Command Palette
Search for a command to run...
daVinci-Env:大规模开源软件工程环境合成
daVinci-Env:大规模开源软件工程环境合成
摘要
培养具备强大能力的软件工程(SWE)智能体,需要大规模、可执行且可验证的训练环境,以提供动态反馈回路,支持迭代式代码编辑、测试执行与方案优化。然而,现有的开源数据集在规模与仓库多样性方面仍显不足,而工业界解决方案则因基础设施未公开而缺乏透明度,这为大多数学术研究团队构成了难以逾越的障碍。为此,我们提出 OpenSWE:目前规模最大、完全透明的 Python 领域 SWE 智能体训练框架。该框架包含 45,320 个可执行的 Docker 环境,覆盖超过 12,800 个代码仓库;所有 Dockerfile、评估脚本及基础设施均已开源,以确保结果可复现。OpenSWE 基于部署在 64 节点分布式集群上的多智能体合成流水线构建,实现了仓库探索、Dockerfile 构建、评估脚本生成以及迭代式测试分析的自动化。除规模优势外,我们进一步提出以质量为核心的过滤流水线,用于刻画各环境的固有难度,剔除不可解或挑战性不足的实例,仅保留能最大化学习效率的高质量样本。该项目在环境构建上投入约 89.1 万美元,在轨迹采样与难度感知筛选方面额外投入 57.6 万美元,总投资额约为 147 万美元,最终从约 9,000 个质量保障环境中提炼出约 13,000 条精心筛选的训练轨迹。大量实验验证了 OpenSWE 的有效性:OpenSWE-32B 与 OpenSWE-72B 在 SWE-bench Verified 基准上分别取得 62.4% 和 66.0% 的准确率,在 Qwen2.5 系列模型中达到当前最优(SOTA)水平。此外,面向软件工程任务的训练还带来了显著的跨领域性能提升:在数学推理基准上最高提升达 12 个百分点,在科学类基准上提升 5 个百分点,且未损害事实性记忆能力。
一句话总结
来自 SII、SJTU 和 GAIR 的研究人员推出了 OpenSWE,这是一个透明的框架,包含 45,320 个可执行的 Docker 环境,用于训练软件工程智能体。通过采用多智能体合成流程和质量为中心的过滤机制,该方法在实现显著跨领域推理能力提升的同时,确立了新的最先进水平(SOTA)性能。
主要贡献
- OpenSWE 通过发布涵盖 12.8k 个仓库的 45,320 个可执行 Docker 实例,并附带开源的 Dockerfile、评估脚本和多智能体合成流程,解决了大规模透明训练环境稀缺的问题。
- 该框架引入了以质量为中心的过滤流程,通过表征环境难度来移除不可解或过于简单的实例,最终从 9,000 个高质量环境中筛选出 13,000 条精心策划的轨迹。
- 大量实验表明,在 OpenSWE 上训练的模型在 SWE-bench Verified 上取得了 66.0% 的最先进水平结果,并展现出无饱和现象的对数线性扩展能力,同时提升了跨领域推理能力。
引言
