Command Palette
Search for a command to run...
Spatial-TTT:基于流式视觉的测试时训练空间智能
Spatial-TTT:基于流式视觉的测试时训练空间智能
Fangfu Liu Diankun Wu Jiawei Chi Yimo Cai Yi-Hsin Hung Xumin Yu Hao Li Han Hu Yongming Rao Yueqi Duan
摘要
人类通过连续的视觉观测来感知和理解现实世界空间。因此,具备从可能无限长的视频流中持续维护与更新空间证据的能力,对于实现空间智能至关重要。核心挑战并非单纯扩大上下文窗口,而在于如何随时间对空间信息进行选择、组织与保留。本文提出 Spatial-TTT,一种面向基于视频流的空间智能的测试时训练(Test-Time Training, TTT)方法。该方法通过自适应调整部分参数(即“快速权重”),以在长时序场景视频中有效捕捉并组织空间证据。具体而言,我们设计了混合架构,采用大片段更新机制,并结合滑动窗口注意力机制,以实现高效的视频空间处理。为进一步增强空间感知能力,我们在 TTT 层中引入了一种空间预测机制,并辅以三维时空卷积,促使模型在帧间捕捉几何对应关系与时间连续性。除架构设计外,我们构建了一个包含密集三维空间描述的数据集,引导模型通过更新快速权重,以结构化方式记忆并组织全局三维空间信号。大量实验表明,Spatial-TTT 显著提升了长时序空间理解能力,并在多个视频空间基准测试中取得了最先进(state-of-the-art)的性能。项目主页:https://liuff19.github.io/Spatial-TTT。
一句话总结
清华大学、腾讯混元与南洋理工大学的 researchers 提出了 Spatial-TTT,这是一种测试时训练(Test-Time Training)模型,利用快速权重和 3D 时空卷积高效组织流式视觉证据,在视频基准测试中实现了最先进的长程空间理解能力。
主要贡献
- Spatial-TTT 通过采用测试时训练来调整快速权重,将其作为紧凑的非线性记忆以累积 3D 场景信息,从而解决了在无限视频流中维持空间证据的挑战。
- 该框架引入了一种混合架构,包含大块更新和并行滑动窗口注意力机制,并辅以利用 3D 卷积的空间预测机制,以捕捉几何对应关系和时间连续性。
- 为了为学习有效的权重更新动态提供丰富的监督信号,作者构建了一个包含密集 3D 空间描述的新数据集,使模型在视频空间基准测试中取得了最先进的性能。
引言
