Command Palette
Search for a command to run...
Kinema4D:面向时空具身模拟的运动学四维世界建模
Kinema4D:面向时空具身模拟的运动学四维世界建模
Mutian Xu Tianbao Zhang Tianqi Liu Zhaoxi Chen Xiaoguang Han Ziwei Liu
摘要
模拟机器人与世界的交互是具身智能(Embodied AI)的基石。近期,一些研究在利用视频生成技术突破传统模拟器在视觉与物理层面的刚性约束方面展现出潜力。然而,这些方法主要局限于二维空间,或仅依赖静态环境线索,忽视了机器人与世界交互本质上属于需要精确交互建模的4D时空事件这一根本事实。为了在恢复这一4D本质的同时确保机器人控制的精确性,我们提出了 Kinema4D——一种新型的动作条件化4D生成式机器人模拟器。该模拟器将机器人与世界的交互解耦为两个核心部分:i) 机器人控制的精确4D表征:我们基于运动学驱动一个URDF格式的3D机器人模型,生成精确的4D机器人控制轨迹;ii) 环境反应的生成式4D建模:我们将4D机器人轨迹投影为点图(pointmap),作为一种时空视觉信号,以此引导生成模型合成复杂环境中的动态响应,并输出同步的RGB图像序列与点图序列。为便于模型训练,我们构建了一个名为 Robo4D-200k 的大规模数据集,包含201,426个机器人交互片段,并配有高质量的4D标注。大量实验表明,我们的方法能够有效模拟物理合理、几何一致且与具体具身形态无关的交互行为,真实复现多样化的现实世界动态。更重要的是,该方法首次展现出潜在的零样本(zero-shot)迁移能力,为下一代具身模拟的发展提供了高保真的基础。
一句话总结
南洋理工大学与香港中文大学(深圳)的研究人员提出了 Kinema4D,这是一种动作条件化的 4D 生成模拟器,它独特地将运动学机器人控制与基于扩散的环境合成相结合,克服了以往 2D 或文本引导模型在用于高保真具身智能训练时的精度限制。
主要贡献
- 本文介绍了 Kinema4D,这是一种动作条件化的 4D 生成模拟器,它通过显式运动学驱动基于 URDF 的机器人以生成精确的控制轨迹,同时利用点图(pointmap)投影引导生成模型合成同步的 RGB 和点图序列,以模拟环境反应。
- 构建了一个名为 Robo4D-200k 的大规模数据集以支持训练,该数据集包含 201,426 个机器人交互片段,其高质量 4D 标注源自真实世界和合成演示。
- 大量实验表明,该方法能有效模拟物理合理且几何一致的交互,实现了能够反映多样化真实世界动态的零样本迁移能力。
引言
具身智能依赖于模拟机器人与世界的交互以扩展训练和策略评估,然而传统的物理引擎缺乏视觉真实感,而最近的基于视频的方法又未能捕捉这些事件固有的 4D 时空特性。以往的方法受限于其在 2D 像素空间的操作,或依赖于高层语言指令和潜在嵌入,这些方法缺乏建模复杂物理动态(如材料变形或被遮挡物体的运动)所需的精确运动学引导。为了解决这些差距,作者提出了 Kinema4D,这是一种动作条件化的 4D 生成模拟器,将过程解耦为精确的运动学机器人控制和生成式环境反应建模。通过驱动基于 URDF 的机器人创建确定性的 4D 轨迹,并将其投影为点图信号以引导生成模型,该框架实现了物理合理且几何一致的模拟。作者还贡献了 Robo4D-200k,这是一个包含超过 200,000 个标注机器人交互片段的大规模数据集,支持高保真具身模拟,并具备潜在的零样本迁移能力。
数据集
Robo4D-200k 数据集概览
-
数据集构成与来源 作者将 201,426 个高保真片段聚合到 Robo4D-200k 数据集中,结合了来自 DROID、Bridge 和 RT-1 的真实世界机器人演示,以及通过 LIBERO 平台生成的合成数据。这种混合确保了多样化的交互场景,从关节物体操作到抓取放置任务。
-
各子集的关键细节
- 真实世界数据: 源自 DROID、Bridge 和 RT-1,这些视频使用 ST-V2 重建框架进行处理,生成稳健且时间一致的 4D 点图序列,适用于快速机器人运动。
- 合成数据: 基于 LIBERO 内的 MuJoCo 引擎构建,该子集利用原生无噪深度参数以实现绝对的真值精度。它包括程序化随机化的背景,以及通过向 6-DoF 位姿维度注入高斯噪声(同时保持夹持器状态不受干扰)而系统合成的失败案例。
