Command Palette
Search for a command to run...
Qianfan-OCR:一种面向文档智能的统一端到端模型
Qianfan-OCR:一种面向文档智能的统一端到端模型
摘要
我们提出了 Qianfan-OCR,这是一款参数量为 4B 的端到端视觉语言模型,在单一架构中统一了文档解析、布局分析与文档理解功能。该模型支持从图像直接转换为 Markdown,并能够执行多种由 prompt 驱动的任务,包括表格提取、图表理解、文档问答(Document QA)以及关键信息抽取。针对端到端 OCR 中显式布局分析能力缺失的问题,我们提出了“布局即思维”(Layout-as-Thought)机制。该机制通过特殊的 think tokens 触发一个可选的思维阶段,在生成最终输出前,先生成结构化的布局表示(包括边界框、元素类型及阅读顺序),从而在恢复布局 grounding 能力的同时,显著提升了对复杂布局的处理精度。在评测方面,Qianfan-OCR 在 OmniDocBench v1.5(得分 93.12)和 OlmOCR Bench(得分 79.8)两项端到端模型基准测试中均位列第一;在 OCRBench、CCOCR、DocVQA 和 ChartQA 等基准上,其表现与同等规模的通用 VLM 相比具有竞争力;此外,该模型在公开的关键信息抽取基准测试中取得了最高的平均分,性能超越了 Gemini-3.1-Pro、Seed-2.0 以及 Qwen3-VL-235B。目前,该模型已通过百度智能云千帆平台向公众开放。
一句话总结
百度千帆团队推出了 Qianfan-OCR,这是一个拥有 40 亿参数的端到端模型,统一了文档解析与理解。通过集成其创新的“思维即布局”(Layout-as-Thought)机制,该模型在单一架构中恢复了显式的空间分析能力,在复杂文档基准测试中超越了以往的多阶段流水线及大型竞争对手。
主要贡献
-
本文介绍了 Qianfan-OCR,这是一个 40 亿参数的端到端视觉 - 语言模型,统一了布局分析、文本识别和语义理解,能够跨多种提示驱动任务直接执行从图像到 Markdown 的转换。该架构通过在处理过程中保留完整的视觉上下文,消除了阶段间的误差传播,实现了结构化解析与文档理解的联合优化。
-
提出了一种名为“思维即布局”(Layout-as-Thought)的新机制,通过在端到端范式中触发可选的思维阶段来生成边界框和阅读顺序等结构化表示,从而恢复显式的布局分析。该方法直接提供空间定位结果,同时利用结构先验来解决复杂布局或非标准阅读顺序文档中的识别歧义。
-
实验结果表明,该模型在 OmniDocBench v1.5 和 OlmOCR Bench 等端到端系统中排名第一,并在关键信息提取基准测试中实现了最先进的性能,超越了 Gemini-3.1-Pro 等更大规模的模型。该工作还展示了在标准 OCR 和文档理解任务上的强大泛化能力,其表现与同等规模的通用视觉 - 语言模型相当。
引言
当前在合同审查和文档检索等行业中的 OCR 应用,往往依赖于将检测、识别和语言模型串联起来的碎片化流水线。这种方法增加了部署成本,导致误差传播,并在文本提取过程中丢弃了关键的视觉上下文。现有解决方案难以在专用小模型的低成本与大型视觉 - 语言模型的高精度之间取得平衡,后者在结构化解析任务上往往表现不佳。
