Command Palette
Search for a command to run...
HSImul3R:面向仿真就绪的人 - 场景交互的物理闭环重建
HSImul3R:面向仿真就绪的人 - 场景交互的物理闭环重建
Yukang Cao Haozhe Xie Fangzhou Hong Long Zhuo Zhaoxi Chen Liang Pan Ziwei Liu
摘要
本文提出 HSImul3R,这是一个面向人类 - 场景交互(HSI)的仿真就绪三维重建统一框架,适用于从非专业采集数据(包括稀疏视角图像和单目视频)进行重建。现有方法存在“感知 - 仿真”鸿沟:视觉上合理的重建结果往往违背物理约束,导致物理引擎运行不稳定,并在具身智能应用中失败。为弥合这一鸿沟,我们引入一种基于物理的双向优化流程,将物理模拟器作为主动监督器,联合优化人体动态与场景几何结构。在正向过程中,我们采用面向场景的强化学习(Scene-targeted Reinforcement Learning),在运动保真度与接触稳定性双重监督下优化人体运动;在反向过程中,我们提出直接仿真奖励优化(Direct Simulation Reward Optimization),利用模拟反馈中的重力稳定性与交互成功信息来 refine 场景几何结构。此外,我们构建了 HSIBench,这是一个包含多样化物体与交互场景的新基准。大量实验表明,HSImul3R 能够生成首个稳定且具备仿真就绪能力的 HSI 重建结果,并可直接部署于现实世界的人形机器人。
一句话总结
南洋理工大学、ACE Robotics 和上海人工智能实验室的研究人员提出了 HSImul3R,这是一个统一的框架,通过采用双向优化流程来细化人体运动和场景几何,从而弥合感知与仿真之间的差距,实现从日常拍摄数据中构建稳定且可直接用于仿真的“人 - 场景”交互重建。
主要贡献
- 本文提出了 HSImul3R,这是一个统一的框架,通过采用基于物理的双向优化流程来弥合感知与仿真之间的差距,其中物理仿真器充当主动监督者,共同优化人体动力学和场景几何。
- 该方法实施了面向场景的强化学习以进行前向运动优化,并采用直接仿真奖励优化(DSRO)进行反向几何细化,利用仿真反馈中的重力稳定性和接触约束来确保物理有效性。
- 这项工作提出了 HSIBench,这是一个包含多样化物体和交互场景的新基准数据集,并通过大量实验证明,该方法能够生成首个稳定且可直接部署在真实人形机器人上的仿真就绪重建结果。
引言
具身智能需要物理有效的“人 - 场景”交互数据,以弥合视觉观察与真实世界机器人部署之间的差距。先前的方法往往生成视觉上合理但在物理引擎中失效的重建结果,因为它们将人体运动和场景几何视为独立的问题,或者仅针对 2D 图像对齐进行优化。作者提出了 HSImul3R,这是一个统一的框架,利用物理仿真器作为主动监督者,通过双向优化流程共同优化人体动力学和场景几何。该方法利用面向场景的强化学习来稳定人体运动,并利用直接仿真奖励优化来校正场景几何,从而实现了首个稳定且可直接部署在人形机器人上的仿真就绪重建。
