Command Palette
Search for a command to run...
InCoder-32B:面向工业场景的代码基础模型
InCoder-32B:面向工业场景的代码基础模型
摘要
近期,代码大语言模型(LLM)在通用编程任务上取得了显著进展。然而,在需要推理硬件语义、处理专用语言结构以及满足严格资源约束的工业场景中,其性能会出现显著下降。为应对这些挑战,我们推出了 InCoder-32B(Industrial-Coder-32B),这是首个统一芯片设计、GPU 内核优化、嵌入式系统、编译器优化及 3D 建模等多领域代码智能的 32B 参数代码基础模型。通过采用高效架构,我们从零开始训练 InCoder-32B:首先进行通用代码预训练,随后利用精选的工业代码进行退火(annealing)微调;接着,通过引入合成工业推理数据,在中期训练中逐步将上下文长度从 8K tokens 扩展至 128K tokens;最后,结合基于执行验证的后训练阶段进一步优化模型。我们在 14 个主流通用代码基准测试和涵盖 4 个专业领域的 9 个工业基准测试上进行了广泛评估。结果表明,InCoder-32B 在通用任务上展现出极具竞争力的性能,同时在各个工业领域建立了强有力的开源基准。
一句话总结
来自北京航空航天大学与 IQest 研究院的研究人员推出了 InCoder-32B,这是一个统一的 320 亿参数基础模型。该模型通过渐进式上下文扩展和基于执行的验证,克服了工业级编码中的硬件限制,为芯片设计和 GPU 优化建立了新的开源基准。
主要贡献
- 本文介绍了 InCoder-32B,这是一个 320 亿参数的基础模型,通过专门的三阶段训练流程,统一了芯片设计、GPU 内核优化、嵌入式系统、编译器优化和 3D 建模等领域的代码智能。
- 构建了一套全面的评估套件,包含 14 个通用代码基准和 9 个涵盖四个专业领域的工业基准,以严格评估硬件感知编程场景下的性能。
- 广泛的消融研究表明:仓库迁移数据提升了规划能力,中期训练中的推理轨迹增强了分布偏移下的鲁棒性,而思维路径则解锁了标准指令微调中缺失的涌现能力。
引言
代码大语言模型在通用软件任务中表现出色,但在需要推理硬件语义、专用语言结构以及严格资源限制的工业场景中却面临挑战。先前的工作往往在芯片设计或 GPU 优化等孤立领域解决这些问题,导致解决方案碎片化,无法统一更广泛工业工程领域的各项能力。作者推出了 InCoder-32B,这是首个旨在弥合这一差距的 320 亿参数基础模型,它统一了芯片设计、GPU 内核优化、嵌入式系统、编译器优化和 3D 建模的代码智能。通过一个三阶段训练流程,该模型融合了精心策划的工业数据、渐进式上下文扩展(最高达 128K token)以及基于执行的验证,以确保硬件感知的正确性。
数据集
数据集构成与来源
作者构建了一个专门的工业代码数据集,以解决通用语料库中硬件和低层系统数据稀缺的问题。数据主要来源于三个方面:
- 公共仓库: 采用三步召回策略,利用基于规则的过滤、FastText 分类和领域自适应语义编码器检索代码,以捕获 Verilog、CUDA 和嵌入式 C 代码。
- 技术文献: 通过光学字符识别(OCR)从硬件参考手册和技术书籍中提取代码片段和结构化内容。
- 领域特定网络数据: 收集包括工程报告、厂商文档和技术论坛内容,以捕获实际使用模式。
各子集的关键细节
数据集按四个工业领域(数字电路设计、GPU 计算、嵌入式系统和 CAD 自动化)组织为精心策划和合成两部分。
- 精心策划的工业代码: 包含真实的代码提交、文件级“中间填充”(FIM)样本,以及测试平台、时序约束和性能分析日志等辅助工件。
- 合成工业问答(QA): 通过三阶段流程生成,包括工程师制定场景规范、种子代码生成以及自动化验证,以确保事实正确性。
- 智能体轨迹: 遵循“思考 - 行动 - 观察”循环的多步调试和修复序列,捕获来自仿真器和编译器的反馈。
- 后训练监督微调(SFT)样本: 包含 250 万个样本,分为直接解决方案、缺陷修复和性能优化,所有样本均基于真实的执行环境。
模型使用与训练策略
作者利用这些数据在三个不同的训练阶段构建 InCoder-32B 模型。
- 阶段 1(预训练): 模型在精心策划的工业代码上进行训练,采用自回归语言建模和中间填充(FIM)补全,使用 4,096 个 GPU。
- 阶段 2(中期训练): 作者将合成推理数据与精心策划的工件混合。在第一子阶段,合成 QA 对占混合数据的 40%,随后是智能体轨迹(20%)、代码提交(15%)、工件(15%)和 FIM 数据(10%)。第二子阶段转向长上下文数据,将智能体轨迹比例提升至 30%,FIM 数据提升至 25%。
- 阶段 3(后训练): 模型使用 250 万个经过执行验证的样本进行监督微调(SFT),训练约 4,900 步。此阶段侧重于学习完整的工程工作流,包括调试和优化,而不仅仅是代码生成。
处理与验证细节
为确保高保真度,作者实施了严格的处理和验证流程,以模拟现实世界的工程工作流。
- 清洗与优化: 流程过滤许可证和个人身份信息(PII),在多个层级(哈希、Token、仓库)去除重复项,并规范化格式。所有样本均经过抽象语法树(AST)比较和重新编译以验证正确性。
- 仿真环境: 作者在软件中重建了四个工业环境以验证数据。这包括用于嵌入式固件的 STM32F407 微控制器仿真器(Renode)、用于汇编优化的原生 x86-64 执行、用于 Verilog 的 RTL 仿真以及用于几何生成的 CAD 脚本执行。
- 基于执行的验证: SFT 数据集中的每个候选解决方案都通过实际编译、仿真或测试执行进行验证。失败的解决方案会与编译器错误和运行时日志配对,以创建闭环修复轨迹。
- 元数据构建: 作者添加了结构化注释,包括跨文件依赖关系、平台约束和自然语言描述,以使代码与文本对齐。
方法
作者开发了 InCoder-32B,这是一个专为工业代码智能设计的仅解码器 Transformer 架构。训练过程分为三个 distinct 阶段:预训练、中期训练和后训练,如下面的框架图所示。