作者推出了 Qianfan-OCR,这是一个 40 亿参数的统一端到端模型,将布局分析、文本识别和语义理解集成到单一架构中。他们利用一种名为“思维即布局”的新机制,允许模型在生成最终输出之前,通过边界框和阅读顺序可选地生成显式的结构推理。这种设计消除了阶段间错误并保留了完整的视觉上下文,使系统能够匹配流水线的精度,同时支持图表解读和文档问答等复杂任务。
数据集
-
数据集构成与来源:作者构建了一个大规模统一数据集,使用了六个专门的合成流水线,涵盖文档解析、关键信息提取、复杂表格、图表理解、公式识别和多语言 OCR。数据来源包括内部文档库、HPLT 多语言语料库以及 2022 年至今的 arXiv LaTeX 源码。
-
各子集的关键细节:
- 文档解析:将图像转换为带有归一化边界框和 HTML 表格的结构化 Markdown。作者采用了来自 PaddleOCR-VL 的细粒度 25 类标签系统,以区分摘要、参考文献和竖排文本等元素。
- 关键信息提取 (KIE):结合开源数据与多模型协同标注以减少幻觉。包括用于业务逻辑验证的硬规则过滤,并针对长序列或密集文本的困难样本进行优化。
- 复杂表格:合并了使用 Faker 和 LLM 进行的程序化合成(3–20 行/列,随机合并)与真实文档提取。真实样本经过 PaddleOCR-VL 与内部模型之间的一致性验证,以确保结构可靠性。
- 图表理解:通过重新渲染 LaTeX 图形代码为矢量图像,从 arXiv 合成了超过 30 万个样本。数据包含 11 种图表类型的元数据和视觉描述,以及趋势分析和异常检测等自定义推理任务。
- 多语言 OCR:通过从 HPLT 语料库进行反向合成,将覆盖范围扩展至 192 种语言。该流水线处理多样的书写系统,具备自动 RTL 检测、字符重塑和随机排版变化功能。
-
模型使用与训练策略:数据支持多阶段渐进式训练。作者实施了“思维即布局”机制,模型在最终输出前在
<layout>标签内生成结构化布局分析,以增强空间推理能力。样本分布根据任务难度进行重新平衡,以提高极端场景下的稳定性。 -
处理与增强细节:
- 裁剪与几何变换:边界框坐标被归一化到 [0, 999] 以实现分辨率不变性。应用旋转增强(90°、180°、270° 和 ±15°)以提高对非标准文档方向的识别性能。
- 噪声注入:两个不同的增强流水线应用了三个噪声阶段:文本噪声(笔画断裂、墨水洇染)、背景噪声(纹理、水印)和成像噪声(模糊、阴影、曝光变化)。
- 过滤:自动过滤器移除重复或极端长度的样本,而一致性检查和业务逻辑规则确保所有子集的高质量标注。
方法
作者提出了 Qianfan-OCR,这是一个 40 亿参数的端到端文档智能模型,在单一的视觉 - 语言架构中统一了文档解析、布局分析和理解。该模型采用多模态桥接架构,包含三个核心组件:用于灵活视觉编码的视觉编码器、用于跨模态对齐的轻量级投影适配器,以及用于文本生成和推理的语言模型骨干。
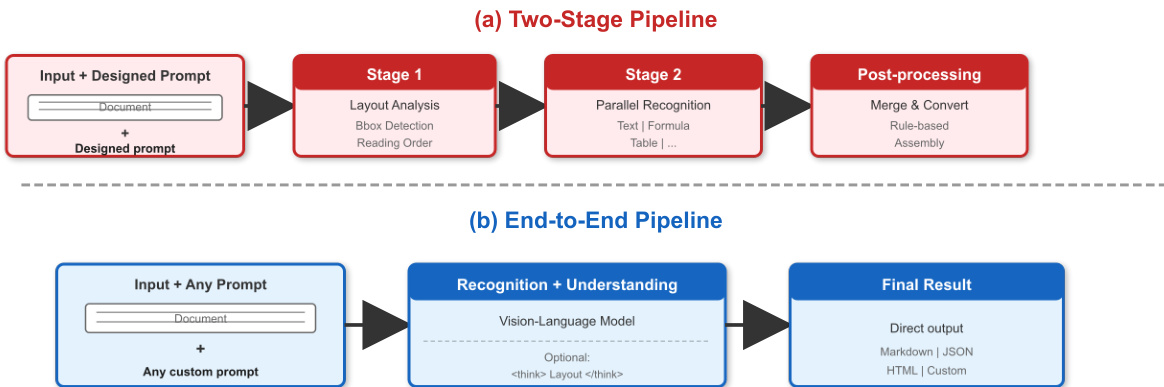