-
数据使用与训练策略 该数据集作为训练 Kinema4D 模型的基础,每个片段被切片为统一的 49 帧序列以保持一致的运动频率。作者利用一个统一的验证集,该验证集包含从所有源域按比例采样的 3,200 个片段(2,000 个来自 DROID,1,000 个来自 Bridge,100 个来自 RT-1,100 个来自 LIBERO),以确保公平评估且无数据泄露。
-
处理与标注细节
- 4D 重建: 该流程优先考虑可扩展性,对真实世界数据使用 ST-V2 以捕捉相对空间几何,而合成数据则使用直接深度渲染以实现像素对齐的轨迹。
- 机器人分割: 为了将机器人隔离为控制信号,作者应用带有语义提示的 SAM2 从 RGB 帧中分割机器人区域,并掩蔽相应的点图。
- 语言生成: 由于原始文本标签往往不完整,团队使用 Qwen3-VL-plus 为每个片段生成两种类型的描述:涵盖整个视频动态的完整文本,以及专注于初始静态场景的环境中心描述。
- 整理: 人工验证修剪了低质量捕获和重建伪影,而统一的时间下采样将长演示标准化为 49 帧格式。
方法
提出的框架 Kinema4D 通过一个两阶段流程运行,旨在将确定性的机器人运动与随机性的环境反应解耦。请参阅框架图以获取系统的高级概述,该系统接收规范化的初始世界图像和机器人动作序列,以生成 4D 空间中的未来机器人与世界交互。

该架构由两个主要组件组成:运动学控制与 4D 生成建模。如详细架构图所示,运动学控制模块将抽象的机器人动作转换为精确的 4D 表示。此过程始于 3D 机器人资产获取,其中使用工厂提供的 CAD 网格或涉及轨道视频捕获和网格恢复的重建流程来建立几何实体。机器人 URDF 模型中的关节锚点被映射到重建的网格上以实现关节运动。给定输入动作序列,系统采用逆运动学(IK)进行末端执行器控制,或直接映射进行关节空间控制,以解析关节配置 qt。随后,正运动学(FK)计算重建空间内所有连杆的 6-DoF 位姿。最后,空间 - 视觉投影利用相机内参和外参将关节机器人轨迹映射到图像平面,生成 4D 机器人点图 M1:T。对于连杆 k 表面上的任意点 x,其投影像素坐标 (u,v) 和深度 z 由下式确定: u⋅zv⋅zz=K⋅Treconcam⋅Tk,trecon⋅x, 其中 K 是相机内参矩阵。该点图作为与 RGB 网格像素对齐的时空视觉信号。
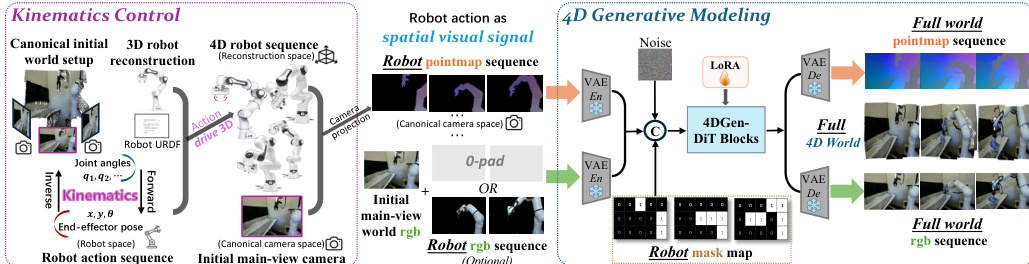
第二阶段,4D 生成建模,利用扩散模型合成环境的反应动态。初始主视图世界图像与机器人点图序列在时间上对齐并拼接。该统一信号由共享的 VAE 编码器处理以获得输入潜在变量。为了实施像素级控制,引入了引导掩码,指示机器人的空间占用区域与待生成区域。核心骨干是一个扩散 Transformer(DiT),用于预测同步的 RGB 和点图序列。为了保持像素级对齐,模型在两种模态中采用共享的旋转位置编码(RoPE),而可学习的域嵌入则用于区分它们。扩散过程通过优化条件去噪目标来学习生成该潜在序列: Lvid=Ez0,ϵ,τ,c[∥ϵ−ϵθ(zτ,τ,c)∥2], 其中 zτ 是扩散步骤 τ 处的噪声潜在变量。去噪过程以机器人点图作为几何锚点进行引导。最后,去噪后的潜在变量由共享的 VAE 解码器重建,以生成全场景点图和 RGB 序列,从而产生一个 4D 世界,其中每个像素的深度和运动都扎根于 3D 空间。
实验
- 主要生成实验验证,与最先进的 2D 和 4D 基线相比,所提出的框架在 4D 几何保真度和时间一致性方面表现更优,特别是在准确模拟复杂物理交互(如 2D 方法失效的近距离失败案例)方面。
- 策略评估实验证明了该框架作为高保真模拟器的实用性,成功预测了无噪模拟和严格的零样本真实世界场景中的机器人任务结果,且无需微调。
- 消融研究证实,使用机器人点图作为主要控制信号对于精确的空间推理至关重要,同时该模型对输入噪声具有鲁棒性,并受益于跨多样化数据集的与具身无关的训练。
- 对比分析显示,仅依赖文本指令或深度图会导致性能显著下降,而所提出的 4D 感知方法确保了物理合理的过渡和强大的跨域泛化能力,尽管计算成本较高。