Command Palette
Search for a command to run...
LMEB:长程记忆嵌入基准测试
LMEB:长程记忆嵌入基准测试
摘要
记忆嵌入(Memory Embeddings)对于增强型记忆系统(如 OpenClaw)至关重要。然而,当前的文本嵌入基准测试对记忆嵌入的评估尚显不足:这些基准大多局限于传统的段落检索任务,未能有效评估模型在处理长跨度记忆检索任务中的能力,而此类任务往往涉及碎片化、依赖上下文且时间跨度较大的信息。针对这一局限,我们提出了长跨度记忆嵌入基准(Long-horizon Memory Embedding Benchmark, LMEB)。LMEB 是一个综合评估框架,旨在系统性地衡量嵌入模型在应对复杂、长跨度记忆检索任务中的表现。该基准涵盖 22 个数据集和 193 个零样本检索任务,涉及四种记忆类型:情景记忆(episodic)、对话记忆(dialogue)、语义记忆(semantic)和程序性记忆(procedural),数据来源包括人工智能生成与人工标注。这四种记忆类型在抽象层级与时间依赖性方面存在显著差异,能够捕捉记忆检索的不同维度,从而反映现实世界中多样化的挑战。我们评估了 15 种广泛使用的嵌入模型,其参数量从数亿至百亿不等。实验结果表明:(1)LMEB 提供了合理且具挑战性的评估难度;(2)模型规模更大并不必然带来更优性能;(3)LMEB 与现有主流基准 MTEB 在评估维度上呈现正交性。这些发现表明,当前领域尚未收敛于一种能够在所有记忆检索任务中均表现卓越的通用模型,且传统段落检索任务中的性能未必能泛化至长跨度记忆检索场景。综上所述,LMEB 通过提供一个标准化、可复现的评估框架,填补了记忆嵌入评估领域的关键空白,有望推动文本嵌入技术在处理长期、上下文依赖型记忆检索任务方面的进一步发展。LMEB 项目代码已开源,访问地址为:https://github.com/KaLM-Embedding/LMEB。
一句话总结
来自哈尔滨工业大学和深圳环区研究所的研究人员推出了 LMEB,这是一个全面的基准测试,用于评估跨多种长时程检索任务的记忆嵌入能力。与传统基准测试不同,LMEB 揭示了更大的模型并不总是表现更优,突显了当前文本嵌入能力在复杂、依赖上下文的记忆场景中存在的关键差距。
主要贡献
- 当前的文本嵌入基准测试无法评估涉及碎片化、依赖上下文且时间跨度遥远的信息的长时程记忆检索,导致在评估记忆增强系统方面存在空白。
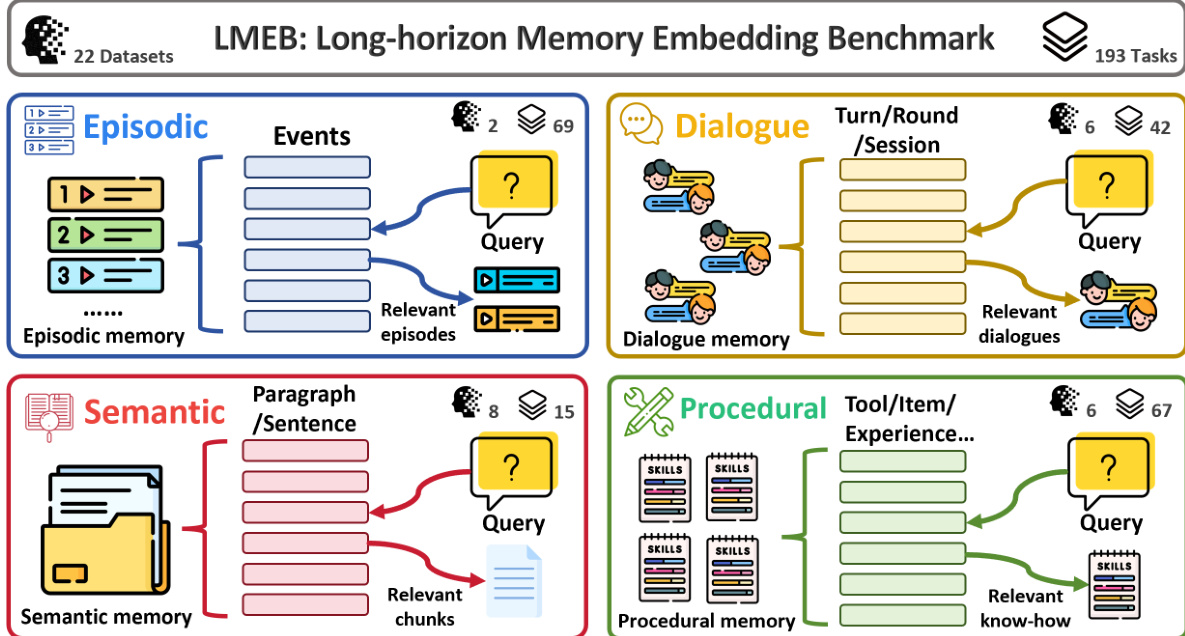
- 作者提出了长时程记忆嵌入基准(LMEB),这是一个涵盖 22 个数据集和 193 个零样本任务的综合框架,覆盖情景、对话、语义和程序性记忆类型。
- 对 15 种嵌入模型的评估显示,更大的模型并不总是优于较小的模型,且 LMEB 的性能与传统基准测试(如 MTEB)正交,表明该领域缺乏通用模型。
引言
文本嵌入模型对于实现高效的相似度搜索以及驱动检索和分类等下游应用至关重要,但当前的评估标准在评估其处理长时程记忆任务的能力方面存在不足。现有的基准测试主要关注句子级别的相似度或跨领域的标准检索,很少测试需要综合碎片化、依赖上下文且时间跨度遥远的证据的场景。为了填补这一空白,作者推出了 LMEB,这是一个专门的基准测试,旨在评估嵌入模型如何支持传统指标所忽视的复杂以记忆为中心的检索。
数据集
LMEB 数据集概览
作者推出了长时程记忆嵌入基准(LMEB),这是一个综合框架,旨在评估嵌入模型在复杂、长时程记忆检索任务上的表现,而传统基准测试(如 MTEB)未能涵盖这些任务。
-
数据集构成与来源
- 该基准将 22 个英文数据集整合为统一模式,涵盖 193 个零样本检索任务。
