Command Palette
Search for a command to run...
IndexCache:通过跨层索引复用加速稀疏注意力机制
IndexCache:通过跨层索引复用加速稀疏注意力机制
Yushi Bai Qian Dong Ting Jiang Xin Lv Zhengxiao Du Aohan Zeng Jie Tang Juanzi Li
摘要
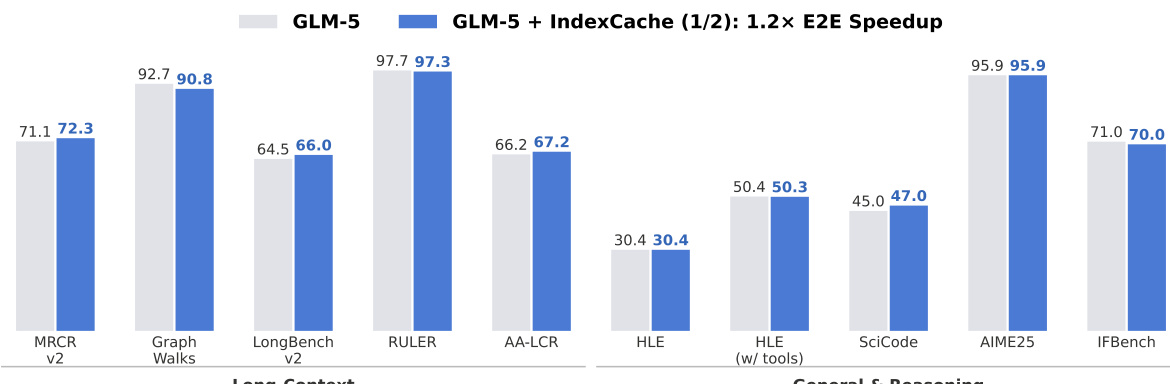
长上下文代理工作流已成为大语言模型(LLM)的标志性应用场景,这使得注意力机制的效率对推理速度与部署成本至关重要。稀疏注意力机制有效应对了这一挑战;其中,DeepSeek 稀疏注意力(DeepSeek Sparse Attention, DSA)是一种具有代表性的生产级解决方案:它采用轻量级闪电索引器(lightning indexer),为每个查询筛选出前 k 个最相关令牌,从而将核心注意力计算复杂度从 O(L2) 降低至 O(Lk)。然而,该索引器自身仍保持 O(L2) 的复杂度,且需在每一层独立运行,尽管相邻层所生成的 top-k 选择结果高度相似。为此,我们提出 IndexCache,通过利用跨层冗余来优化这一过程:将网络层划分为少量“全索引层”(Full layers),这些层运行独立的索引器;其余大部分为“共享层”(Shared layers),直接复用最近的全索引层所生成的 top-k 索引。我们提出了两种互补策略以确定并优化该配置方案。其一是“免训练 IndexCache"(Training-free IndexCache):该方法采用贪婪搜索算法,通过在校准集上直接最小化语言建模损失,自动选择保留哪些层的索引器,无需更新模型权重。其二是“训练感知 IndexCache"(Training-aware IndexCache):该方法引入多层蒸馏损失函数,使每个保留的索引器针对其服务的所有层的平均注意力分布进行训练,从而即使采用简单的交错模式,也能达到与全索引器相当的精度。在 300 亿参数 DSA 模型上的实验结果表明,IndexCache 可消除 75% 的索引器计算开销,且几乎不牺牲模型质量;相较于标准 DSA 方案,其预填充(prefill)阶段速度提升最高达 1.82 倍,解码(decode)阶段速度提升最高达 1.48 倍。此外,我们在生产规模 GLM-5 模型上的初步实验(见图 1)进一步验证了上述积极成果。
一句话总结
清华大学与 Z.ai 的研究人员推出了 IndexCache,这是一种通过利用跨层冗余来共享 token 索引的技术,旨在优化 DeepSeek 稀疏注意力机制。该方法在长上下文工作流中消除了高达 75% 的索引器计算量,在无需重新训练模型且不降低输出质量的前提下,显著提升了推理速度。
主要贡献
- 长上下文代理工作流依赖 DeepSeek 稀疏注意力(DSA)来降低核心注意力复杂度,但其所需的轻量级索引器(lightning indexer)在每一层仍会产生 O(L2) 的二次方成本,成为推理速度和服务成本的重大瓶颈。
- IndexCache 通过将层划分为“全量层”(Full layers,负责计算索引)和“共享层”(Shared layers,复用最近的全量层的 top-k 选择)来解决这一冗余问题,并利用免训练的贪婪搜索或感知训练的多层蒸馏损失来优化配置。
- 在 30B DSA 模型上的实验表明,IndexCache 在几乎不降低质量的情况下消除了 75% 的索引器计算量,实现了高达 1.82 倍的预取(prefetch)加速和 1.48 倍的解码(decode)加速,同时在九项长上下文和推理基准测试中保持了性能。
引言
