Command Palette
Search for a command to run...
Cheers:解耦图像块细节与语义表示,实现统一的多模态理解与生成
Cheers:解耦图像块细节与语义表示,实现统一的多模态理解与生成
摘要
多模态建模领域的一个前沿热点,是将视觉理解与视觉生成统一于单一模型之中。然而,这两项任务对解码机制与视觉表征的需求存在显著差异,使得在共享特征空间内进行联合优化极具挑战。本文提出 Cheers,一种统一的多模态模型,其核心创新在于将图像块级细节与语义表征解耦:一方面通过语义稳定化提升多模态理解能力,另一方面借助门控细节残差机制增强图像生成的保真度。Cheers 包含三个关键组件:(i)统一的视觉分词器,将图像潜在状态编码并压缩为语义令牌,以高效支持大语言模型(LLM)的条件生成;(ii)基于 LLM 的 Transformer 架构,统一了文本生成的自回归解码与图像生成的扩散解码;(iii)级联流匹配头,首先解码视觉语义,随后从视觉分词器注入经语义门控控制的细节残差,以细化高频内容。在主流基准测试上的实验结果表明,Cheers 在视觉理解与生成任务上均达到或超越了当前先进的统一多模态模型(UMMs)。此外,Cheers 实现了 4 倍的令牌压缩比,显著提升了高分辨率图像编码与生成的效率。值得注意的是,在 GenEval 和 MMBench 等广泛使用的基准测试中,Cheers 的表现优于 Tar-1.5B 模型,而其训练成本仅为后者的 20%,充分证明了其在统一多模态建模方面的有效性与高效性(即 4 倍令牌压缩)。我们将公开全部代码与数据,以支持后续研究。
一句话总结
来自清华大学、西安交通大学和中国科学院大学的研究人员提出了 CHEERS,这是一个统一的 multimodal 模型,通过将 patch 级细节与语义表示解耦,以稳定理解能力并提升生成保真度。该方法在关键基准测试中优于 Tar-1.5B,同时仅需 20% 的训练成本。
主要贡献
- CHEERS 通过将 patch 级细节与语义表示解耦,解决了统一多模态模型中的优化冲突,从而稳定理解能力并提升生成保真度。
- 该模型引入了一种混合架构,包括用于高效 token 压缩的统一视觉 tokenizer、基于 LLM 的 Transformer(支持混合自回归与扩散解码),以及级联流匹配头(用于注入门控细节残差)。
- 大量实验表明,CHEERS 在 GenEval 和 MMBench 基准测试中优于 Tar-1.5B 模型,同时仅需 20% 的训练成本,并实现了 4 倍的 token 压缩率。
引言
统一多模态模型旨在单一架构内整合视觉理解与高保真图像生成,但由于这些任务需要根本不同的解码机制和视觉表示,它们往往面临挑战。先前的方法通常通过共享单一特征空间来强制妥协,导致优化冲突:语义理解受量化误差影响,或生成保真度丢失高频细节。作者在 CHEERS 中利用了一种新颖的解耦策略,将 patch 级细节与语义表示分离,以解决这一矛盾。该方法利用统一视觉 tokenizer 进行高效的语义压缩,并采用级联流匹配头,先合成全局结构,再注入语义门控的细节残差,从而在显著降低训练成本的同时,在理解和生成两方面均实现了卓越性能。
