Command Palette
Search for a command to run...
深度混合注意力
深度混合注意力
摘要
扩展深度是大型语言模型(LLM)发展的关键驱动力。然而,随着 LLM 层数的增加,模型往往面临信号退化问题:浅层形成的信息特征在反复的残差更新过程中逐渐被稀释,导致其在深层中难以恢复。为此,我们提出了深度混合注意力机制(Mixture-of-Depths Attention, MoDA)。该机制允许每个注意力头同时关注当前层的序列键值(KV)对,以及来自前序各层的深度 KV 对。此外,我们设计了一种高效的硬件算法以解决 MoDA 中的非连续内存访问模式问题,在序列长度为 64K 时,其效率可达 FlashAttention-2 的 97.3%。在 15 亿参数模型上的实验表明,MoDA 始终优于多个强基线方法。具体而言,在 10 个验证基准上,MoDA 将平均困惑度降低了 0.2;在 10 项下游任务中,平均性能提升了 2.11%,而计算开销(FLOPs)仅增加 3.7%,几乎可忽略不计。我们还发现,将 MoDA 与后归一化(post-norm)结合使用,其性能优于与前归一化(pre-norm)的组合。这些结果表明,MoDA 是支持深度扩展的一种极具潜力的基础组件。相关代码已开源:https://github.com/hustvl/MoDA。
一句话总结
华中科技大学与字节跳动的研究人员提出了混合深度注意力(Mixture-of-Depths Attention, MoDA),这是一种硬件高效的机制,通过支持动态跨层检索来缓解深度大语言模型中的信息稀释问题,从而以极小的计算开销提升下游任务性能。
主要贡献
- 本文提出了混合深度注意力(MoDA),这是一种统一机制,使每个注意力头能够动态地关注当前序列的键值对以及前序层的深度键值对,以缓解信息稀释。
- 提出了一种硬件高效的融合算法,通过感知分块(chunk-aware)的布局和感知分组(group-aware)的索引解决了非连续内存访问模式的问题,在 64K 序列长度下实现了 FlashAttention-2 97.3% 的效率。
- 在 15 亿参数模型上的大量实验表明,MoDA 始终优于 OLMo2 基线,在 10 个验证基准上将平均困惑度降低了 0.2,并将下游任务性能提高了 2.11%,而仅增加了 3.7% 的浮点运算量(FLOPs)。
引言
扩展大语言模型的深度对于增强其表征能力至关重要,然而更深的网络往往遭受信息稀释的困扰,即浅层中有价值的特征在经历多次残差更新后逐渐退化。此前尝试通过密集跨层连接来解决这一问题,虽然保留了历史信息,但引入了不可接受的参数增长;而标准的残差路径则无法在不显著增加开销的情况下防止信号丢失。作者提出了混合深度注意力(MoDA),这是一种允许每个注意力头动态地从当前序列和前序层中检索键值对以恢复丢失信息的机制。此外,他们还开发了一种硬件高效的融合算法,解决了非连续内存访问模式的问题,在 64K 序列长度下实现了 FlashAttention-2 97.3% 的效率,同时以可忽略的计算成本带来了持续的性能提升。
