Command Palette
Search for a command to run...
ShotVerse:推动文本驱动多镜头视频创作中的电影级相机控制进展
ShotVerse:推动文本驱动多镜头视频创作中的电影级相机控制进展
Songlin Yang Zhe Wang Xuyi Yang Songchun Zhang Xianghao Kong Taiyi Wu Xiaotong Zhao Ran Zhang Alan Zhao Anyi Rao
摘要
基于文本的视频生成技术虽已推动电影创作的大众化,但在多镜头电影场景中实现精准的镜头控制仍是一个重大瓶颈。隐式文本提示缺乏精确性,而显式的轨迹条件设定不仅带来高昂的人工成本,还常导致现有模型执行失败。为突破这一瓶颈,我们提出一种以数据为中心的范式转变,认为对齐的(描述、轨迹、视频)三元组构成了内在的联合分布,能够连接自动化轨迹规划与精确执行。基于这一洞见,我们提出了 ShotVerse——一种“先规划后控制”的框架,将生成过程解耦为两个协同工作的智能体:一个基于视觉 - 语言模型(VLM)的规划器,利用空间先验知识从文本中生成具有电影质感且全局对齐的镜头轨迹;以及一个控制器,通过相机适配器将这些轨迹渲染为多镜头视频内容。本方法的核心在于构建坚实的数据基础:我们设计了一套自动化的多镜头相机校准流程,将分散的单镜头轨迹对齐至统一的全局坐标系。此举促成了 ShotVerse-Bench 的构建,这是一个高保真电影数据集,并配套三轨评估协议,为本框架奠定了坚实基础。大量实验表明,ShotVerse 有效弥合了不可靠的文本控制与劳动密集型的人工轨迹规划之间的鸿沟,在实现卓越电影美学表现的同时,生成了既具备镜头精度又保持跨镜头一致性的多镜头视频。
一句话总结
香港科技大学与腾讯视频 AI 中心的 researchers 提出了 ShotVerse,这是一个“先规划后控制”(Plan-then-Control)框架,利用基于视觉语言模型(VLM)的规划器自动实现电影级轨迹生成。通过引入新颖的校准流程和 ShotVerse-Bench 数据集,该框架无需手动绘制轨迹即可实现精确、一致的多镜头视频创作。
主要贡献
- 当前的文本驱动视频生成方法在多镜头场景中难以实现精确的相机控制,这归因于隐式提示的精度不足以及显式轨迹条件设置带来的高昂人工成本。
- ShotVerse 引入了“先规划后控制”框架,将生成过程解耦为:基于 VLM 的规划器(用于自动绘制电影级轨迹)和控制器(用于精确渲染多镜头视频)。
- 作者通过设计自动化校准流程构建了 ShotVerse-Bench 高保真数据集,奠定了数据基础,使该框架能够实现卓越的相机精度和跨镜头一致性。
引言
文本驱动的视频生成已赋能用户创作电影级内容,但在多镜头场景中控制相机运动仍是一个主要障碍。先前的方法要么受限于隐式文本提示的不精确性,要么面临显式轨迹条件设置带来的巨大人工投入和执行失败风险。为解决这些挑战,作者提出了 ShotVerse,这是一个“先规划后控制”框架,将电影级规划与视频合成解耦。他们利用视觉语言模型作为规划器,根据文本描述自动生成统一的 3D 相机轨迹,并利用控制器基于这些精确路径渲染高保真多镜头视频。本工作的核心在于构建了 ShotVerse-Bench 数据集,该数据集包含通过自动化校准流程对齐到全局坐标系的独立镜头,使模型能够学习专业电影摄影所需的空间逻辑。
数据集
-
数据集构成与来源:作者推出了 ShotVerse-Bench,这是一个旨在将语义描述与全局统一相机轨迹对齐的数据集。该数据集包含 20,500 个片段,源自高制作水准的电影,以确保符合专业电影摄影标准并实现相机控制分类的平衡。
-
各子集的关键细节:
- 多镜头序列:训练子集包含 1,000 个场景,测试子集包含 100 个场景,两者无重叠。
- 结构:这些场景由将 2,750 个具有代表性的单镜头片段分组形成,每组包含 249 帧。
- 镜头分布:每个多镜头场景包含 2、3 或 4 个镜头,分布比例为 6:3:1。
-
数据使用与处理:
