Command Palette
Search for a command to run...
将世界模拟模型锚定于真实世界大都市
将世界模拟模型锚定于真实世界大都市
摘要
如果世界模拟模型能够渲染的不是虚构环境,而是真实存在的城市,将会如何?以往的生成式世界模型通过想象所有内容,合成出视觉逼真但人工构造的环境。本文提出“首尔世界模型”(Seoul World Model, SWM),这是一种以真实城市首尔为根基的城市级世界模型。SWM 利用基于邻近街景图像的检索增强条件(retrieval-augmented conditioning),将自回归视频生成过程锚定于真实场景。然而,该设计引入了若干挑战:检索参考帧与动态目标场景之间存在时间错位;车载采集因采样间隔稀疏而导致轨迹多样性受限及数据稀疏。针对这些问题,我们提出了跨时序配对(cross-temporal pairing)策略、一个支持多样化相机轨迹的大规模合成数据集,以及一种视图插值流水线(view interpolation pipeline),能够从稀疏街景图像中合成连贯的训练视频。此外,我们引入“虚拟前瞻汇点”(Virtual Lookahead Sink),通过持续将每一生成片段重新锚定于未来位置的检索图像,以稳定长时序生成。我们在首尔、釜山和安娜堡三座城市中,将 SWM 与近期视频世界模型进行了评估。结果表明,SWM 在生成空间忠实、时序一致且基于真实城市环境的长时序视频方面优于现有方法,其生成轨迹可达数百米,同时支持多样化的相机运动以及由文本提示驱动的场景变化。
一句话总结
KAIST AI、NAVER AI Lab 和 SNU AIIS 的研究人员推出了首尔世界模型(Seoul World Model),这是一个城市级仿真系统,通过检索街景图像将视频生成锚定在真实的城市环境中。与以往构想人工世界的模型不同,该方法利用跨时间配对和虚拟前视汇点(Virtual Lookahead Sink),确保了空间保真度和长时程稳定性,适用于城市规划、自动驾驶等应用。
主要贡献
- 本文提出了首尔世界模型,这是一个城市级世界仿真系统,它通过基于地理坐标和相机动作检索并条件化附近的街景图像,将自回归视频生成锚定在真实的城市环境中。
- 为克服数据稀疏性和轨迹限制,该工作提出了一个包含多样化相机路径的大规模合成数据集,并采用一种视图插值流程,利用间歇性定格策略从稀疏的街景采集数据中合成连贯的训练视频。
- 提出了一种虚拟前视汇点,通过持续将每个视频片段重新锚定到未来位置的检索图像上来稳定长时程生成;实验结果表明,该方法能够生成在数百米轨迹上保持空间忠实且时间一致的视频。
引言
当前的世界仿真模型通过构想初始帧之后的所有内容来生成动态环境,这限制了它们在需要严格忠实于现实世界位置(如城市规划或自动驾驶测试)的应用中的效用。现有方法难以将生成过程锚定在特定的物理城市中,因为它们缺乏将预测锚定到实际几何结构的机制,而传统的 3D 重建系统则是静态的,无法模拟动态场景。作者引入了首尔世界模型,通过检索附近的街景图像来条件化输出,从而将自回归视频生成锚定在真实的都市环境中。为了解决静态参考与动态场景之间的时间错位、数据覆盖稀疏以及长时程漂移等挑战,他们采用了跨时间配对、包含多样化轨迹的大规模合成数据集,以及一种能持续将生成过程重新锚定到未来位置的虚拟前视汇点。
