Command Palette
Search for a command to run...
MiroThinker-1.7 与 H1:迈向基于验证的重型研究 Agent
MiroThinker-1.7 与 H1:迈向基于验证的重型研究 Agent
摘要
我们提出了 MiroThinker-1.7,这是一款专为复杂长周期推理任务而设计的新型研究智能体(research agent)。在此基础上,我们进一步推出了 MiroThinker-H1,通过引入重型推理能力,显著增强了其在多步问题求解中的可靠性。具体而言,MiroThinker-1.7 通过一个强调结构化规划、上下文推理与工具交互的智能体中期训练(agentic mid-training)阶段,提升了每一步交互的可靠性,从而实现了在复杂任务中更高效的多步交互与持续推理。MiroThinker-H1 则进一步将验证机制直接嵌入推理过程,涵盖局部与全局两个层面:在推理过程中,中间推理决策可被实时评估与优化;同时,整体推理轨迹接受审计,以确保最终答案由连贯的证据链支撑。在涵盖开放网络研究、科学推理及金融分析等多个基准测试中,MiroThinker-H1 在深度研究任务上达到了最先进(state-of-the-art)的性能,同时在专业领域也保持了强劲的表现。此外,我们已开源 MiroThinker-1.7 及其精简版 MiroThinker-1.7-mini,为研究社区提供了具备高度竞争力且效率显著提升的研究智能体能力。
一句话总结
MiroMind 团队推出了 MiroThinker-1.7 和 MiroThinker-H1,这是两款研究智能体,它们通过智能体中期训练(agentic mid-training)和一种新颖的以验证为核心的推理模式,优先优化交互扩展的有效性而非轨迹长度。这些模型通过审计中间步骤和全局证据链,确保可靠的长视野问题解决能力,从而在复杂深度研究、科学分析和金融分析领域实现了最先进的性能。
主要贡献
- 本文介绍了 MiroThinker-1.7,这是一款研究智能体,它通过强调结构化规划、上下文推理和工具交互的智能体中期训练阶段,提升了步骤级的可靠性。这种方法实现了更有效的多步问题解决,并减少了复杂任务所需的推理轮次。
- 本文提出了一种名为 MiroThinker-H1 的重型推理模式,该模式在局部和全局层面集成了验证机制,以评估中间决策并审计整体推理轨迹。这种设计允许系统在推理过程中优化动作,并确保最终答案由连贯的证据链支持。
- 该工作开源了 MiroThinker-1.7 和 MiroThinker-1.7-mini 模型,它们在保持高效率的同时,在深度研究基准测试中达到了最先进的性能。在开放网络研究、科学推理和金融分析方面的实验结果表明,这些模型优于现有的开源和商业研究智能体。
引言
科学分析和金融研究等现实世界任务需要能够执行长推理链并收集、验证外部信息的 AI 系统。当前的智能体框架往往难以奏效,因为单纯增加交互步骤的数量往往会累积错误并降低解决方案质量,而非提高可靠性。作者通过引入 MiroThinker-1.7 和 MiroThinker-H1 解决了这一问题,它们通过一个专门的中期训练阶段优先优化有效的交互扩展,该阶段加强了原子规划能力和工具使用技能。此外,它们还通过一种重型验证模式增强了可靠性,该模式在局部和全局层面审计推理步骤,以确保最终答案由连贯的证据链支持。
数据集
- 作者利用基于语料库的管道构建数据集,该管道源自维基百科和 OpenAlex 等高度互联的源,同时保留了超链接拓扑结构。
- 对于每个种子文档,该过程通过内部超链接采样连接的子图,提取跨文档的事实陈述,并提示强大的大语言模型合成多跳问答对。
