Command Palette
Search for a command to run...
人工智能能够习得科学品味
人工智能能够习得科学品味
摘要
杰出科学家具备卓越的判断力与前瞻性,这与所谓“科学品味”(scientific taste)密切相关。本文所指的“科学品味”,即判断与提出具有高潜在影响力研究构想的能力。然而,现有相关研究多聚焦于提升 AI 科学家的执行能力,而对增强其科学品味的探索仍显不足。为此,我们提出一种基于社区反馈的强化学习(Reinforcement Learning from Community Feedback, RLCF)训练范式,该范式利用大规模社区信号作为监督信号,并将科学品味学习建模为偏好建模与对齐问题。在偏好建模阶段,我们利用 70 万对经领域与时间匹配的高引用与低引用论文对,训练“科学评判器”(Scientific Judge)以评估研究构想;在偏好对齐阶段,以“科学评判器”作为奖励模型,训练策略模型“科学思考者”(Scientific Thinker),使其能够提出具有高潜在影响力的研究构想。实验结果表明,“科学评判器”在性能上优于当前最先进(SOTA)的大语言模型(如 GPT-5.2、Gemini 3 Pro),并展现出对未来年份测试数据、未见领域以及同行评审偏好的良好泛化能力。此外,“科学思考者”所提出的研究构想具有比基线方法更高的潜在影响力。我们的研究结果表明,AI 能够习得科学品味,这是迈向具备人类水平的 AI 科学家的关键一步。
一句话总结
复旦大学及合作机构的研究人员提出了 RLCF,这是一种利用社区反馈来增强 AI 科学品味的训练范式。通过部署 SCIENTIFIC JUDGE(科学评判者)和 SCIENTIFIC THINKER(科学思考者)模型,这项工作将重点从执行能力转向生成高影响力的研究想法,在预测未来科学成功方面超越了最先进系统。
主要贡献
- 本文介绍了基于社区反馈的强化学习(RLCF),这是一种将科学品味学习构建为偏好建模与对齐问题的训练范式,利用引用等大规模社区信号作为监督。
- 构建了一个名为 SciJUDGEBench 的新数据集,包含 70 万个按领域和时间匹配的“高引用”与“低引用”论文摘要对,以支持 AI 科学判断能力的训练与评估。
- 开发了两款专用模型:SCIENTIFIC JUDGE 在预测未见领域及未来年份的论文影响力方面超越了最先进的大语言模型(LLM);SCIENTIFIC THINKER 生成的研究想法具有明显更高的潜在影响力,优于基线方法。
引言
当前构建 AI 科学家的努力主要集中在文献检索和自动化实验等执行能力上,但它们难以复现人类判断和提出高影响力研究方向的能力,这种技能被称为“科学品味”。现有方法往往依赖昂贵的人工标注,或无法捕捉推动科学进步的广泛社区共识,导致 AI 在内在判断和构思潜力方面存在空白。为此,作者引入了基于社区反馈的强化学习(RLCF),这是一种将科学品味视为基于大规模引用信号训练的偏好建模问题的范式。他们构建了包含 70 万个匹配论文对的 SciJUDGEBench,用于训练 SCIENTIFIC JUDGE(一种在预测影响力方面超越最先进 LLM 的奖励模型),随后利用该模型训练 SCIENTIFIC THINKER(一种生成研究想法的策模型),其生成的想法具有显著高于基线方法的潜在影响力。
数据集
-
数据集构成与来源 作者从截至 2024 年发布的 210 万篇 arXiv 论文中构建了 SciJUDGEBENCH,涵盖计算机科学、数学、物理学以及包含经济学、定量生物学和统计学在内的多样化“其他”类别。该数据集通过将科学思想(以其标题和摘要表示)配对,将社区反馈转化为成对监督信号。
-
各子集的关键细节
- 训练集:包含从 140 万篇独特论文中衍生的 696,758 个按领域和时间匹配的偏好对。筛选条件确保被选中的论文与低引用论文相比,绝对引用数差异至少为 8,相对差异至少为 30%。
- 主测试集:包含 728 个域内对,采用更严格的筛选标准,要求绝对引用数差异大于 32,相对差异至少为 50%,以确保清晰的偏好信号。