方法
所提出的方法 HSImul3R 通过双向优化流程,从日常拍摄数据中重建可直接用于仿真的“人 - 场景”交互。如下图所示,该框架集成了用于运动细化的前向传递和用于物体几何校正的反向传递。
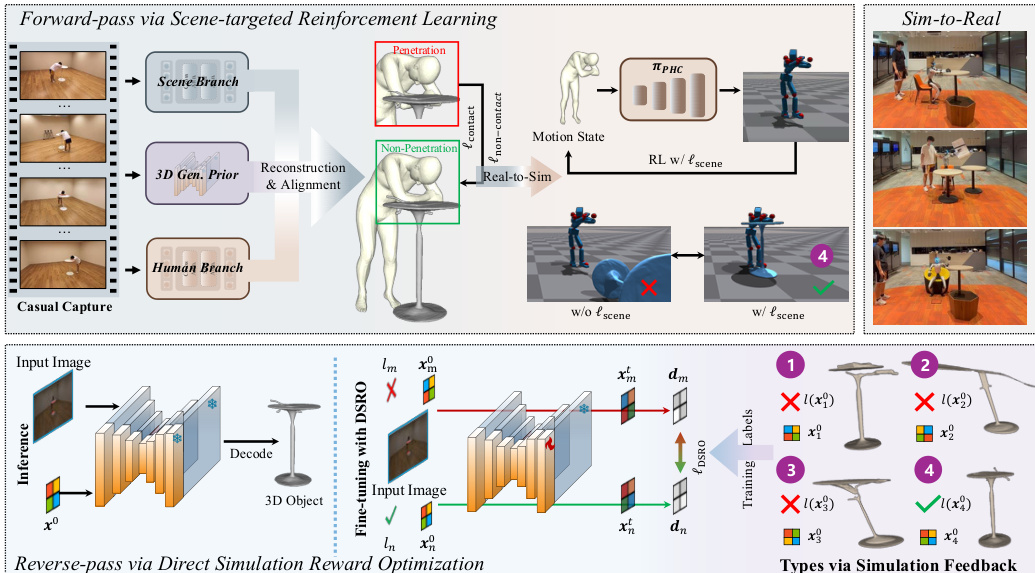
该过程始于静态场景几何和动态人体运动的独立重建。作者利用 DUSt3R 进行场景结构恢复,并采用 SAM2、4DHumans 和 ViTPose 等工具进行人体运动估计。为了解决标准对齐方法缺乏 3D 几何感知的问题,他们引入了源自“图像到 3D"生成模型的显式 3D 结构先验。这一步骤细化了场景几何并强制实施了鲁棒的交互约束。具体而言,作者针对接触和非接触场景使用不同的损失函数来优化恢复的人体位置和生成的物体位置。对于非接触情况,损失函数最小化人体最近部位与物体顶点之间的距离。对于接触情况,损失函数利用符号距离函数对穿透深度进行惩罚。
在初始重建之后,该方法采用前向传递优化以确保动力学稳定。这一阶段使用了面向场景的强化学习方案。作者引入了一种监督信号,强制要求人形机器人与场景物体之间保持空间邻近性,从而鼓励物理上合理的接触。这是通过最小化损失函数 ℓscene 实现的,其定义如下:
ℓscene=Ncontact⋅Nsurf1⋅i=1∑Ncontacti=1∑Nsurf∥μio−kjh∥22其中 Ncontact 是人体与场景物体之间的接触数量,Nsurf 表示局部接触区域内采样的物体表面点数量。
为了进一步校正结构正确性,引入了反向传递优化。该过程利用仿真器关于物理稳定性的反馈来细化 3D 物体生成。作者提出了直接仿真奖励优化(DSRO),该方法利用仿真结果作为监督信号。DSRO 目标函数包含一个稳定性标签 l(x0),该标签由物体在重力作用下是否保持直立并在交互过程中达到稳定最终状态来决定。稳定性定义如下:
l(x0)={1,0,if stableotherwise这使得系统能够微调生成的物体,以消除诸如缺失腿部或表面扭曲等会导致仿真失败的伪影。
实验
- 重建和仿真实验表明,所提出的方法在实现稳定的“人 - 场景”交互、最小化物理穿透以及保留有意义的接触状态方面,显著优于现有的基线方法和变体。
- 定性比较显示,该方法生成的物体结构几何准确,失真更少,有效防止了基线方法中观察到的物体意外位移和交互失败。
- 消融实验证实,面向场景的仿真损失和 DSRO 微调策略对于维持交互稳定性以及防止导致物体位移的夸张运动至关重要。
- 在宇树 G1 人形机器人上的真实世界部署验证了,经过细化的运动可以成功迁移到物理硬件上,以执行复杂的交互场景。
- 对输入视角的分析表明,虽然增加视角能略微提高运动质量,但它们对仿真稳定性或穿透处理的影响微乎其微。