数据集
-
数据集构成与来源:作者构建了一个多阶段训练流程,使用了来自 LLaVA-UHD-v3、ImageNet、Infinity-MM、TextAtlas5M、BLIP-3o、DiffusionDB、Objects365、Nemotron-Cascade、Echo-4o-Image、MoviePosters 和 ShareGPT-4o-Image 的多样化图像 - 描述对、多模态样本和纯文本数据。
-
各子集的关键细节:
- 阶段 I(视觉 - 语言对齐):利用来自 LLaVA-UHD-v3 的 450 万图像 - 描述对,以及由 Qwen2.5-VL-3B 重新标注的 130 万 ImageNet 样本,其中 ImageNet 数据集重复 10 次以建立生成能力。
- 阶段 II(通用预训练):在 3000 万多模态样本上进行优化,理解、生成和文本数据的比例为 3:6:1,包含来自 Infinity-MM 和 LLaVA-UHD-v3 的描述、来自 BLIP-3o 和合成 FLUX.2 输出的生成数据,以及来自 LLaVA-UHD-v3 的文本。
- 阶段 III(精细化预训练):扩展至 3300 万样本,保持 3:6:1 的比例,结合 LLaVA-UHD-v3 指令数据、通过 DiffusionDB 和 LLaVA-OneVision-1.5 提示使用 FLUX.2-klein-9B 生成的合成图像、基于 Objects365 的 46.6 万组合推理指令,以及来自 Nemotron-Cascade 的文本。
- 阶段 IV(监督微调):专注于 380 万精选样本,包括阶段 III 的高质量子集、Echo-4o-Image、MoviePosters 和 ShareGPT-4o-Image。
-
模型使用与训练策略:作者采用四阶段渐进式训练方法,图像分辨率固定为 512x512。阶段 I 仅训练随机初始化的模块,阶段 II 和 III 优化除 VAE 外的所有参数,阶段 IV 执行监督微调,理解与生成任务的批次比例为 1:1。
-
处理与元数据细节:使用 FLUX.2-klein-9B 结合来自 DiffusionDB 和 LLaVA-OneVision-1.5 的提示生成合成数据,以增强生成和推理能力。特定子集如 Objects365 被用于合成 46.6 万条指令,针对组合推理技能,如计数、颜色识别和空间理解。
方法
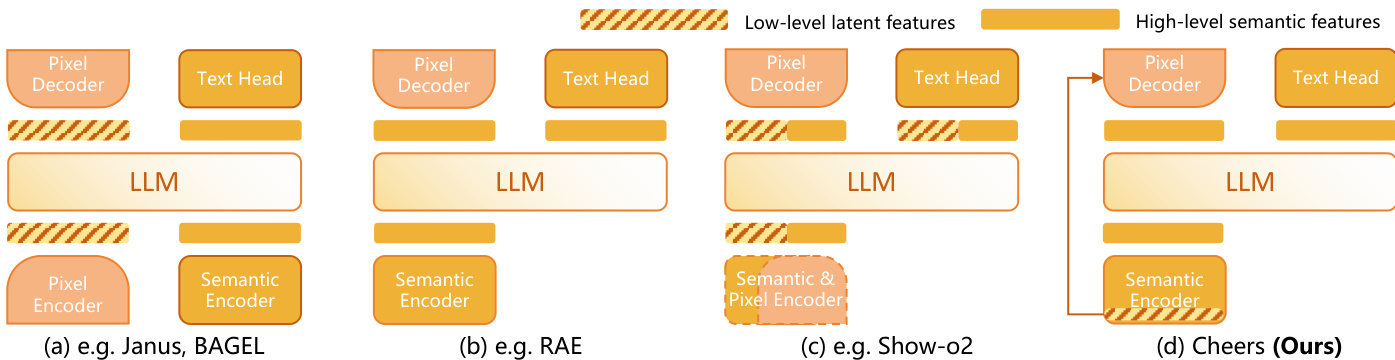
作者提出了 CHEERS 框架,旨在通过专用架构统一多模态理解与图像生成。其设计哲学优先考虑特征粒度的分离,以处理语义推理与像素级重建之间的权衡。请参阅下图,该图对比了 CHEERS 与 Janus、BAGEL 和 RAE 等先前的方法。与直接处理潜在特征或依赖单一编码器的方法不同,所提出的架构采用专用的语义编码器处理高层特征,同时为低层潜在特征保留独立路径,确保在编码过程中不丢失细粒度细节。
