Command Palette
Search for a command to run...
MetaClaw:仅需对话——一种在开放环境中进行元学习并持续演化的 Agent
MetaClaw:仅需对话——一种在开放环境中进行元学习并持续演化的 Agent
摘要
大语言模型(LLM)智能体正日益被应用于复杂任务,然而已部署的智能体往往保持静态,无法随用户需求的演变而自适应调整。这导致了持续服务需求与更新能力以匹配动态任务分布的必要性之间的张力。在 OpenClaw 等平台上,其需处理来自 20 多个渠道的多样化工作负载,现有方法存在明显局限:或仅存储原始轨迹而未提炼知识,或维护静态技能库,亦或需要中断服务以进行重训练。为此,我们提出 MetaClaw——一种持续元学习框架,能够协同演进基础 LLM 策略与可复用的行为技能库。MetaClaw 采用两种互补机制:其一为“技能驱动的快速适应”,通过 LLM 进化器(LLM evolver)分析失败轨迹以合成新技能,从而实现零停机时间的即时改进;其二为“机会式策略优化”,利用云端的 LoRA 微调及基于过程奖励模型的强化学习(RL-PRM)执行基于梯度的更新。该优化由机会式元学习调度器(OMLS)在用户非活跃窗口期触发,OMLS 通过监控系统空闲状态与日历数据实现智能调度。这两种机制相互增强:更优的策略生成更高质量的轨迹以辅助技能合成,而更丰富的技能则为策略优化提供更优质的数据。为防止数据污染,MetaClaw 引入版本化机制,将支持数据与查询数据严格分离。基于代理架构构建的 MetaClaw 无需本地 GPU 即可扩展至生产级 LLM 规模。在 MetaClaw-Bench 与 AutoResearchClaw 上的实验表明,技能驱动适应可将准确率相对提升高达 32%;完整流水线使 Kimi-K2.5 的准确率从 21.4% 提升至 40.6%,复合鲁棒性提升 18.3%。相关代码已开源:https://github.com/aiming-lab/MetaClaw。
一句话总结
来自北卡罗来纳大学教堂山分校、卡内基梅隆大学、加州大学圣克鲁兹分校和加州大学伯克利分校的研究人员提出了 MetaClaw,这是一个持续元学习框架,它独特地将零停机技能合成与机会性策略优化相结合,使已部署的 LLM 智能体能够在不中断服务的情况下自主演进并适应不断变化的用户需求。
主要贡献
- 本文介绍了 MetaClaw,这是一个持续元学习框架,通过两种互补机制联合维护基础 LLM 策略和不断演进的技能库:用于即时行为更新的技能驱动快速适应,以及用于基于梯度的权重细化的机会性策略优化。
- 一种新颖的机会性元学习调度器监控用户不活动信号(如睡眠时间和日历占用情况),仅在空闲窗口触发基于云的 LoRA 微调,从而确保零服务停机时间,同时通过严格分离支持数据和查询数据,防止陈旧奖励数据的污染。