数据集
数据集构成与来源
作者通过构建街景运动(SWM)数据集,将街景参考与目标视频序列对齐,从而将生成过程锚定在现实世界的几何结构中。数据主要来源于三个部分:
- 真实街景数据:来自 NAVER Map 的 120 万张全景图像,覆盖首尔主要城市区域。
- 合成城市数据:使用 CARLA 模拟器在六个城市地图上渲染的 1.27 万段视频。
- 公开驾驶数据集:用于增加场景多样性的补充性公开可用驾驶视频数据集。
各子集的关键细节
- 真实街景子集:
- 规模:120 万张原始全景图经处理后缩减为 44 万张用于训练。
- 元数据:包含 GPS 坐标和时间戳;车牌和行人已模糊处理以保护隐私。
- 覆盖范围:覆盖首尔大都市区约 44.8 公里的东西向和 31.0 公里的南北向区域。
- 合成子集:
- 规模:1.27 万段视频,覆盖 431,500 平方米。
- 轨迹类型:包括行人路径(人行道/十字路口)、车辆路径(高速公路/转弯)以及自由相机导航。
- 参考数据:4K 街景位置,每个位置渲染八个方向的视图,共计 3.2 万张参考帧。
- 风格化增强:对插值后的街景数据应用风格迁移(如天气变化、昼夜转换)生成的 1 万段额外视频。
数据使用与训练策略
- 跨时间配对:作者执行严格规则,要求参考图像与目标序列在不同时间戳下采集。这防止模型学习特定车辆或行人等瞬态对象,迫使其依赖持久的空间结构。
- 训练划分:44 万张处理后的真实图像和完整的合成数据集用于训练视频生成模型。
- 文本提示:使用 Qwen2.5-VL-72B 为视频生成场景和事件的长、短描述。这些描述与从姿态序列导出的预定义相机动作标签(如“直行”、“左转”)相结合。
- 混合策略:训练混合数据结合了真实世界数据、合成数据和风格化增强,以在几何保真度与多样化的相机路径及环境条件之间取得平衡。
处理与构建细节
- 视图插值:为了弥合稀疏全景采集(5–20 米间隔)与连续视频需求之间的差距,作者使用预训练的潜在视频模型,从 N 个稀疏关键帧合成平滑的 T 帧视频。
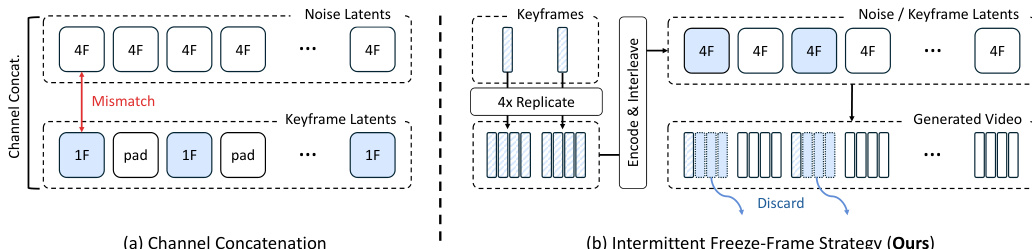
- 间歇性定格策略:为了确保与 3D VAE 的 4 帧时间压缩兼容,关键帧在编码期间重复四次。在推理阶段,这些重复帧被丢弃以恢复预期的平滑视频。
- 几何对齐:使用 Depth Anything V3 估计深度图和 6-DoF 相机姿态。利用 GPS 元数据将这些数据对齐到现实世界的度量尺度,以确保数据库内全局坐标的一致性。
- 检索流程:在推理阶段,系统执行两阶段检索:最近邻搜索识别候选位置,随后进行基于深度的重投影过滤,以选择为目标视图提供足够像素覆盖的参考图像。
方法
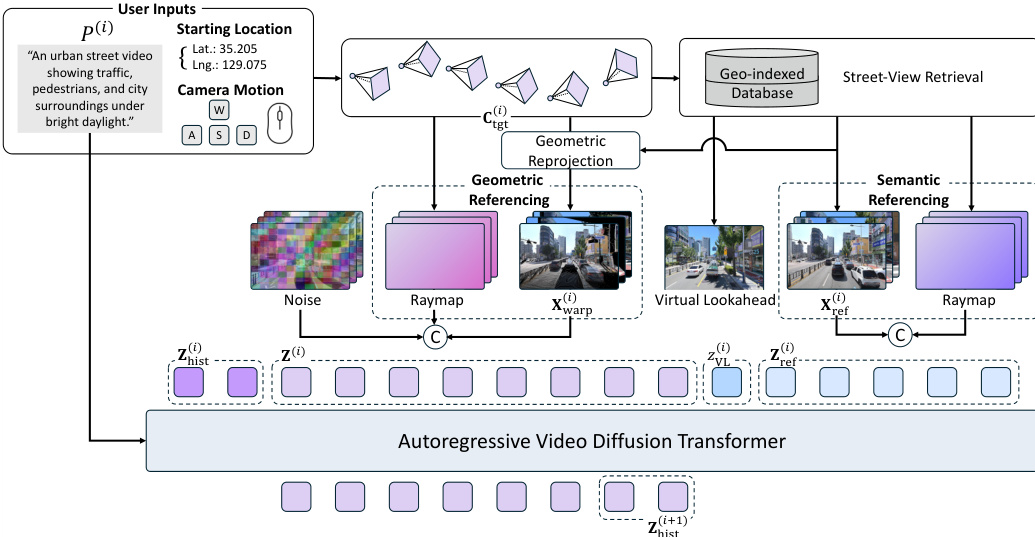
