Command Palette
Search for a command to run...
MM-CondChain:面向视觉 grounded 深度组合推理的程序化验证基准
MM-CondChain:面向视觉 grounded 深度组合推理的程序化验证基准
Haozhan Shen Shilin Yan Hongwei Xue Shuaiqi Lu Xiaojun Tang Guannan Zhang Tiancheng Zhao Jianwei Yin
摘要
多模态大语言模型(MLLMs)正日益被用于执行视觉工作流任务,例如在图形用户界面(GUI)中进行导航。此类任务中,下一步操作往往依赖于经过验证的视觉组合条件(例如,“若出现权限对话框且界面颜色为绿色,则点击‘允许’"),且执行过程可能分支或提前终止。然而,该能力尚未得到充分评估:现有基准测试多聚焦于浅层组合或独立约束,而非深层链式组合条件。本文提出 MM-CondChain,一个面向视觉 grounded 深度组合推理的基准测试。每个基准实例被组织为多层推理链,其中每一层均包含一个基于视觉证据的非平凡组合条件,该条件由多个对象、属性或关系构建而成。为正确作答,MLLM 必须细致感知图像内容,在每一步对多个视觉元素进行推理,并依据推导出的执行路径直至最终结果。为可扩展地构建此类工作流风格数据,我们提出了一种代理式合成流程:由“规划器”(Planner)逐层编排组合条件的生成,同时引入“可验证的程序化中间表示”(Verifiable Programmatic Intermediate Representation, VPIR),确保每一层的条件均可通过机械方式验证;随后,“组合器”(Composer)将这些已验证的层组装为完整指令。利用该流程,我们在三个视觉领域构建了基准数据集:自然图像、数据图表以及 GUI 操作轨迹。在多种 MLLM 上的实验表明,即使是最先进的模型,其路径 F1 分数也仅为 53.33;在面对高难度负样本时性能急剧下降,且随着推理深度或谓词复杂度的增加,表现进一步恶化。这证实了深度组合推理仍是当前面临的一项根本性挑战。
一句话总结
阿里巴巴集团与浙江大学的研究人员推出了 MM-CondChain,这是一个用于视觉 grounded 深度组合推理的基准测试。该基准采用基于 VPIR 的智能体流水线,生成可机械验证的多层条件链,揭示了即使是当前最先进的多模态模型,在面对需要精确逐步验证的复杂视觉工作流时仍显得力不从心。
主要贡献
- 现有基准测试无法评估深度组合推理能力,因为它们侧重于浅层的单层组合或独立约束,而非多层视觉工作流(其中每一步都决定执行路径)。
- 作者提出了 MM-CondChain,这是一个以视觉证据为根基的嵌套条件链基准,通过智能体合成流水线构建,该流水线利用可验证的程序化中间表示(VPIR)以确保机械可验证性。
- 在自然图像、数据图表和 GUI 轨迹上的实验表明,即使是最强的多模态模型,其路径 F1 分数也仅为 53.33,且随着推理深度和谓词复杂度的增加,性能显著下降。
引言
多模态大语言模型正越来越多地部署于复杂的视觉工作流中(如 GUI 导航),其中后续动作依赖于对链式视觉条件的验证。然而,现有基准测试无法评估这一能力,因为它们侧重于浅层的单层组合或独立约束,而非基于视觉证据进行分支或终止的深度多步推理路径。为填补这一空白,作者推出了 MM-CondChain,这是一个具有多层控制流且包含经机械验证的硬负样本的基准。他们通过一种智能体合成流水线实现了可扩展且可靠的数据构建,该流水线利用可验证的程序化中间表示(VPIR),将逻辑条件生成与自然语言渲染解耦。
数据集
-
数据集构成与来源:作者利用公开数据集,从三个不同的视觉领域构建了 MM-CondChain。自然领域(Natural)包含来自 SAM 和 GQA 的 398 张图像;图表领域(Chart)包含来自 ChartQA 的 200 张图表图像;GUI 领域包含来自 AITZ 的 377 条交互轨迹(共计 3,421 张截图)。
