Command Palette
Search for a command to run...
OmniForcing:释放实时音视频联合生成能力
OmniForcing:释放实时音视频联合生成能力
Yaofeng Su Yuming Li Zeyue Xue Jie Huang Siming Fu Haoran Li Ying Li Zezhong Qian Haoyang Huang Nan Duan
摘要
近期的联合音视频扩散模型虽实现了卓越的生成质量,却因双向注意力依赖导致高延迟,难以满足实时应用需求。为此,我们提出了 OmniForcing——首个将离线双流双向扩散模型蒸馏为高保真流式自回归生成器的框架。然而,若将因果蒸馏直接应用于此类双流架构,由于模态间极端的时序不对称性及其引发的令牌稀疏问题,将导致严重的训练不稳定。针对这一固有的信息密度差异,我们引入了具有零截断全局前缀的“非对称块因果对齐”(Asymmetric Block-Causal Alignment)机制,有效防止了多模态同步漂移。此外,针对因果转换过程中因音频令牌极度稀疏而引发的梯度爆炸问题,我们设计了配备恒等旋转位置编码(Identity RoPE)约束的“音频汇点令牌”(Audio Sink Token)机制予以解决。最后,通过“联合自强制蒸馏”(Joint Self-Forcing Distillation)范式,模型能够在长序列推理过程中动态自我校正由暴露偏差(exposure bias)引起的累积性跨模态误差。得益于模态无关的滚动键值缓存(KV-cache)推理方案,OmniForcing 在单张 GPU 上实现了约 25 FPS 的流式生成,达到业界领先水平,同时在多模态同步性与视觉质量上保持了与双向教师模型相当的表现。项目主页:https://omniforcing.com
一句话总结
京东探索研究院、复旦大学、北京大学和香港大学的研究人员提出了 OmniForcing,这是一个将双向音视频扩散模型蒸馏为实时流式生成器的框架。通过引入非对称块因果对齐和音频 Sink Token,该框架克服了训练不稳定性,在保持高保真同步的同时实现了 25 FPS 的生成速度。
主要贡献
- OmniForcing 通过将双向联合音视频扩散模型蒸馏为高保真流式自回归生成器,解决了其高延迟问题,从而支持实时应用。
- 该框架引入了带有零截断全局前缀的非对称块因果对齐,以及音频 Sink Token 机制,以解决由极端时间非对称性和 Token 稀疏性引起的训练不稳定性。
- 通过采用联合自强制蒸馏范式和模态无关的滚动 KV 缓存,该方法在单张 GPU 上实现了约 25 FPS 的最先进流式生成,同时保持了与教师模型相当的同步性和视觉质量。
引言