提出的街景世界模型(SWM)利用检索增强的自回归框架生成基于真实城市的视频。该系统建立在预训练的扩散 Transformer(DiT)之上,该模型在通过 3D VAE 从像素空间帧压缩得到的潜在空间中运行。生成过程以分块方式自回归进行,其中每个块的条件包括文本提示、目标相机轨迹和噪声潜在变量。为了确保时间连续性,后续块会以前一个块输出尾部的历史潜在变量为条件。
请参阅框架图以了解整体架构。用户输入(包括起始位置和相机运动)驱动基于地理索引的数据库检索过程。这检索到相关的街景图像,这些图像具有双重作用:作为长时程稳定性的虚拟前视汇点,以及提供几何和语义参考的条件,从而将生成过程锚定在现实世界的几何结构和外观上。
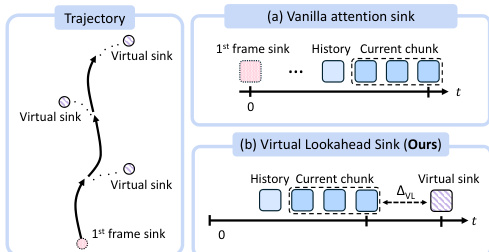
为了缓解在城市尺度距离上进行自回归生成时固有的误差累积问题,作者引入了虚拟前视汇点。如下图所示,标准的注意力汇点通常锚定在初始帧,随着相机远离,该帧的相关性会逐渐降低。相比之下,所提出的方法为每个块动态检索目标轨迹终点最近的街景图像。该图像被视为虚拟的未来目的地,并与当前生成块保持足够的时间间隔。通过在当前帧之前提供一个干净、无误差的锚点,模型拥有了一个稳定的收敛目标,确保锚定始终与正在生成的区域相关。
该模型采用两种互补的条件化路径来利用检索到的参考数据。几何参考通过基于深度的前向泼溅(forward splatting)将参考图像重投影到目标视点,提供密集的空间布局线索。该变形视频被编码并与噪声目标潜在变量进行通道级拼接。语义参考通过将原始参考注入 Transformer 的潜在序列来保留外观细节。每个参考被编码为单个潜在变量,并沿时间轴与目标潜在变量拼接。为了处理参考图像与生成场景中可能不同的动态对象,作者利用跨时间配对策略,鼓励模型关注持久的场景结构而非瞬态内容。
对于涉及关键帧的训练数据生成,作者利用间歇性定格策略。请参阅对比图,该图将其与标准的通道拼接进行了对比。通道拼接基线由于孤立的关键帧无法形成 3D VAE 时间压缩的有效组,导致关键帧 adherence 较弱。所提出的策略通过连续重复关键帧 4 次,确保每个关键帧形成与 VAE 时间步长匹配的完整 4 帧组。在推理期间,输入关键帧被编码为单个干净的潜在变量,并在每个扩散步骤中替换噪声输入潜在变量中的相应位置,从而确保精确的关键帧条件化。
实验
- 基于真实世界的世界仿真基准测试验证了该模型能够生成高保真、动态的视频,这些视频与实际城市布局和目标相机轨迹一致,优于那些在长时程下出现漂移和结构崩溃的现有世界模型。
- 消融实验证实,跨时间数据配对对于处理动态对象至关重要,而结合几何和语义参考策略则能确保结构对齐和视觉保真度。
- 虚拟前视汇点设计对于在扩展生成过程中保持稳定性至关重要,与传统的注意力汇点方法相比,显著减少了误差累积并保持了场景连贯性。
- 与静态场景生成器的比较表明,为了从真实世界参考中生成时间连贯的视频,必须对场景动态进行显式建模,因为静态模型无法合成合理的运动。