- 这种方法生成了具有高吞吐量和广泛覆盖的数据,利用提示驱动的多样化和混淆来诱导不同的问题形式和推理模式。
- 该数据集缺乏明确的难度控制或推理深度的结构性强制,且在生成过程中未系统性地管理信息泄露。
方法
作者围绕迭代智能体 - 环境交互循环设计了 MiroThinker-1.7。该框架扩展了 ReAct 范式,采用由外部回合循环和内部步骤循环组成的双循环结构。在回合 e 内,智能体累积包含思考、动作和观察的轨迹日志 Ht(e)。为了在固定的令牌预算内管理上下文,上下文算子 Φt 应用滑动窗口过滤和结果截断。具体而言,智能体保留最近的 K 个步骤,同时屏蔽较旧的观察结果,确保有效上下文 Ct(e) 保持可控。如果一个回合在耗尽回合预算后仍未得出有效答案,系统将触发回合重启,丢弃先前状态以避免偏差。
该框架集成了模块化工具接口,将智能体与外部世界连接起来。如下图所示:
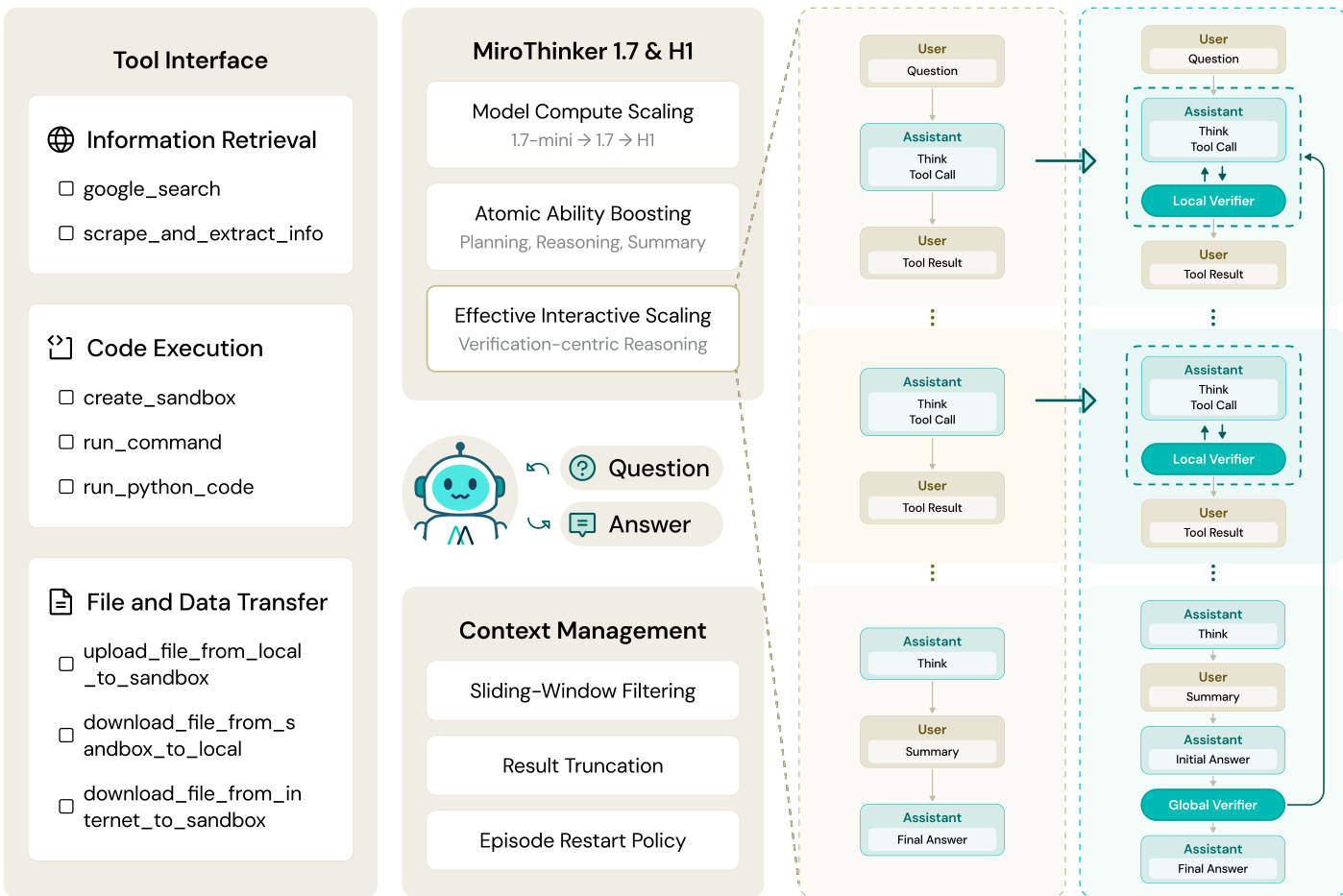 该接口涵盖信息检索(搜索和抓取)、代码执行(沙盒化的 Python 和 Shell 命令)以及文件传输工具。对于 MiroThinker-H1 变体,架构采用以验证为核心的推理方案,包含局部验证器和全局验证器,分别用于审计步骤级和完整的推理过程。
该接口涵盖信息检索(搜索和抓取)、代码执行(沙盒化的 Python 和 Shell 命令)以及文件传输工具。对于 MiroThinker-H1 变体,架构采用以验证为核心的推理方案,包含局部验证器和全局验证器,分别用于审计步骤级和完整的推理过程。
为了支持训练,作者采用双管道问答合成框架。基于语料库的管道通过从精选语料库中采样子图来生成大量问答对,从而关注主题广度。同时,WebHop 管道利用网络增强扩展和分层验证构建校准的推理树。该管道通过通过实时网络搜索扩展根实体并应用自适应叶子混淆以防止答案泄露,确保了推理的严谨性。
数据合成过程如下图所示:
 这种方法使模型能够从结构化的知识图谱以及多样化的现实世界网络内容中学习。
这种方法使模型能够从结构化的知识图谱以及多样化的现实世界网络内容中学习。
训练过程遵循一个旨在逐步增强智能体能力的四阶段管道。首先,中期训练通过大量智能体监督语料库加强原子智能体能力,如规划、推理和工具使用。其次,监督微调使模型能够通过复制专家轨迹来学习结构化的智能体交互行为。第三,偏好优化使模型的决策与任务目标和行为偏好保持一致。最后,强化学习利用组相对策略优化(GRPO)促进创造性探索,并提高在现实世界环境中的泛化能力。
这些训练阶段的进展如下图所示:
 在强化学习期间,作者实施了一种有针对性的熵控制机制,以维持策略稳定性并防止优化过程中过早的熵崩溃。
在强化学习期间,作者实施了一种有针对性的熵控制机制,以维持策略稳定性并防止优化过程中过早的熵崩溃。
实验
- 智能体基准测试验证了 MiroThinker 在多步网络浏览、信息检索和推理方面达到了最先进的性能,在 Humanity's Last Exam 和 GAIA 等任务上超越了领先的商业模型。
- 专业领域评估确认了其在特定领域的强大能力,该模型在科学推理、金融分析和医学综合方面优于前沿系统。
- 长篇幅报告评估展示了卓越的报告质量和事实依据,证明了该模型在综合复杂信息以应对深度研究查询方面的有效性。
- 交互扩展实验表明,提高单个推理步骤的质量比单纯增加交互轮次能带来更好的结果,从而以更少的步骤实现更高的性能。
- 以验证为核心的消融研究表明,局部和全局验证器通过纠正错误的推理路径和减少冗余交互,显著提升了在困难子集和搜索密集型任务上的性能。