现实世界的空间智能要求系统能够持续处理无限视频流,以维持对动态环境的准确 3D 理解,这一能力对于机器人、自动驾驶和增强现实至关重要。当前的多模态大语言模型难以应对这一任务,因为它们缺乏固有的 3D 几何先验,且无法在不过度增加计算成本或避免因激进下采样而丢失关键空间细节的情况下扩展到长程视频。为了解决这些局限性,作者提出了 Spatial-TTT,这是一个利用测试时训练在线更新自适应快速权重的框架,有效地创建了一个用于累积空间证据的紧凑非线性记忆。他们通过一种混合架构增强了该方法,该架构在高效长上下文压缩与推理之间取得平衡,利用 3D 卷积的空间预测机制捕捉几何连续性,并引入一个新的密集场景描述数据集来指导有效权重更新动态的学习。
数据集
-
数据集构成与来源 作者构建了一个两阶段训练流程,使用密集场景描述数据集和大规模空间问答(QA)数据集。第一阶段依赖于来自 SceneVerse 的以物体为中心的 3D 场景图,而第二阶段则结合了开源基准测试与源自 ScanNet 重建的自采数据。
-
各子集的关键细节
- 密集场景描述子集:该集合包含约 16,000 个样本,其中 3,600 个来自 ScanNet,12,500 个来自 ARKitScenes。每个样本将空间视频流与格式化为连贯场景导览的目标描述配对。
- 空间问答子集:该集合包含约 300 万个样本,包括 250 万个开源条目和 50 万个自采条目。开源部分聚合了来自 VSI-590K、VLM-3R、InternSpatial 和 ViCA 的数据。自采部分由从原始 ScanNet 重建中以 24 fps 采样、分辨率为 640x480 的室内场景视频序列组成。
-
模型使用与训练策略 作者在第一阶段使用密集场景描述数据训练混合 TTT 架构,使快速权重能够学习逐块更新,从而保留全面的场景级信息。在第二阶段,模型在大规模空间 QA 数据集上进行训练,以优化空间推理能力。这种方法用密集描述提供的丰富、高覆盖信号,补充了标准 QA 任务中稀疏的局部监督。
-
处理与元数据构建 对于自采的 QA 数据,作者将原始网格与轴对齐矩阵对齐并转换为点云。他们使用 alpha-shape 算法估算房间范围和质心,并为有效物体实例拟合定向边界框(OBB),同时丢弃墙壁和地板等结构元素。语义标签被重新映射为统一的 40 类室内集合,并计算 2D 投影语义标注以支持外观顺序推理。每个样本的最终元数据包括房间尺寸和坐标、2D 语义投影、物体的 OBB 参数及其对应的语义标签。
方法
作者提出了 Spatial-TTT,这是一个旨在通过将测试时训练(TTT)集成到多模态 Transformer 中,以增强长程视频理解中基于视觉的空间推理的框架。核心方法依赖于一种混合架构,该架构将 TTT 层与标准自注意力层交错排列,以在内存效率与保留预训练视觉语义知识之间取得平衡。
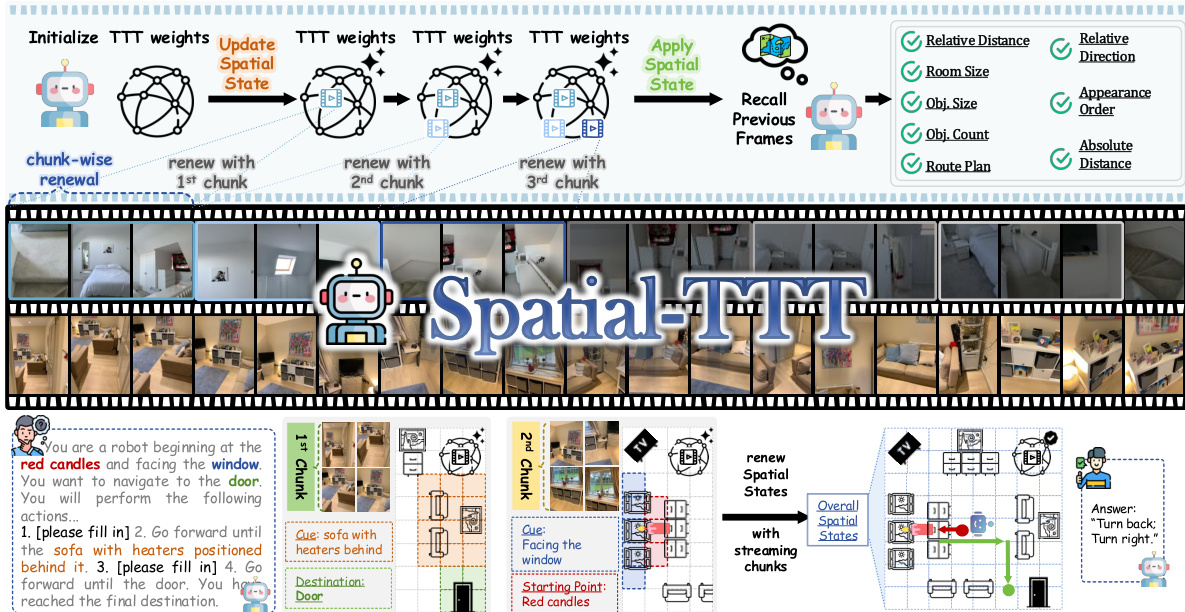
整体框架通过分块处理视频流来更新和应用空间状态。如框架图所示,模型初始化 TTT 权重并执行分块更新以刷新空间状态。这一过程使系统能够回忆之前的帧,并对相对距离、房间大小和路线规划等空间属性进行推理。该工作流程展示了模型如何从原始视频输入过渡到支持复杂导航和推理任务的结构化空间表示。
