Command Palette
Search for a command to run...
面向计算机使用智能体的基于视频奖励建模
面向计算机使用智能体的基于视频奖励建模
Linxin Song Jieyu Zhang Huanxin Sheng Taiwei Shi Gupta Rahul Yang Liu Ranjay Krishna Jian Kang Jieyu Zhao
摘要
计算机使用代理(Computer-Using Agents, CUAs)的能力日益增强,然而,如何可扩展地评估其执行轨迹是否真正满足用户指令,仍是一项严峻挑战。本文聚焦于基于执行视频(execution video)的奖励建模方法:该视频由代理执行轨迹中的关键帧序列构成,独立于代理的内部推理过程或具体操作。尽管视频执行建模具有方法无关性(method-agnostic),但其面临若干关键挑战,包括界面布局的高度冗余性,以及决定任务成败的细微、局部化线索。为此,我们构建了 Execution Video Reward 53k(ExeVR-53k)数据集,包含 53,000 组高质量的视频–任务–奖励三元组。进一步地,我们提出对抗性指令翻译(adversarial instruction translation)技术,用于合成带有步骤级标注的负样本。为支持从长时序、高分辨率执行视频中进行有效学习,我们设计了时空令牌剪枝(spatiotemporal token pruning)机制,在剔除同质区域与持久性令牌的同时,保留关键的界面变更事件。基于上述组件,我们微调出一个执行视频奖励模型(Execution Video Reward Model, ExeVRM)。该模型仅需输入用户指令与视频执行序列,即可预测任务是否成功。我们的 ExeVRM 8B 模型在视频执行评估任务上取得了 84.7% 的准确率与 87.7% 的召回率,在 Ubuntu、macOS、Windows 及 Android 等多个平台上,性能均优于 GPT-5.2、Gemini-3 Pro 等强大的专有模型,同时提供了更精确的时间归因能力。上述结果表明,基于视频执行的奖励建模可作为一种可扩展、方法无关的评估范式,为计算机使用代理提供可靠、高效的评估支持。
一句话总结
来自南加州大学、华盛顿大学、MBZUAI 和 Amazon AGI 的研究人员提出了 ExeVRM,这是一种视频执行奖励模型。该模型利用时空令牌剪枝和对抗性指令翻译技术,能够准确评估计算机使用代理(Computer-use Agents)在不同平台上的任务成功情况,其表现优于专有基线模型。
主要贡献
- 计算机使用代理缺乏独立于内部推理的可扩展评估方法,这促使研究转向基于视频的奖励建模,仅通过可观察的界面状态来评估任务成功与否。
- 作者引入了包含 53,000 个“视频 - 任务 - 奖励”三元组的 ExeVR-53k 数据集,并提出对抗性指令翻译以合成负样本,同时采用时空令牌剪枝策略,在过滤冗余视觉内容的同时保留决定性的 UI 变化。
- 他们的执行视频奖励模型(ExeVRM)在 ExeVR-Bench 上达到了 84.7% 的准确率和 87.7% 的召回率,在多个操作系统上超越了 GPT-5.2 和 Gemini-3 Pro 等强大的专有模型,同时在错误定位方面提供了更优的时间归因能力。
引言
计算机使用代理(CUAs)能够跨多种操作系统自动化复杂任务,但由于依赖脆弱且手工编写的脚本,难以扩展到新环境,导致评估其成功与否成为瓶颈。先前的方法难以应对界面布局的高度冗余以及标注失败案例的稀缺性,这使得训练能够检测决定任务完成的细微视觉线索的模型变得困难。作者通过引入 ExeVR-53k(一个大规模的视频 - 任务 - 奖励三元组数据集)来解决这些问题,并提出对抗性指令翻译技术,以合成具有步骤级标注的困难负样本。此外,他们开发了一种时空令牌剪枝策略,通过移除静态区域同时保留决定性的 UI 变化,从而高效处理长序列、高分辨率的执行视频。利用这些组件,他们训练了执行视频奖励模型(ExeVRM),该模型通过直接根据可观察的视频序列判断任务成功,而无需访问代理的内部推理,从而在准确率和召回率上优于专有模型。
数据集
ExeVR-53k 数据集概览
-
数据集构成与来源 作者推出了 ExeVR-53k,这是一个包含 53,000 个样本的训练语料库,旨在克服计算机使用奖励建模中的数据瓶颈。该数据集整合了三个主要来源的轨迹:AgentNet 和 ScaleCUA 提供人类监督的演示,而 OSWorld 则提供由 30 种不同的计算机使用代理生成的解决方案。这种组合确保了端到端和代理范式的覆盖范围,同时跨越了包括 Windows、macOS、Ubuntu、Android 和 Web 环境在内的多个操作系统。