- 预处理:作者移除了内嵌字幕,并将所有视频分辨率标准化为 843 × 480 像素。
- 训练划分:1,000 个场景用于模型训练,剩余的 100 个场景作为测试集。
-
校准与对齐策略:为了将独立的单镜头轨迹统一到全局坐标系中,作者采用了一个四步流程:
- 动态前景移除:使用 SAM 对前景物体进行掩膜处理,仅保留静态背景区域以进行鲁棒的姿态估计。
- 局部重建:利用 PI3 在静态背景上对每个镜头进行独立重建,以生成局部一致的轨迹。
- 全局重建:对独立镜头中的关键帧进行采样,并通过 PI3 联合重建,以生成统一的静态场景和全局姿态。
- 基于锚点的对齐:作者识别在局部和全局重建中均存在的锚点帧,以估计相似变换。这将局部帧对齐到全局系统,并通过比较起始和结束关键帧的相对位移来解决尺度模糊问题。
方法
作者提出了 ShotVerse,这是一个旨在将多镜头相机控制任务解耦为独立规划和控制阶段的框架。这种“先规划后控制”架构通过建模由描述、轨迹和视频组成的对齐三元组的联合分布,弥合了不可靠的文本相机控制与劳动密集型手动绘图之间的差距。整体工作流程如下图所示,该图概述了三个核心组件:数据集构建、用于轨迹绘制的规划器以及用于轨迹注入的控制器。
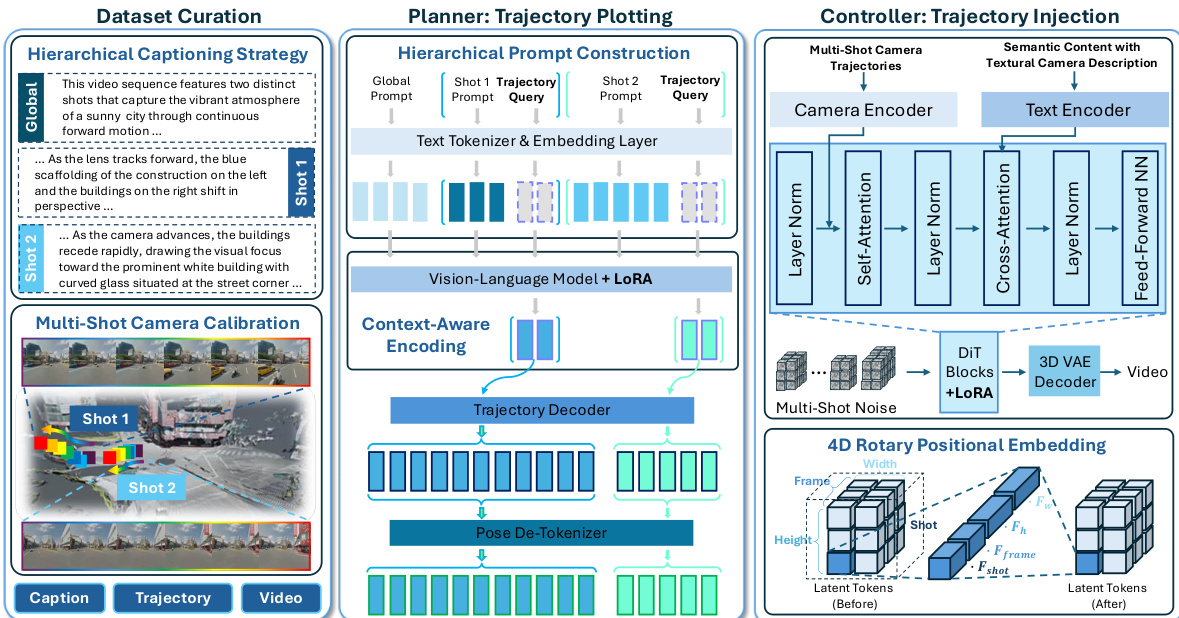
数据集构建 该框架的基础依赖于一个经过精心构建的数据集,其中多镜头轨迹通过相机校准对齐到统一的全局坐标系。此过程将视觉数据与分层描述配对,包括全局描述和特定的每镜头叙事,确保模型学习语义内容与几何相机运动之间的关系。
规划器:轨迹绘制 规划器模块负责根据分层文本描述合成电影级、全局统一的轨迹。其运作方式是建模条件概率 P(Trajectory∣Caption)。该过程始于分层提示构建,其中输入序列将全局提示与每镜头提示及可学习的轨迹查询令牌交错排列。这些令牌充当占位符,供视觉语言模型(VLM)填充特定于镜头的相机计划。
经过 LoRA 微调的 VLM 骨干网络执行上下文感知编码。通过自注意力机制,轨迹查询令牌的隐藏状态聚合来自全局上下文和先前镜头的信息。这些编码表示(称为相机代码)随后被传递给轨迹解码器。该解码器将固定数量的相机代码扩展为可变长度的轨迹令牌序列。最后,姿态去令牌化器将这些生成的令牌映射回连续值,在统一的全局坐标系中恢复显式相机姿态。规划器进行端到端训练,以最大化真实轨迹令牌的似然对数。
控制器:轨迹注入 控制器模块通过建模 P(Video∣Caption,Trajectory),将绘制的轨迹渲染为高保真多镜头视频。它利用整体扩散 Transformer(DiT)骨干网络。为了确保严格遵循相机路径,作者实现了一个相机编码器,将每一帧的外参矩阵投影为特征向量。该相机嵌入在自注意力层之前直接添加到中间视觉特征中,从而在不破坏预训练先验的情况下强制几何一致性。
为了处理多镜头视频的分层时间结构,该架构采用了 4D 旋转位置嵌入策略。与标准的 3D 嵌入不同,该方法将注意力头维度划分为四个子空间,分别对应镜头索引、帧索引、高度和宽度。这明确告知模型镜头边界,在保持细粒度时间动态的同时强制镜头内的一致性。控制器使用流匹配(Flow Matching)目标进行优化,预测在文本和相机嵌入条件下,清洁视频潜在变量与高斯噪声样本之间的速度场。
实验
- 建立了一个三轨评估协议,以评估文本到轨迹规划、轨迹到视频执行保真度以及端到端多镜头生成质量,解决了电影视频创作缺乏系统性基准的问题。
- 提出的规划器通过利用视觉语言先验,更好地将复杂叙事提示与相机序列对齐,从而优于现有的轨迹生成方法。
- 与单镜头基线相比,控制器表现出更优越的执行保真度和跨镜头一致性,有效维持了剪辑间的主体朝向和几何对齐。
- 端到端结果表明,集成系统在时间连贯性和美学质量方面均优于开源和商业模型,后者往往在没有显式几何指导的情况下无法执行复杂的相机运动。
- 消融研究证实,VLM 编码器、专用轨迹解码器、4D 位置编码和统一相机校准是实现稳定镜头过渡和电影级节奏的关键组件。
- 在真实电影数据而非合成三元组上进行训练,对于保持最终输出的视觉质量和时间稳定性至关重要。