为实现这一点,作者设计了一种混合 TTT 架构,其中 75% 的解码器层使用 TTT,而剩余的 25% 保留标准自注意力作为锚点层。这些锚点层保持对整个上下文的完整注意力访问,以保留预训练模型的语义推理能力。同时,TTT 层将长程时间依赖压缩为自适应快速权重 Wt,实现了次线性内存增长。在每个 TTT 层内,作者采用较大的块大小来处理视觉令牌,从而显著提高并行性和硬件效率。为了解决阻止块内令牌交互的因果约束,他们在每个 TTT 层中引入了滑动窗口注意力(SWA),并与 TTT 并行运行。层输出结合了两个分支,如下所示:
ot=WindowAttn(qt,K∣t−w:t∣,V∣t−w:t∣)+fWt(qt)其中 K[t−w:t] 和 V[t−w:t] 表示滑动窗口内的键和值。对于快速权重网络 fW,使用了无偏置的 SwiGLU-MLP 以增加记忆的非线性和表达能力。
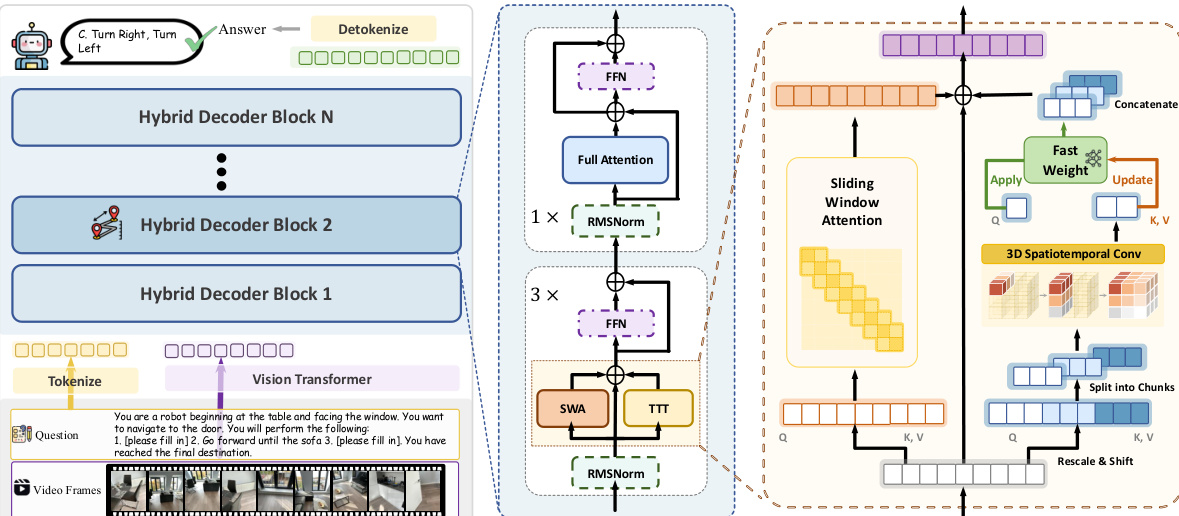
混合解码器块的详细架构如下图所示,突出了 TTT 分支与滑动窗口注意力及标准前馈网络的集成。该设计的一个关键组件是空间预测机制。流式空间理解面临着独特的挑战,因为空间信息源于具有强几何和时间连续性的连续视觉观测。为了解决这一问题,作者在 TTT 分支的 Q、K、V 上引入了带有轻量级深度时空卷积的空间预测机制。对于来自视频的视觉令牌,它们被重塑为时空网格,以通过局部聚合来聚合邻域信息。这确保了快速权重学习的是时空上下文之间的预测映射,而不是孤立的令牌。
为了进一步提高 TTT 更新的稳定性和有效性,作者采用了 Muon 更新规则,而非原始实现。这涉及对带有动量的梯度进行正交化,并在保持原始幅度的同时对权重进行归一化。模型采用空间感知的渐进式训练策略进行训练。首先使用密集场景描述数据初始化,教导快速权重保留全面的场景级信息,随后在大规模空间 VQA 数据上进行微调以增强流式推理能力。在推理时,采用双 KV 缓存机制以实现恒定内存流式处理,利用滑动窗口缓存处理局部上下文,并利用待处理缓存进行快速权重更新。
实验
- VSI-Bench 评估表明,该模型实现了卓越的通用空间理解能力,在导航和方向的几何推理方面表现优异,同时为距离和场景尺度估计提供了准确的度量基础。
- MindCube 测试证实了其增强的细粒度空间能力,特别是在跨视图保持物体一致性以及在相机视角变化下推理被遮挡元素方面。
- 长程视频流式基准测试显示,该模型能够有效地随时间累积时空证据,在物体计数和时间回忆方面显著优于基线模型,而其他模型则因内存限制而失败。
- 消融研究验证了空间预测机制、密集场景描述监督和混合架构对于稳定更新、保留全局 3D 证据以及实现跨模态对齐都至关重要。
- 效率分析表明,该模型保持了与输入长度成线性关系的计算扩展性,避免了在扩展视频处理过程中竞争对手的通用模型和几何增强模型所观察到的内存溢出和超线性成本增长。