- 数据来源包括 AI 生成内容与人工标注材料的混合,后者源自众包、学术论文、小说和真实世界日志。
- 数据集被分为四种不同的记忆类型:情景记忆、对话记忆、语义记忆和程序性记忆。
-
各子集的关键细节
- 情景记忆:侧重于利用时间线索和空间线索回忆过去的事件,使用的数据集包括 EPBench(合成事件)和 KnowMeBench(自传体叙事)。
- 对话记忆:针对多轮上下文保留和用户偏好,使用来自 LoCoMo、LongMemEval、REALTALK 和 TMD 的长对话。
- 语义记忆:评估从科学论文(QASPER, SciFact)、小说(NovelQA)和报告(ESG-Reports)中检索稳定、通用知识的能力。
- 程序性记忆:评估技能和动作序列的检索能力,使用 API 文档(Gorilla, ToolBench)和任务轨迹(ReMe, DeepPlanning)。
-
在模型评估中的应用
- 作者利用整个集合进行零样本评估,即在不进行特定任务微调的情况下测试模型的预训练能力。
- 该基准作为诊断工具,用于衡量模型在不同抽象级别和时间依赖性下的性能。
- 结果表明,LMEB 与 MTEB 正交,表明在传统段落检索中的高性能并不能保证在长时程记忆任务中取得成功。
-
处理与构建细节
- 统一模式:所有资源均转换为标准的信息检索格式,包含
queries.jsonl、corpus.jsonl、qrels.csv以及可选的candidates.jsonl。 - 时间锚定:对于包含相对时间表达式的查询,作者附加了明确的时间锚点(例如,“当前时间:周日上午 11:17")以消除歧义。
- 元数据编码:时间戳和层级结构(如对话中的会话或轮次级别)保留在标题或文本字段中,以支持对时间敏感和特定范围的查询。
- 文本分段:语义任务中的长文档(如小说和 research papers)使用
semchunk等工具分段为段落或句子,块大小为 256 个 token。 - 候选约束:可选的候选文件将检索限制在特定的记忆范围内(例如,单次对话历史),而不是整个语料库。
- 统一模式:所有资源均转换为标准的信息检索格式,包含
方法
作者推出了长时程记忆嵌入基准(LMEB),以系统地评估跨多种场景的记忆能力。该框架将任务分为四种不同的记忆类型:情景、对话、语义和程序性。每种类型都涉及从特定记忆库中检索相关信息的查询。
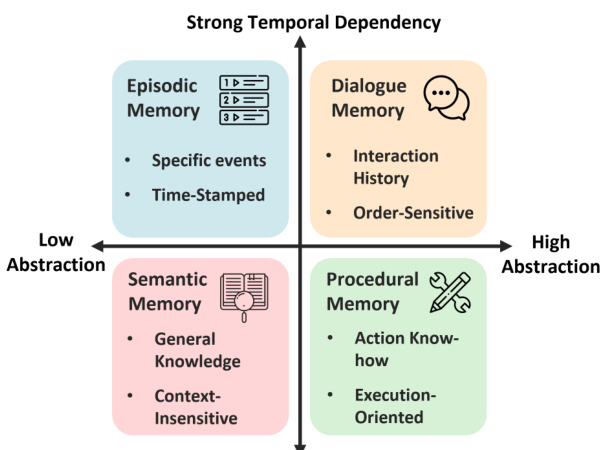
为了构建这些评估,作者定义了一个基于抽象程度和时间依赖性的分类法。如下图所示,情景和对话记忆表现出强烈的时间依赖性,而语义和程序性记忆在抽象级别上有所不同。
为了确保嵌入在下流任务中遵循指令,作者在查询前添加了特定的任务指令。指令化查询的公式如下:
qinst=Instruct: {task instruction} \nQuery: q
其中 q 表示原始查询,qinst 是指令化查询。该机制允许模型根据任务的具体要求调整其检索和处理方式。
实验
- LMEB 基准评估验证了一个统一的管道,用于测试跨情景、对话、语义和程序性记忆任务的嵌入模型,表明该基准提供了平衡的难度级别,能有效挑战当前模型。
- 比较不同规模模型的实验显示,更大的参数量并不能保证更优越的性能,因为较小的模型往往根据架构和训练数据的不同,能达到相当甚至更好的结果。
- 对任务指令的分析表明,其对检索性能的影响取决于模型,有些模型从指令中受益,而另一些模型在没有指令时表现更好或不受影响。
- 相关性研究证实,LMEB 评估的能力与传统基准测试(如 MTEB)正交,特别是表明在标准段落检索中的强性能并不能很好地泛化到复杂的情景或对话记忆场景。