答案。通过在一致的时间间隔上离散化时间并确保每个时间戳的精确空间状态,SGCoT 避免了通用描述性思维链中存在的时序错位和定义不足问题。
实验
- 对多种专有和开源视频 - 语言模型在 VET-Bench 杯子游戏上的评估显示,所有系统的表现都接近随机猜测,表明在细粒度时空实体跟踪方面存在普遍失败。
- 定性分析确定了三种主要的失败模式:无推理的直接猜测、遗漏特定交换事件的粗略语义描述,以及幻觉出的交换序列(模型生成了逻辑连贯但视觉上错误的跟踪步骤)。
- 改变交换次数的实验表明,虽然模型可以通过依赖静态视觉线索在零交换任务中取得成功,但仅进行一次交换后,性能就崩溃为随机猜测,证明了其无法维持物体连续性。
- 改变物体数量的测试表明,准确率与物体数量成反比,证实模型并未执行真正的实体跟踪,而是诉诸于统计猜测。
- 一个经过过滤的视频子集(包含相同的不透明杯子且无视觉捷径)证实,当前模型仅在利用数据集伪影时表现出色,而当严格需要鲁棒的视觉感知时则完全失败。
- 使用时空 grounded 思维链对模型进行微调虽然改善了推理结构,但当模型无法区分视觉上相同的物体时仍然失败,导致跟踪跳跃和最终预测错误。