大型语言模型在长上下文推理中面临关键瓶颈,这源于自注意力机制的二次方复杂度。DeepSeek 稀疏注意力(DSA)等稀疏机制通过仅选择最相关的 token 来解决这一问题。尽管 DSA 降低了核心注意力成本,但其在每一层依赖轻量级索引器仍会产生二次方开销,主导了预填充(prefill)阶段的延迟。作者利用“跨连续层的 token 选择模式保持高度稳定”这一观察,提出了 IndexCache。该方法通过复用少量保留层的索引,消除了高达 75% 的索引器计算量。作者提出了一种基于贪婪层选择的免训练方法,以及一种结合多层蒸馏的感知训练策略,旨在在实现长上下文场景显著加速的同时保持模型质量。
方法
作者利用稀疏注意力索引器在连续层之间存在显著冗余这一观察,以降低计算开销。在标准的 DeepSeek 稀疏注意力中,轻量级闪电索引器在每一层对所有前置 token 进行评分以选择 top-k 位置。虽然这将核心注意力复杂度从 O(L2) 降低到了 O(Lk),但索引器本身仍保留 O(L2) 的复杂度。IndexCache 通过将 N 个 Transformer 层划分为两类来解决这一问题:全量层(Full layers)和共享层(Shared layers)。全量层保留其索引器以计算新的 top-k 集合,而共享层则跳过索引器的前向传播,直接复用最近的前置全量层的索引集合。这种设计使得系统能够在最小化架构变更的情况下,消除大部分总索引器成本。
为了在不重新训练的情况下确定全量层和共享层的最优配置,作者提出了一种免训练的贪婪搜索算法。该过程始于将所有层标记为全量层。算法迭代地评估校准集上每个候选层转换的语言模型损失。在每一步中,选择转换为共享状态后导致损失增加最小的层。这种数据驱动的方法能够根据索引器对模型性能的内在重要性来识别哪些索引器是可以省略的,而不是依赖均匀的交错模式。
对于从头训练或通过持续预训练得到的模型,一种感知训练的方法可以进一步优化索引器参数以实现跨层共享。标准训练是将索引器蒸馏为其自身层的注意力分布。IndexCache 通过引入多层蒸馏损失对此进行了泛化。该目标鼓励保留的索引器预测一个对其自身以及其服务的所有后续共享层都有用的 top-k 集合。损失函数定义如下:
LmultiI=j=0∑mm+11t∑DKL(pt(ℓ+j)qt(ℓ)),其中 pt(ℓ+j) 表示层 ℓ+j 处的聚合注意力分布,qt(ℓ) 是索引器的输出分布。理论分析表明,这种多层损失产生的梯度等同于针对所有服务层的平均注意力分布进行蒸馏。这确保了索引器学习到一个共识性的 top-k 选择,能够覆盖整个层组中的重要 token。
在 300 亿参数模型上的实验评估证明了移除索引器计算所带来的效率提升。该方法成功消除了高达 75% 的索引器成本,同时保持了可比的质量。关于预填充时间和解码吞吐量的性能指标总结如下。
结果证实,IndexCache 在预填充和解码阶段均提供了显著的加速,且未降低模型能力。
实验
- 端到端推理实验表明,IndexCache 显著加速了长上下文场景下的预填充延迟和解码吞吐量,且随着上下文长度的增加,加速效果更为明显,同时在通用推理任务上保持了可比的性能。
- 免训练的 IndexCache 评估显示,贪婪搜索得到的共享模式对于在激进的保留比率下保持长上下文准确性至关重要,而均匀交错会导致显著的性能下降;然而,通用推理能力在大多数配置下依然稳健。
- 感知训练的 IndexCache 结果表明,通过重新训练模型以适应索引共享,可以消除对特定模式的敏感性,使得简单的均匀交错也能达到全索引器的性能,从而证实了跨层蒸馏的有效性。
- 在 7440 亿参数模型上的扩展实验验证了在小模型中观察到的趋势同样适用,搜索得到的模式即使在高度稀疏的情况下也能提供稳定的质量恢复。
- 对跨层索引重叠的分析证实了相邻层之间存在高度冗余,但也揭示了局部相似性指标无法识别最优共享模式,因此需要基于端到端损失的搜索来防止深度网络中的级联错误。