自主软件工程智能体需要像 Docker 这样的可执行环境,通过代码编译和测试生成动态反馈,然而历史上由于高昂的计算成本和缺乏透明度,大规模创建这些环境一直受到阻碍。先前的开源工作往往受限于仓库多样性不足,或存在数据质量问题,例如包含不可解的任务或无法提供有意义学习信号的琐碎问题。为了解决这些差距,作者推出了 OpenSWE,这是一个完全透明的框架,利用多智能体系统合成了超过 45,000 个可执行环境,并实施了感知难度的过滤流程以策划高质量的训练轨迹。该方法不仅发布了完整的基础设施和合成流程,还证明了将大规模数据与战略性的策划相结合,能显著提升智能体在 SWE-Bench Verified 等基准测试上的性能。
数据集
OpenSWE 数据集概览
-
数据集构成与来源 作者通过 REST 和 GraphQL API 从 GitHub 收集数据,构建了 OpenSWE,这是目前最大的用于软件工程智能体训练的完全透明框架。最终数据集包含 45,320 个可执行的 Docker 环境,跨越超过 12,800 个独特的 Python 仓库。该基础设施利用部署在 64 节点分布式集群上的多智能体合成流程构建,实现了仓库探索、Dockerfile 构建和测试生成的自动化。
-
各子集的关键细节
- 原始材料:原始数据包含来自 Python 仓库的约 572,114 个 GitHub 拉取请求(PR)。
- 过滤规则:四阶段流程确保质量,仅保留至少拥有五颗星、以 Python 为主要语言、包含带描述的相关问题链接,且更改未完全局限于测试目录的 PR 的仓库。
- 质量保证:测试分析智能体验证每个环境,确保测试未被硬编码的退出代码绕过,并诊断失败的根本原因,如依赖冲突或不可解的配置。
- 最终规模:经过严格的过滤和策划,该项目产出了约 10,000 个高质量环境和约 13,000 条精心策划的轨迹。
-
模型训练与数据使用
- 轨迹采样:作者使用 GLM-4.7 模型,利用 OpenHands 或 SWE-Agent 脚手架,对 OpenSWE 和过滤后的 SWE-rebench 数据集中的每个实例采样四次智能体轨迹。
- 选择标准:训练数据仅包含在四次尝试中有一到两次成功解决实例的轨迹。
- 数据清洗:包含格式错误或"git pull"命令的步骤被屏蔽或移除,以防止奖励黑客攻击并确保观察质量。
- 训练配置:模型使用修改后的 SLiME 代码库进行训练,上下文窗口为 128k token,训练 5 个 epoch,批量大小为 128,基座模型采用 Qwen2.5-32B 和 Qwen2.5-72B。
-
处理与构建策略
- 分布式合成:为应对执行不稳定和资源争用问题,团队采用了解耦的、容错的并行化框架,使用共享文件系统消息队列和 systemd 服务进行弹性进程管理。
- 自动清理:自动守护进程积极修剪未使用的 Docker 资源,防止僵尸容器导致存储和内存耗尽。
- 元数据与评估:该流程生成具有正确依赖项的可重现 Docker 容器,以及经过验证的评估脚本,通过动态测试执行确认解决方案的正确性。
- 难度策划:作者应用了以质量为中心的过滤过程来表征环境难度,移除了不可解或挑战性不足的实例,以最大化学习效率。
方法
所提出的系统作为一个自动化的环境构建器,旨在为软件工程任务合成可重现的基于 Docker 的评估环境。该架构是分布式的,利用主从范式来管理大规模任务实例的构建和验证。