-
各子集的关键细节:
- 自然领域:侧重于物体属性和空间关系。
- 图表领域:专注于柱状图、折线图和饼图中的数值与结构统计。
- GUI 领域:强调动作、状态和轨迹级元数据,并包含细粒度的推理标注。
- 总体规模:该基准包含 975 个评估样本,每个样本由一对“真路径”(True-path)和“假路径”(False-path)实例组成。
-
数据使用与处理:
- 合成流水线:作者采用 Gemini-3-Pro 实例化合成流水线中的所有智能体,包括规划器(Planner)、验证器(Verifier)、事实提取器(Fact Extractor)和翻译器(Translator)。
- 主体去泄露:基于 MLLM 的重写器修改主体描述,以移除揭示条件的属性,同时确保主体仍能唯一指代目标物体。
- 成对路径实例化:每个控制流骨架生成两个近乎同构的实例。真路径遵循所有条件直至终止层,而假路径则在随机采样的分歧层交换单个条件以触发提前终止。
- 指令编译:系统将主体和条件合并为流畅的自然语言 if 子句,以创建作为硬负样本的嵌套指令。
-
评估策略:
- 指标:性能使用真路径准确率、假路径准确率和路径 F1(两者的调和平均数)进行衡量,总体得分为各域路径 F1 的平均值。
- 设置:模型在零样本设置下使用默认 API 参数进行评估,答案根据特定格式规则从多项选择输出中提取。
方法
作者提出了一种基于 VPIR 的智能体基准构建流水线,将逻辑构建与语言渲染解耦,以解决多层组合推理中的逻辑不一致问题。该核心框架接受多模态输入,包括自然图像、带元数据的图表图像以及带标注的 GUI 轨迹。整体架构请参阅框架图。
该流水线通过由规划器协调的迭代式多层推理链运行。在每一层 t,规划器选择一个关系策略 rt 来决定推理链的演变方式,在 EXTEND(扩展)、FINISH(结束)或 ROLLBACK(回滚)等动作中进行选择。这种控制机制确保链深度保持在目标区间内,同时保持连贯性。
一旦某层启动,系统即执行四阶段合成工作流。首先,事实提取器通过选择主体 St 并生成作为类型化键值映射的结构化事实 Ft,将生成过程锚定在视觉证据上。这种结构化表示防止了幻觉并定义了程序化命名空间。其次,VPIR 生成器合成可验证的程序化中间表示,包含一个真逻辑谓词 pt 和一个反事实假逻辑 p~t。这些谓词是可执行的类 Python 代码,在沙盒环境中进行评估以确保机械可验证性。
如下图所示:
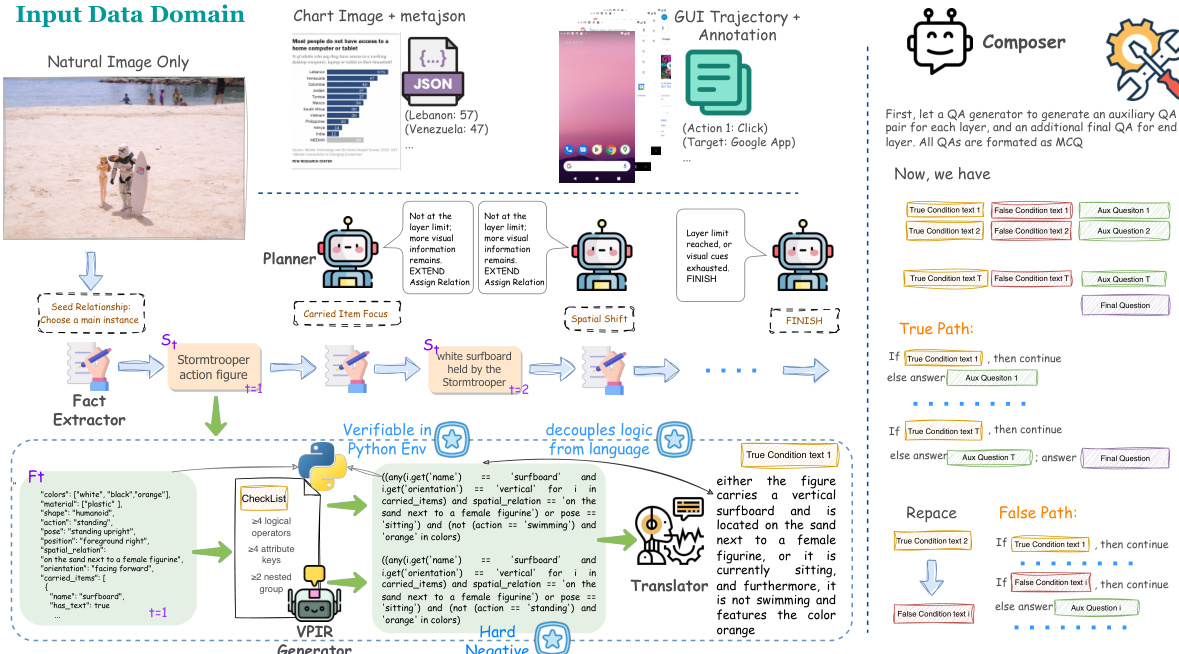
第三,翻译器将已验证的可执行逻辑渲染为自然语言条件文本 ct 和 c~t。这一步确保真值锚定于代码执行而非语言生成。最后,合成器将已验证的链编译为成对的基准实例。它构建一个所有条件均成立的真路径,以及一个用最小扰动反事实替换单个条件的假路径,从而创建需要精确视觉锚定和深度组合推理的硬负样本。
实验
- 在 MM-CondChain 上的主要评估显示,当前的多模态大语言模型难以处理视觉 grounded 的深度组合推理,即使是表现最好的模型,其平均路径 F1 也仅略高于 50%。
- 真路径与假路径的对比实验显示出显著的偏差:模型倾向于过度假设条件成立,导致在有效路径上准确率较高,但在无效路径上表现不佳,这在实际工作流中构成了风险。
- 领域分析表明,GUI 任务最具挑战性,因为需要多帧轨迹和状态转换推理;而图表任务相对容易,因为它们通常简化为确定性的数值比较。
- 关于链深度的消融研究表明,随着顺序验证层数的增加,性能持续下降,证实了错误会在各层间累积而非孤立存在。
- 关于谓词复杂度的测试显示,增加单个条件内的逻辑运算符和嵌套会导致性能大幅下降,突显了模型在顺序推理和层内组合推理方面均存在困难。
- 总体而言,研究结果表明,链深度和谓词复杂度是两个正交的困难维度,共同定义了当前模型的极限,使得该基准成为识别特定推理失败的重要诊断工具。