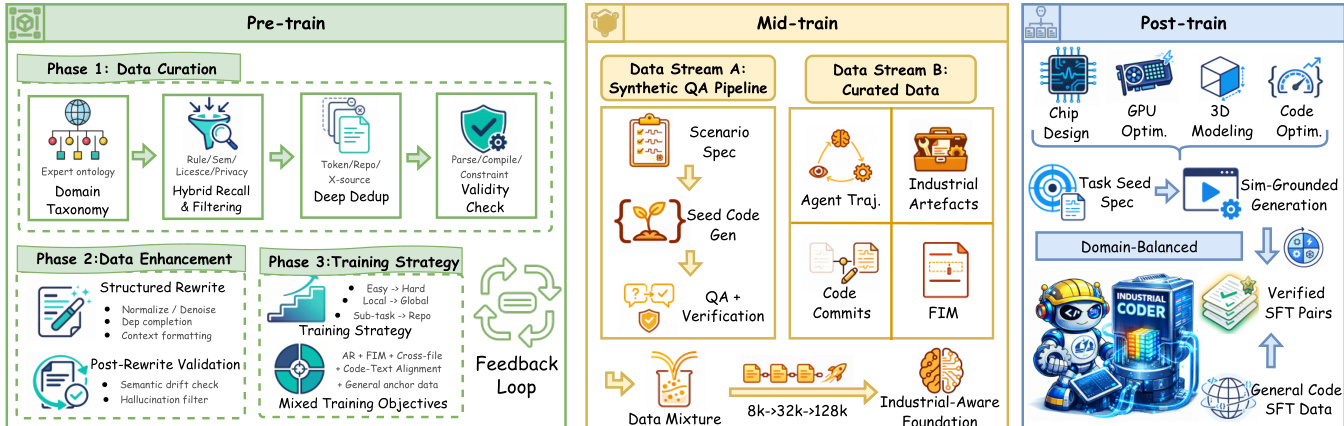
在预训练阶段,作者专注于数据策划、数据增强和训练策略。数据策划涉及建立领域分类法、应用混合召回和过滤规则、执行深度去重以及进行有效性检查。数据增强包括结构化重写以归一化和去噪代码,随后进行重写后验证以检查语义漂移。训练策略采用从易到难任务、从局部到全局上下文的课程学习,利用混合训练目标,包括自回归建模和中间填充(FIM)补全。
中期训练阶段对于扩展模型能力至关重要。它利用两个数据流:合成 QA 流程和精心策划的数据。合成 QA 流程生成场景规范、种子代码和带有验证的 QA 对。精心策划的数据流包括智能体轨迹、工业工件、代码提交和 FIM 数据。此阶段的一个关键组件是渐进式上下文扩展策略,将上下文窗口从 8K 增加到 32K token,最终达到 128K token。这使得模型最初能够处理文件级任务,随后解锁长上下文能力以进行扩展调试和多文件重构。
在后训练阶段,模型使用领域平衡的数据进行监督微调(SFT)。这包括任务种子规范和基于仿真的生成,以产生经过验证的 SFT 对。该过程确保模型准备好应对特定的工业领域,如芯片设计、GPU 优化、3D 建模和代码优化。
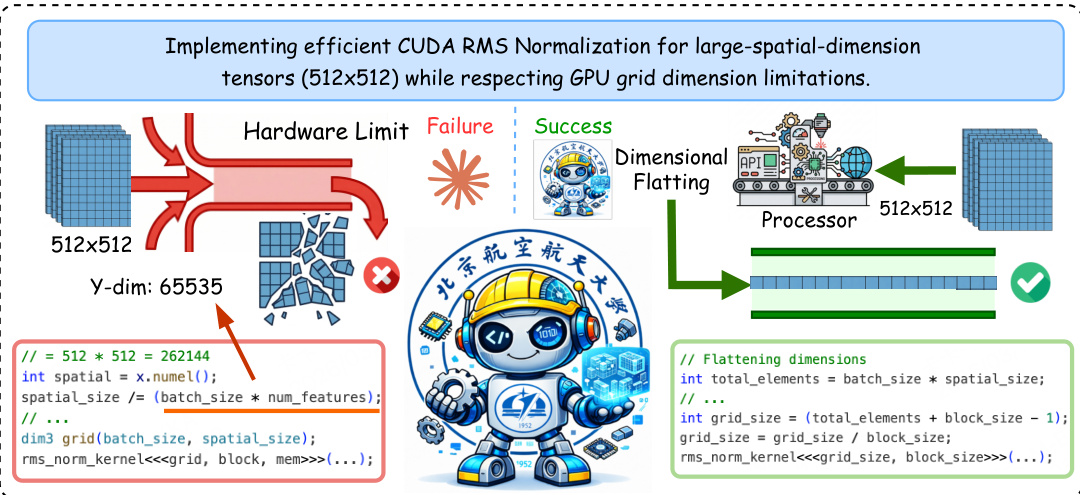
为了确保在工业环境中的实用性,作者复现了现实世界的工程环境。例如,在 GPU 优化中,当标准网格维度超出限制时,系统通过采用维度扁平化技术来处理硬件限制。这在针对大空间维度张量的高效 CUDA RMS 归一化实现中得到了证明,系统成功规避了硬件限制并生成了有效代码。
整体能力覆盖范围包括通用代码智能和工业代码智能,确保模型在各个领域具有通用性。

流程中集成了反馈驱动的修复机制。当生成的候选方案未能通过验证(例如编译错误或仿真不匹配)时,系统会捕获完整的反馈上下文,包括错误消息和日志。该反馈被反馈回生成阶段以生成修复版本,从而创建闭环修复轨迹,教导模型诊断故障并迭代直至修复。
实验
- 通用代码基准测试验证了 InCoder-32B 在代码生成、推理和 Text2SQL 任务中,与规模大得多的开源权重和专有模型相比具有竞争力,同时在智能体编码和工具使用评估中在开源权重基准中排名第一。
- 工业代码基准测试表明,该模型在芯片设计、GPU 内核优化和 3D 建模方面优于所有开源权重竞争对手,并超越了领先的专有系统,在硬件受限领域建立了强大的能力。
- 错误分析显示,虽然模型能很好地处理广泛的领域词汇,但在精确的工业语法、特定 API 约束和深层功能逻辑方面仍存在困难,特别是在需要复杂硬件语义或性能优化的场景中。
- 扩展研究证实,增加工业监督微调数据的数量 consistently 提高了大多数基准测试的性能,表明更大的数据集能有效增强架构推理和编码能力。
- 消融研究结果强调,仓库迁移数据、中期训练推理轨迹和显式思维路径对于在工业背景下开发稳健的规划信号和涌现推理能力至关重要。