系统的核心依赖于统一视觉 tokenizer、基于 LLM 的统一 Transformer 以及级联流匹配头。如下图所示,统一视觉 tokenizer 桥接了潜在表示与统一语义视觉嵌入。它由 VAE 解码器和语义编码器(具体为 SigLIP2-ViT)组成。给定输入图像 X,VAE 编码器产生潜在状态 z1。为了统一不同任务,任务相关的潜在变量 zt 被构建为 zt=tz1+(1−t)z0,其中 z0 代表潜在噪声。对于视觉理解,t 固定为 1;而对于图像生成,t 从 (0,1) 中采样。系统不直接处理这些潜在变量,而是将 zt 通过 VAE 解码器重建为像素级图像,随后由 ViT 主干网络编码以提取高层语义 token zs(t)。这一重建步骤至关重要,因为它避免了直接处理潜在变量时常见的细粒度特征丢失问题。
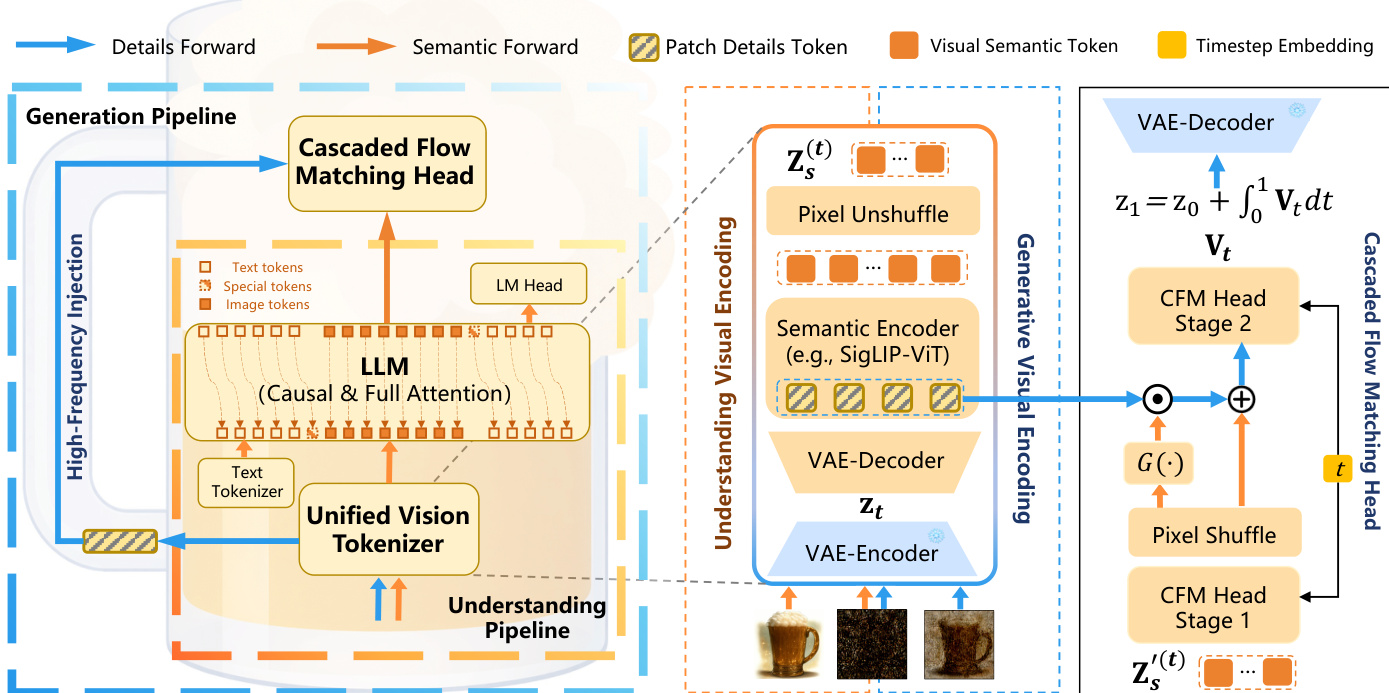
这些语义 token 随后由基于 LLM 的统一 Transformer 处理。作者利用自回归主干网络,将语义视觉 token 与文本嵌入拼接为统一的输入序列。对视觉 token 应用双向注意力掩码以捕捉全局上下文,而对文本 token 应用因果掩码以实现自回归解码。根据任务不同,LLM 的输出被路由到不同的解码范式。对于图像生成,连续的视觉隐藏状态通过级联流匹配头进行解码。
该头显式地将高频视觉细节与低频语义特征解耦。它由两个级联阶段组成。第一阶段执行低分辨率语义生成,随后通过 PixelShuffle 模块对特征图进行上采样。在第二阶段,引入高频 patch 细节以更新解码后的特征。如下图所示,随着去噪步骤的推进,高频注入的强度动态增加,模拟了人类绘画的层次结构。注入过程由门控网络 G(⋅) 控制,根据以下方程更新特征: Zs′(t)←G(Zs′(t))⊙S(D(zt))+Zs′(t) 其中 G(Zs′(t)) 表示标量图,⊙ 表示逐元素乘法。

该框架使用统一的优化目标进行端到端训练。对于文本和理解任务,使用标准的交叉熵损失。对于图像生成,应用流匹配损失以预测速度场 Vt。在推理过程中,潜在轨迹通过预测速度场的数值积分,从高斯噪声 z0 演化至终端状态 z1,从而实现基于连续时间的流采样。
实验
- 在多模态理解和视觉生成任务上的全面基准测试证实,CHEERS 在通用、OCR、空间及知识导向领域均实现了具有竞争力的性能,同时展现出卓越的数据效率。
- 对训练流程的分析表明,生成能力逐步提升,与真实世界数据相比,合成指令导向数据在保真度和对齐方面带来了显著增益。
- 高频注入的可视化揭示了一种动态的由粗到细机制:高频信号在初始轮廓阶段稀疏使用,而在后期阶段增强以细化纹理和局部细节。
- 消融实验表明,理解与生成的联合训练并未损害理解能力,且高频注入对于生成清晰、细节丰富的图像至关重要。
- 关于架构设计的实验证明,在语义编码之前重建像素对于保留 OCR 任务所需的细粒度视觉细节是必要的。
- 对涌现能力的评估显示,统一视觉 tokenizer 通过共享特征表示,使模型能够强泛化到未训练的任务,如图像编辑和多图像组合。