- 时间分布外(OOD)测试集:包含 514 对来自 2025 年发表论文的数据,用于测试对未来数据的泛化能力。该集合在子类别内使用基于百分位的自适应阈值,将高引用论文与低引用同期论文配对,同时保持 5 天的发表窗口。
- 指标分布外(OOD)测试集:由 611 对来自 ICLR 投稿(2017–2026)的论文组成,其偏好由同行评审分数而非引用数决定。作者过滤掉评审者置信度低或评分方差高的论文,然后配对表现最好和最差的论文,以测试向基于评审的判断的迁移能力。
- BioRxiv 测试集:还报告了一个较小的 160 对生物学数据,用于额外评估。
-
模型训练与使用 作者在多种基础架构上训练了 SCIENTIFIC JUDGE 模型,包括 Qwen2.5-Instruct 系列(1.5B 至 32B 参数)、Qwen3 变体以及 Llama-3.1-8B-Instruct。他们采用组相对策略优化(GRPO),以偏好预测的正确性作为可验证奖励。模型首先生成推理轨迹,随后输出二元预测(A 或 B),仅当预测正确时才获得 1 的奖励。
-
处理与评估策略 为减轻领域和时间偏差,所有配对均在同一子类别和相似的发表时间窗口内进行匹配。作者通过在评估时以交换顺序的方式呈现每对数据两次,并仅在模型在两种顺序下保持一致时才将预测判定为正确,从而解决位置偏差问题。元数据构建依赖于 arXiv 的主要分类,“其他”字段明确由特定子类别聚合而成,而非作为剩余类别处理。
方法
作者提出了基于社区反馈的强化学习(RLCF),这是一种旨在为大语言模型注入科学品味的三阶段训练范式。该框架利用大规模社区信号监督学习过程,从数据构建推进到偏好建模,最后进行偏好对齐。
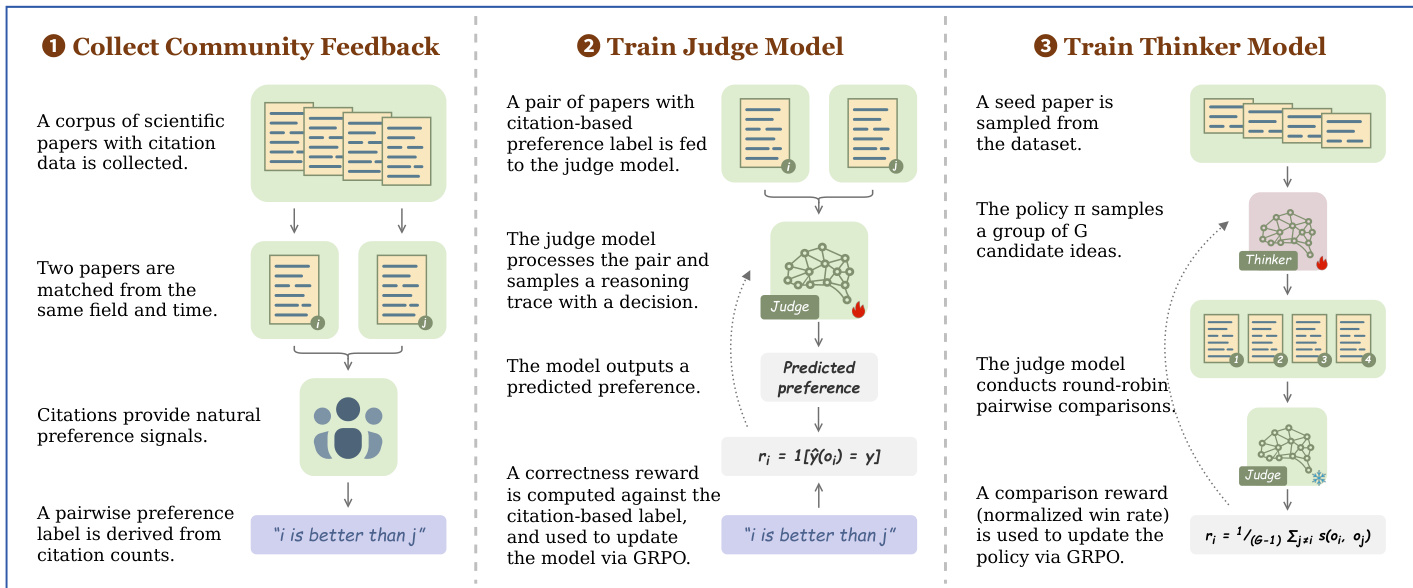
该过程始于收集社区反馈以构建偏好数据。首先收集科学论文语料库,并根据其领域和发表时间进行配对,以确保公平比较。引用数作为自然的偏好信号,其中引用数较高的论文被认为具有更大的潜在影响力。形式上,论文 p 的累积预期影响力定义为 I(p)=limN→∞∑t=1NE[ct(p)],其中 ct(p) 表示第 t 年收到的引用数。这使得可以推导出成对偏好标签,例如“论文 i 优于论文 j",这些标签构成了后续训练阶段的真实标签。
在第二阶段,作者训练 SCIENTIFIC JUDGE 模型以预测研究想法的潜在影响力。将带有基于引用偏好标签的论文对输入评判模型,该模型处理输入并采样推理轨迹以做出决策。模型输出预测的偏好,并根据基于引用的标签计算正确性奖励。该奖励定义为 ri=1[y^(oi)=y],其中 y^ 是预测偏好,y 是真实标签。该信号用于通过组相对策略优化(GRPO)更新评判模型,增强其评估科学价值的能力。
最后阶段涉及训练 SCIENTIFIC THINKER 模型以生成高影响力的研究想法。从数据集中采样一篇种子论文,策略 π 采样一组 G 个候选想法。训练好的评判模型随后在这些候选者之间进行循环成对比较,以评估其相对质量。计算为归一化胜率的比较奖励用于更新策略。该奖励公式为 ri=G−11∑j=is(oi,oj),其中 s(oi,oj) 表示想法 i 与想法 j 之间的比较结果。该奖励信号通过 GRPO 引导 THINKER 模型,使其生成更有可能实现高潜在影响力的想法。
实验
- 扩展实验表明,科学判断能力随着训练数据的增加和模型规模的扩大而持续提升,30B 模型超越了专有基线模型。
- 泛化测试证实,在计算机科学数据上训练的模型能够有效预测未来时间段、未见科学领域(如数学和生物学)以及不同评估指标(如同行评审分数)的论文影响力。
- 使用科学评判者作为奖励模型进行构思训练,显著提升了所提出研究想法的质量,使该系统能够超越基础策略,并在未来研究主题上与最先进模型竞争。
- 案例研究表明,较大的模型能够成功推理复杂因素,如主题普遍性、机构影响力和下游采用情况,而较小的模型偶尔会依赖关于流行度或基础性的误导性启发式方法。
- 针对科学品味的专门训练保留了通用推理和知识能力,在标准基准测试上显示出极小的性能下降。