-
各子集的关键细节
- OSWorld: 包含 361 个评估任务,专注于开放领域的 Web 和桌面应用程序。作者将来自 30 个不同代理系统(从 Claude 和 Gemini 等专有模型到开源权重研究模型)的 rollout 视为训练轨迹,以确保行为多样性。
- AgentNet: 贡献了 22,625 个由人类标注的任务,涵盖电子商务、办公工具和软件开发等 11 个子领域。数据分布在 Windows(12K)、macOS(5K)和 Ubuntu(5K)环境中。
- ScaleCUA: 提供了一个以 GUI 为中心的大规模数据集,覆盖 Linux、macOS、Windows、Android 和 Web 平台。它采用混合流水线,其中定位示例利用大语言模型(LLM)辅助自动收集并经人工验证,而轨迹数据则依赖人工交互日志并辅以 LLM 标注。
-
数据处理与视频构建 作者将原始交互记录转换为统一的步骤级视频表示。他们将每个轨迹分割为单个步骤,并为每个动作提取一个代表性关键帧(截图)以捕捉 UI 状态。这些帧按时间顺序拼接,生成以 1 FPS 渲染的紧凑视频摘要。该策略在保持交互进展的粗粒度视图的同时,使输入长度适合模型训练。
-
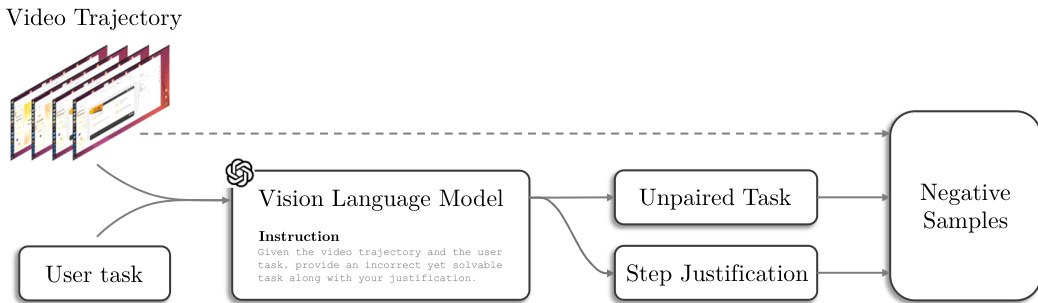
用于负样本的对抗性指令翻译 为了解决以演示为主的数据集中缺乏反例的问题,作者采用了一种对抗性指令翻译技术。他们提示视觉 - 语言模型为有效的轨迹片段生成看似合理但未配对的任務指令,从而创建视觉上相似但语义不一致的困难负样本。该模型还输出用于时间定位的论证和参考步骤。这些合成对经过人工验证,确保在纳入前质量审计通过率达到 100%。
-
评估基准 (ExeVR-Bench) 作者从 ExeVR-53k 的保留划分中构建了 ExeVR-Bench,包含 789 个实例,正负轨迹类别比例平衡。该基准包括来自 Ubuntu(代理和人类)、Mac/Win 和 Android 的任务。在评估中,所有视频均以 720p 渲染,最多采样 100 帧,帧率为 1 FPS。该数据集支持二元判断(正确与错误)和归因判断,后者需要识别首次错误发生的具体时间范围。
方法
作者提出了一个全面的框架,用于在计算机使用轨迹上训练视觉 - 语言模型,既解决了高分辨率视频输入带来的计算挑战,又确保了鲁棒的评估。核心方法论将高效的时空令牌剪枝机制与利用特定提示策略的结构化评估协议相结合。
时空令牌剪枝
训练计算机使用奖励模型通常需要高分辨率视频输入,以捕捉图标、光标和小文本等细粒度的 UI 元素。然而,处理全分辨率帧会耗尽令牌预算并导致内存使用量过高。为了缓解这一问题,作者引入了时空令牌剪枝,通过在空间和时间上丢弃冗余的视觉令牌来减少有效上下文长度。
训练过程(总结于算法 1)首先冻结视觉编码器 V 和投影器 P,仅训练 LLM 参数。对于每个训练样本 (X,V,Y),视频帧 V 被编码为补丁令牌 ZV。随后,系统应用两个剪枝阶段。首先,空间令牌剪枝(STP)构建每帧的 UI 连接图 G(t),其中节点代表补丁,边连接具有相似特征的空间邻居。识别连通分量,并剪枝超过大小阈值 τlarge 的大分量(可能是背景区域)。这生成了空间掩码 Ms。
其次,时间令牌剪枝(TTP)解决帧间的冗余问题。在 UI 密集的视频中,许多帧共享相同的布局,而任务相关的证据集中在瞬态变化中。TTP 为每个空间位置维护一个参考令牌 vi(ref),并初始化为第一帧。后续令牌使用余弦相似度 simcos(⋅,⋅) 与该参考进行比较。相似度高于阈值 τt 的令牌被剪枝,仅当遇到不同状态时才更新参考。这生成了时间掩码 Mt。
最终掩码 M 是 Ms 和 Mt 的逻辑与,确保仅当令牌在空间和时间上都显著时才予以保留。剪枝后的令牌被打包成更短的序列 ZV,投影到 LLM 输入空间,并通过奖励建模损失 Lrm 用于更新模型参数。
评估与奖励建模
为了评估代理性能并生成训练信号,该框架针对不同评估组件采用了专门的提示策略。这些提示引导模型分析用户意图、操作历史和 UI 状态,以确定任务是否成功。
对于动作评估奖励(AER)组件,系统使用结构化的提示格式。用户提示提供用户意图、操作历史和网页的最终快照。参考下方的用户提示示例:
相应的系统提示指示模型充当 GUI 代理的专家评估员。它定义了各种任务类型,如信息检索、导航和内容修改,并要求模型根据最终状态输出“成功”或“失败”状态。参考下方的系统提示详情:

此外,还采用了一种简化评估器(Simplified Judge)机制以提供更细粒度的反馈。该组件的用户提示指定了用户目标和代理执行的操作序列,包括步骤编号、动作和推理。参考下方的用户提示结构:

简化评估器的系统提示要求模型回答关于代理性能的四个具体问题:序列是否成功、是否执行了不必要的操作、任务是否以最优方式执行,以及代理是否在无进展的情况下陷入循环。参考下方的系统提示指令:

最后,该框架集成了 ZeroGUI 提示策略,强调对截图进行详细分析以识别错误和 UI 变化。该提示指示模型分析每张截图,提供关于最终状态的整体推理,并输出分数。参考下方的 ZeroGUI 提示示例:

这种多面的评估方法确保模型在任务执行的结果和过程方面都能获得详细的反馈。例如,在分析特定步骤时,模型会检查上下文菜单和悬停状态等细节以确定意图。参考下方的截图分析示例:

实验
- 主要性能评估表明,在计算机使用轨迹上训练视频奖励模型,在偏好建模和时间归因方面优于提示通用视觉 - 语言模型或使用稀疏快照基线。
- 消融研究证实,密集视频上下文显著优于仅依赖初始或最终截图的方法,因为忽略因果过渡会阻碍准确的任务完成判断。
- 实验显示,更高的输入分辨率(720p)保留了奖励预测所需的细粒度 GUI 线索,而时空令牌剪枝使得高分辨率长视野训练在计算上可行。
- 对剪枝策略的分析表明,对于捕捉决定性的状态转换,时间剪枝比空间剪枝更为关键,而结合两种方法可以优化准确率、召回率和训练效率之间的权衡。
- 可视化结果验证了所提出的剪枝方法能有效移除冗余的静态元素,同时保留细微的、与任务相关的证据,如瞬态对话框和局部 UI 变化。