- 在 MetaClaw-Bench 和 AutoResearchClaw 上的实验表明,完整流程将任务完成率提高了 8.25 倍,准确率从 21.4% 提升至 40.6%,而仅靠技能驱动适应即可带来高达 32% 的相对准确率提升。
引言
部署在现实世界环境中的大型语言模型智能体,由于在初始训练后保持静态,往往与不断变化的用户需求产生错位。现有的适应方法难以应对这种动态环境:基于记忆的方法存储冗余数据却无法提取可迁移的模式;基于技能的系统无法协调行为指令与模型权重;而强化学习技术则面临用陈旧数据污染更新的风险,或需要服务停机。作者提出了 MetaClaw,这是一个持续元学习框架,统一了两种互补的适应机制,使智能体能够不间断地持续演进。该系统结合了技能驱动的快速适应(即时从失败中合成新的行为指令)和机会性策略优化(仅在用户不活动的窗口期执行基于梯度的权重更新),以确保零停机时间。
数据集
-
数据集构成与来源 作者构建了 MetaClaw-Bench,这是一个持续智能体基准测试,旨在评估在连续现实世界 CLI 任务中的适应能力。它包含分布在 44 个模拟工作日内的 934 个问题,并包括两个互补部分。该基准测试还纳入了 AutoResearchClaw,这是一个完全自主的 23 阶段研究流程,用于下游评估以测试 CLI 任务之外的泛化能力。
-
各子集的关键细节
- 第一部分(30 个工作日模拟): 包含 346 个问题,每天 10 到 15 个任务。任务包括文件检查操作(由自动检查器验证的结构化编辑)和关于领域规则的多项选择题。难度单调递增,第 25 至 30 天需要复杂的逐步推理。
- 第二部分(14 个工作日模拟): 包含 588 个问题,每天 42 个任务,分为 434 个多项选择题和 154 个文件检查任务。这里的文件检查任务侧重于基于规则的转换,其中符合行为启发式规则(如模式约定)是主要瓶颈。
- AutoResearchClaw: 一个长视野工作负载,涵盖文献搜索、假设生成、代码合成和论文起草,失败表现为阶段重试或流程运行不完整。
-
在模型训练与评估中的使用 作者使用 MetaClaw-Bench 在难度递增的情况下对持续适应进行压力测试。第一部分衡量执行可靠性和端到端完成情况,而第二部分评估策略多快能内化程序规则。在训练方面,系统采用技能驱动的快速适应机制,从失败中合成行为指令,并在空闲窗口期利用强化学习进行机会性策略优化阶段。AutoResearchClaw 数据集用于将积累的技能注入到所有 18 个 LLM 驱动阶段的系统提示中,以衡量阶段完成率和重试率的改进。
-
处理与元数据构建
- 工作区状态: 工作区状态(包括文件和配置)在每天内的各轮次中持续存在,每个问题都包含上一轮的结果作为纠正反馈上下文。
- 上下文注入: 第二部分使用特定的工作区上下文文件初始化会话,定义智能体的角色、用户档案和行为原则。
- 技能演进: 失败的轨迹被添加到支持集以合成新技能,而成功的轨迹则存储在 RL 缓冲区中用于策略更新。