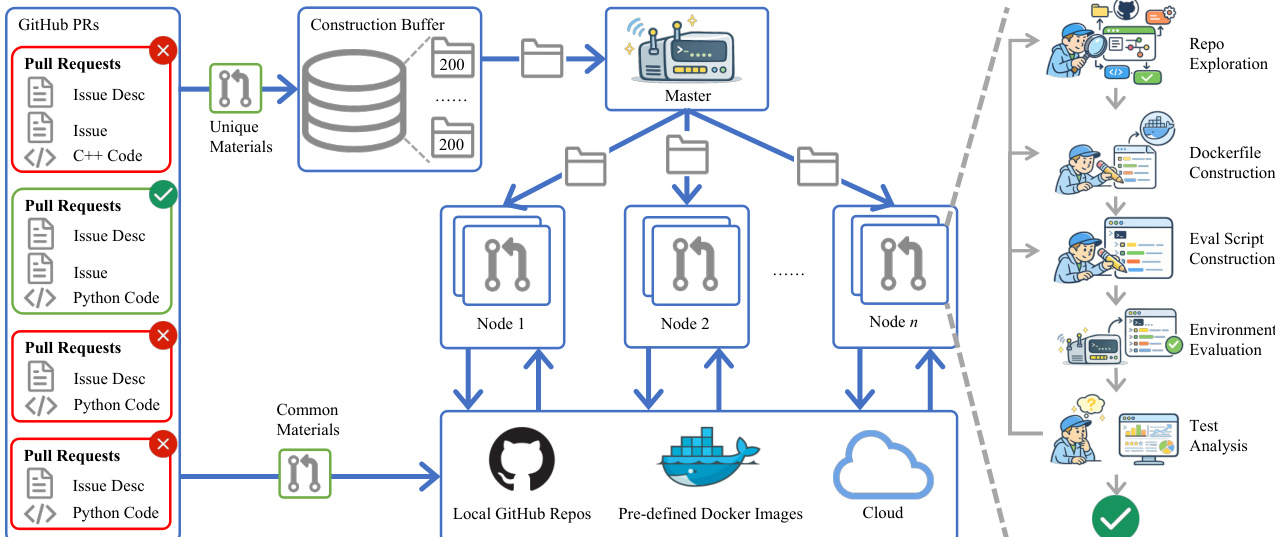
如框架图所示,该流程始于摄入 GitHub 拉取请求,并将其过滤为独特和通用的材料。这些材料存储在构建缓冲区中,并由主节点分发给多个工作节点。每个节点执行一个多阶段智能体循环,包括仓库探索、Dockerfile 构建、评估脚本生成和环境评估。这种分布式设置允许并行处理任务,同时通过本地 GitHub 仓库、预定义的 Docker 镜像和云资源保持隔离。
系统的核心依赖于一系列在迭代反馈循环中运行的专用智能体。该过程始于一个轻量级的仓库探索智能体。该智能体弥合了原始仓库状态与下游环境生成之间的差距。它通过一个受限接口运行,允许进行结构检查、配置文件搜索和设置指令提取。该智能体遵循成本感知的迭代策略,默认执行浅层的、以文档为主的检查,仅当下游智能体请求特定上下文时才深入挖掘。这种设计最大限度地减少了冗余遍历,同时确保识别出依赖清单和 CI 工作流等关键工件。
在获取上下文后,Dockerfile 智能体构建容器化环境。为了解决网络不稳定和冗余重建等常见故障模式,系统采用了一套预构建的基础镜像,涵盖各种 Python 版本。这一策略消除了运行时依赖安装超时的问题。此外,该智能体利用本地裸仓库缓存,通过 COPY 命令注入代码库,而不是在构建时克隆,从而移除了外部网络依赖并提高了可重现性。该智能体还受到感知层提示的引导,将稳定的基础层放置在 Dockerfile 的早期,以便在后续迭代中修改依赖规范时实现高效的缓存。
同时,评估脚本智能体生成 Bash 脚本来验证修复的正确性。这里的核心挑战是精确的测试目标定位,确保仅执行相关的测试用例。该智能体从头开始合成结构化的 Bash 脚本,整合特定的测试文件,并嵌入专用的退出代码标记以信号化修复的成功或失败。该脚本基于模板设计以支持稳定的迭代,将补丁注入与测试命令逻辑分离。
最后,环境评估模块执行基于规则的验证。对于每次迭代,Docker 镜像被构建,并在两种条件下执行评估脚本:首先仅应用测试补丁以验证未修补代码库上的失败,然后应用完整的修复补丁以验证问题的解决。为了支持大规模操作,容器被绑定到专用的 CPU 核心和内存限制,以防止资源争用。镜像会保留直到 Dockerfile 发生变化,这显著加速了仅修改评估脚本的常见情况。如果验证失败,测试分析智能体将检查日志,并向 Dockerfile 或评估脚本智能体提供有针对性的反馈,以便在下一轮迭代中优化其输出。
实验
- 在 SWE-Bench Verified 上的主要性能评估证实,OpenSWE 在 32B 和 72B 规模下均取得了最先进水平结果,证明了高质量的环境数据可以弥补领域特定预训练的不足。
- 扩展性分析确认了稳健的对数线性改进趋势,即更大的模型从增加的训练数据中获益更多,且在当前预算范围内未观察到性能饱和。
- 环境来源比较显示,OpenSWE 合成的环境提供了比现有基准测试强得多的训练信号,而混合数据源为更大的模型提供了互补的益处。
- 通用能力评估表明,专注于软件工程(SWE)的训练通过改进多步规划显著增强了代码生成和数学推理能力,而对事实回忆的影响微乎其微。