最近的联合音视频扩散模型(如 LTX-2)能够生成高保真的同步内容,但它们依赖于需要一次性处理整个时间线的双向注意力机制。这种架构导致了不可接受的延迟,阻碍了实时流式处理;而现有的变通方案要么通过解耦模态来降低质量,要么由于极端的 Token 稀疏性和时间非对称性,在应用于双流系统时无法稳定运行。作者提出了 OmniForcing,这是首个将离线双向模型蒸馏为高保真流式自回归生成器的框架。他们通过引入带有零截断全局前缀的非对称块因果对齐,以及配备 Identity RoPE 约束的音频 Sink Token 机制,解决了训练不稳定性问题。此外,联合自强制蒸馏范式使模型能够自我纠正累积误差,从而在单张 GPU 上实现了约 25 FPS 的最先进流式生成。
方法
作者利用双流 Transformer 骨干网络,实现了时间对齐的视频和音频的实时流式联合生成。如 OmniForcing 流程所示,整体框架将预训练的双向模型重构为块因果自回归系统。该过程涉及一个三阶段蒸馏流水线,旨在将教师模型的高保真联合分布转移至超快因果引擎。
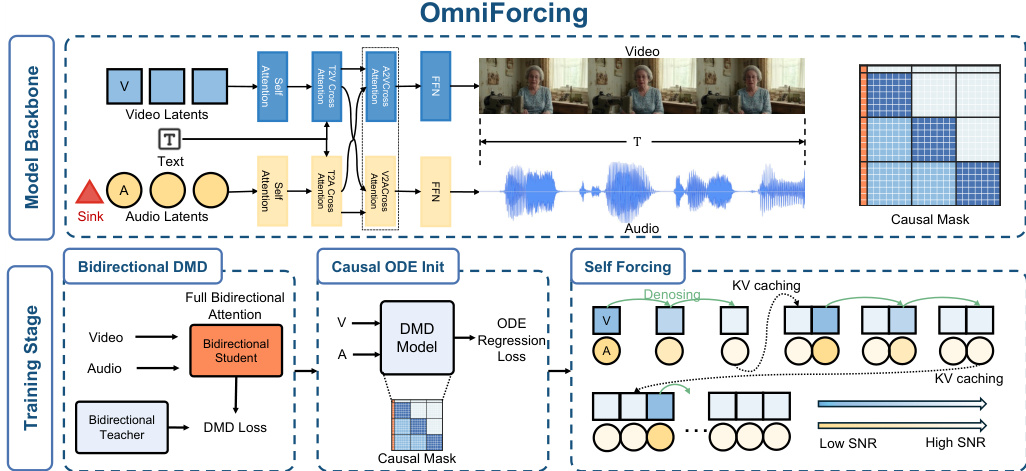
训练过程遵循顺序蒸馏范式,以平滑地将少步去噪与因果生成范式解耦。第一阶段采用双向分布匹配蒸馏(DMD),使模型适应少步去噪,同时保留全局感受野。第二阶段利用因果 ODE 回归,使网络权重适应非对称块因果掩码,校正条件分布偏移。最后,第三阶段通过自回归展开生成过程实施联合自强制训练,以减轻暴露偏差并确保跨模态同步。
为了解决视频(3 FPS)和音频(25 FPS)潜在变量之间极端的频率非对称性问题,该方法采用了非对称块因果掩码设计。这种方法通过建立基于物理时间的宏块对齐,弥合了信息密度差距。如下图所示,时间线被划分为 1 秒的宏块,其中每个块封装固定数量的视频和音频潜在变量,且没有分数余数。
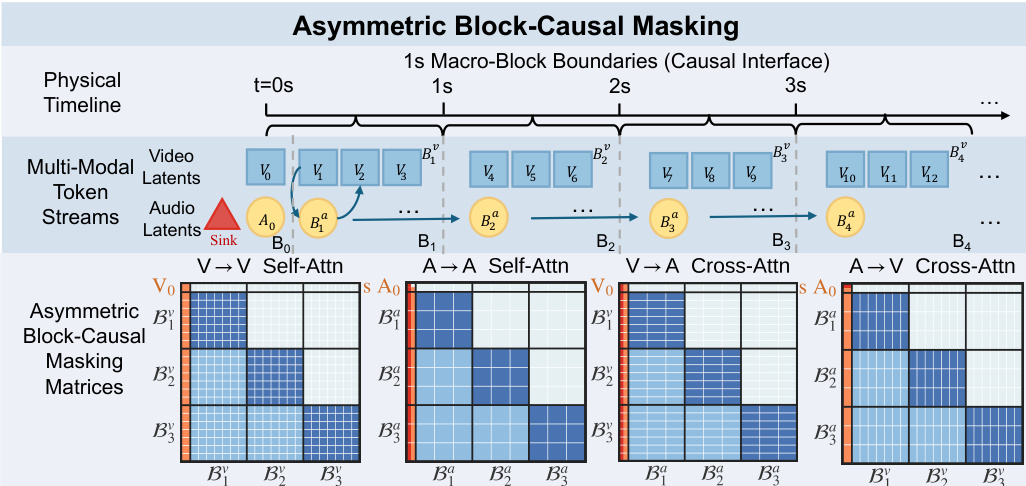
初始组件被合并为一个全局前缀块(B0),它充当系统提示,对所有未来 Token 全局可见。为了防止由早期音频块中的稀疏历史引起的梯度爆炸和 Softmax 坍塌,作者在音频序列前引入了可学习的 Sink Token。这些 Token 锚定在全局前缀内,并利用 Identity RoPE 约束以保持位置无关性。在推理过程中,该架构通过模态无关的滚动 KV 缓存支持非对称计算分配和并行推理,从而实现实时同步生成。
实验
- OmniForcing 针对双向和级联自回归基线进行了评估,以验证其实现高保真流式音视频生成并具备实时效率的能力。
- 该方法相比离线教师模型展现出显著的速度提升,实现了低延迟的真实流式播放,同时保持了与最强联合模型相当的视觉和音频质量。
- 定性分析证实,该模型成功生成了分层声音、同步语音以及与视觉事件精确对齐的复杂音频混合。
- 消融实验验证,音频 Sink Token 结合 Identity RoPE 对于在因果约束下稳定训练至关重要,而其他稳定方法则会导致收敛失败或输出质量下降。
- 总体而言,实验证实 OmniForcing 在保留原始双向教师模型的感知保真度和跨模态一致性的同时,大幅减少了推理时间。