- 指标: 基准测试的评估依赖于整体准确率和文件检查完成率,研究流程的评估则依赖于流程级指标,如阶段重试率和鲁棒性得分。
方法
MetaClaw 作为一个持续元学习系统运行,旨在增强部署在非线性任务流中的 CLI 智能体。其核心目标是持续改进元模型 M=(θ,S),其中 θ 表示基础 LLM 策略的参数,S 代表技能指令库。该架构依赖于在两个不同时间尺度上运行的两种互补机制:技能驱动的快速适应和机会性策略优化。
参考框架图以直观了解系统组件和数据流。
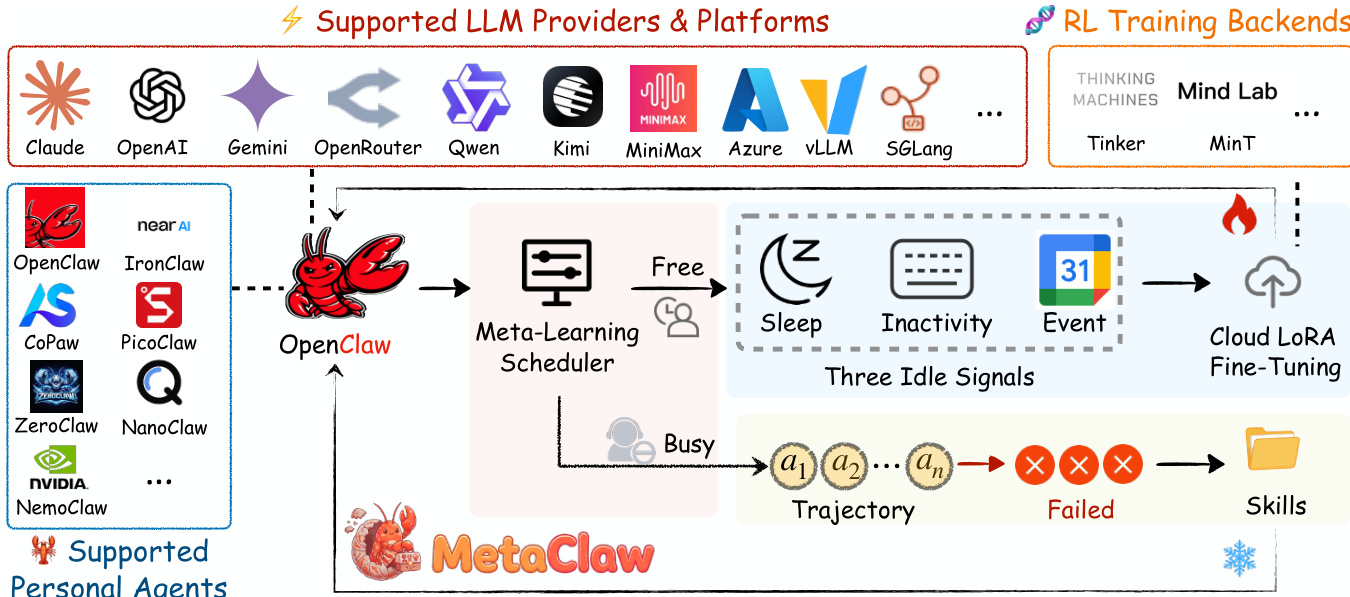
该系统将各种支持的个性化智能体和 LLM 提供商集成到一个由元学习调度器协调的统一学习循环中。该调度器管理智能体的状态,区分智能体执行用户任务的“忙碌”期和系统空闲的“空闲”期。
在“忙碌”状态下,系统采用技能驱动的快速适应。随着智能体执行任务,它会收集轨迹。揭示失败模式的轨迹构成支持集 Dsup。技能演化器分析这些失败以合成新的行为指令,通过无梯度的经验蒸馏过程更新技能库 S: Sg+1=Sg∪E(Sg,Dasup) 此步骤仅修改技能库,保持策略参数 θ 不变。由于技能注入通过提示词操作,这种适应不会造成服务停机,并立即对后续任务生效。
相反,在“空闲”状态下,系统执行机会性策略优化。元学习调度器监控三个空闲信号以确定何时启动训练:睡眠窗口、系统不活动以及日历感知调度。当检测到空闲窗口时,调度器触发云 LoRA 微调以更新策略参数 θ。此过程利用在适应生效后收集的查询轨迹缓冲区 B。策略更新遵循预期奖励的梯度: θt+1=θt+α∇θE(τ,ξ,a′)∼B[R(πθ(⋅∣τ,Sa′))] 至关重要的是,系统通过技能生成版本控制机制,严格分离支持数据和查询数据。触发技能演化的支持数据会被消耗并丢弃,而仅使用反映适应后行为的查询数据进行策略优化。这确保了策略是针对智能体的当前能力进行优化,而不是针对陈旧的奖励信号。
实验
- MetaClaw-Bench 上的主要实验验证了该框架在不同模型和适应模式下 consistently 提升性能,完整流程在部分执行质量和端到端任务完成方面均带来最大增益。
- 定性分析证实,仅靠技能注入可以增强推理和部分执行,但无法可靠地实现零缺陷输出,而将技能注入与基于梯度的策略优化相结合对于实现完整的任务成功是必要的。
- 结果表明,较弱的模型从技能注入中受益更多,优于更强的基线,这表明该方法有效地弥补了能力差距,对于部署能力强但非最先进(SOTA)的模型尤为有价值。
- 在 AutoResearchClaw 基准测试上的实验表明,技能注入可以泛化到开放式、多阶段的研究流程中,而无需梯度更新,显著降低了重试率和迭代周期。
- 时间和任务类型的细分分析显示,技能驱动适应在训练早期解决了程序性知识缺口,而权重级优化随后将策略行为转向处理复杂的执行需求,验证了这两种机制的互补性。