如上图所示,所提出的端到端流水线 (b) 与传统的多阶段方法 (a) 形成对比,它在单一模型中执行直接的图像到 Markdown 转换并支持提示驱动任务。视觉编码器采用 Qianfan-ViT,利用 AnyResolution 设计将输入图像动态平铺为 448×448 的图块,支持高达 4K 的可变分辨率输入。该编码器由 24 层 Transformer 组成,隐藏层维度为 1024,注意力头数为 16,每个图块生成 256 个视觉 token。最多支持 16 个图块,系统可用多达 4,096 个视觉 token 表示单张文档图像,确保细粒度字符识别具有足够的空间分辨率。
连接视觉和文本模态的是一个带有 GELU 激活函数的轻量级双层 MLP。该适配器将来自编码器 1024 维表示空间的视觉特征投影到语言模型 2560 维的嵌入空间。这种设计在最小化适配器参数的同时,确保了有效的跨模态对齐。语言模型骨干是 Qwen3-4B,总参数量为 40 亿,包含 36 层,原生上下文窗口为 32K,可通过 YaRN 扩展至 131K。为了平衡推理能力与部署效率,模型采用分组查询注意力(GQA),包含 32 个查询头和 8 个 KV 头,与标准多头注意力相比,KV 缓存内存减少了 4×。
为了弥合端到端生成与显式布局分析需求之间的差距,作者引入了“思维即布局”。该机制利用由 ⟨think⟩ token 触发的可选思维阶段,模型在此阶段生成包括边界框、元素类型和阅读顺序在内的结构化布局表示,然后生成最终输出。这种方法在端到端范式中恢复了布局分析功能,并在复杂布局或非标准阅读顺序的文档上提供了针对性的精度提升。
训练过程遵循四阶段渐进式方法,旨在系统地构建模型能力。第一阶段专注于跨模态对齐,使用 500 亿 token 进行仅适配器训练,以建立基础的视觉 - 语言对齐。第二阶段涉及基础 OCR 训练,使用 2 万亿 token 进行全参数训练,利用以 OCR 为主的数据混合,包括文档 OCR、场景 OCR 以及手写和公式识别等专门任务。第三阶段实施领域特定增强,使用 8000 亿 token,针对复杂表格、公式和图表等企业关键领域,同时保持通用数据的平衡以防止灾难性遗忘。最后,第四阶段涵盖指令微调与推理增强,使用数百万个指令样本。该阶段采用数据策展、反向合成和图表数据挖掘,以覆盖全面的文档智能任务集,确保对多样化用户指令的鲁棒性。
实验
- 多阶段训练消融研究证实,基础通用预训练对于 OCR 性能至关重要,无法仅由领域特定数据替代,而在专业化过程中混合通用数据和 OCR 数据可防止过拟合并保持通用能力。
- 完整的四阶段训练流水线实现了最佳结果,优于强大的通用视觉 - 语言模型,并证明了渐进式训练配方在不同模型规模上均能有效泛化。
- 在专用和通用 OCR 基准测试上的评估证实,该模型实现了最先进的端到端性能,特别是在多语言识别和复杂文档解析方面表现出色,同时保持了具有竞争力的通用 OCR 能力。
- 文档理解测试显示,端到端处理显著优于传统的两阶段 OCR 加 LLM 流水线,特别是在图表解读和学术推理等空间布局和结构上下文至关重要的任务中。
- 关键信息提取实验表明,该模型超越了商业大模型和更大的开源替代方案,验证了其在中文和英文场景中关联空间字段与内容的卓越能力。
- 推理吞吐量分析表明,端到端架构避免了流水线系统中固有的 CPU 瓶颈,通过高效的以 GPU 为中心的批处理和量化,实现了具有竞争力的处理速度和更简单的部署。
- 对“思维即布局”机制的分析表明,显式布局推理提高了异构和复杂结构文档的准确性,但对于简单、同质的页面则引入了不必要的开销。