方法
作者提出了一种沿深度流堆叠 Transformer 块的新框架,将每个块概念化为一个三步过程:读取(read)、操作(operate)和写入(write)。这种视角使得我们可以系统地探索通过深度传播信息的机制,超越了标准的残差连接。
深度流机制
作者首先通过比较现有机制和中间机制确立了设计空间。标准深度残差连接使用恒等读取和加法写入,这可能导致由于重复叠加而引起的信号退化。深度密集(Depth Dense)方法通过拼接历史表征来缓解这一问题,但这会带来高昂的计算成本。为了平衡效率与自适应性,作者引入了深度注意力(Depth Attention),它以数据依赖的方式利用注意力机制读取历史深度信息。
这些机制的演进通过深度流设计的概念比较图进行了说明。
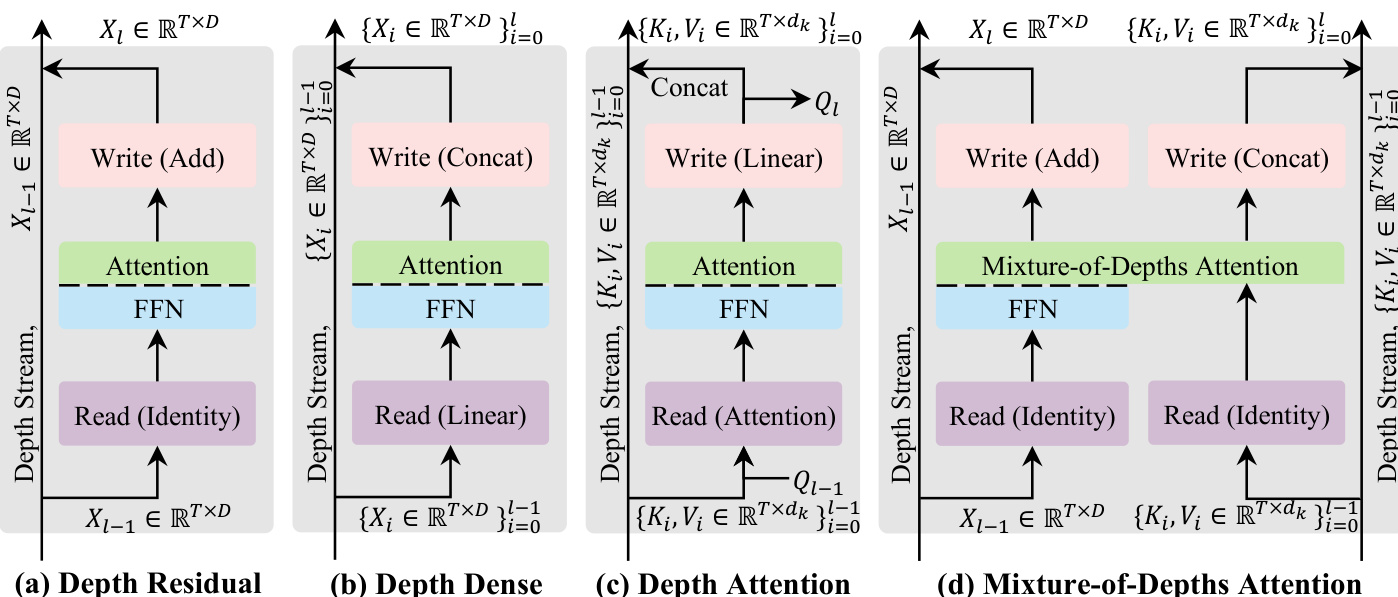
在深度注意力公式中,第 l 层的输入是通过对来自同一令牌位置跨层的 {Ki,Vi}i=0l−1 历史键值对进行注意力计算得出的。输出随后被投影为下一层的新查询、键和值对。
混合深度注意力 (MoDA)
在深度注意力的基础上,作者提出了混合深度注意力(MoDA),它将序列级检索和深度级检索统一到一个单一的 softmax 算子中。MoDA 读取当前隐藏状态 Xl−1 和历史深度键值流 {(Ki,Vi)}i=0l−1。在操作步骤中,每个令牌同时关注序列级的键值对及其自身的历史深度键值对,所有注意力分数联合归一化。
下图展示了集成 MoDA 的 Transformer 解码器架构以及由此产生的注意力机制可见关系。
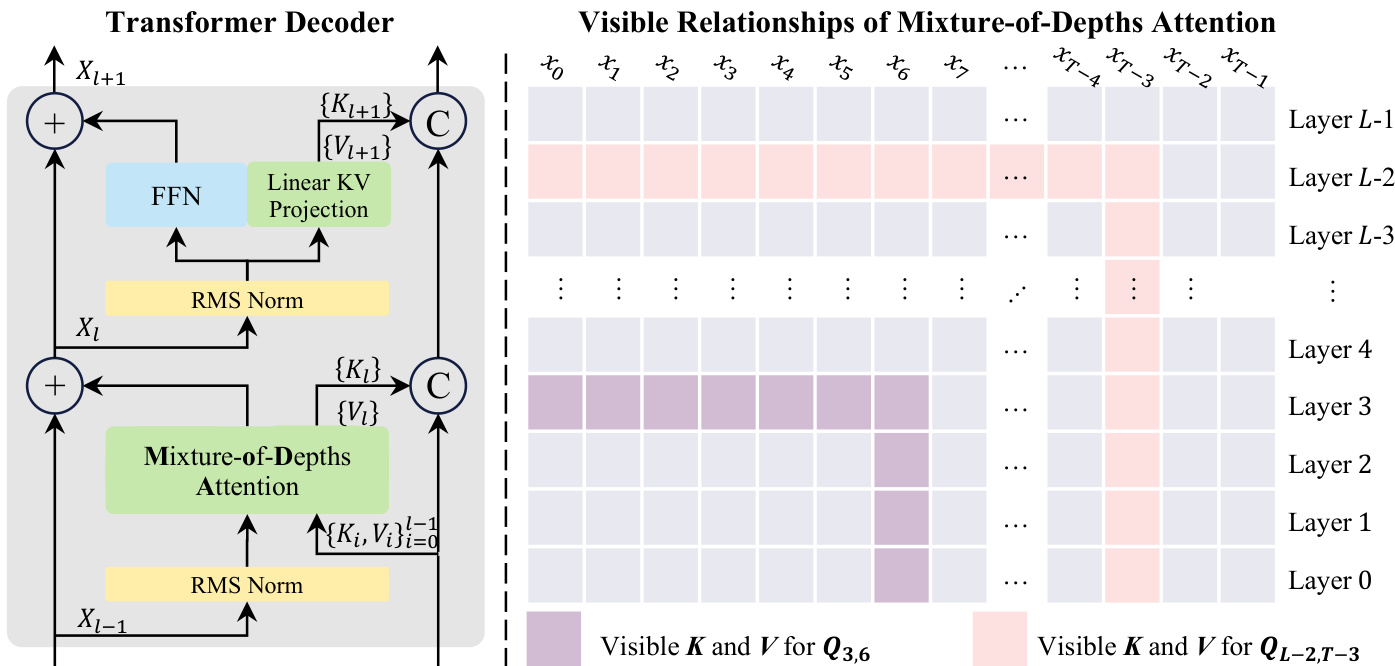
在写入步骤中,当前层的键值对被追加到深度流中供后续层使用。对于前馈网络(FFN)层,使用轻量级的 KV 投影来生成相应的键值对。这种设计使得 MoDA 能够高效地利用深度历史,其开销远低于密集跨层连接。
硬件高效实现
为了解决缓存所有深度键值状态所带来的内存和带宽瓶颈,作者开发了一种硬件感知实现。朴素的实现需要非连续读取,会降低 GPU 利用率。所提出的解决方案重新组织了深度流张量,以实现连续的内存访问和融合计算。
MoDA 深度缓存访问的硬件视图展示了两种关键的布局策略:Flash 兼容(Flash-Compatible)和分块/分组感知(Chunk/Group-Aware)。

Flash 兼容布局将深度缓存沿长度为 T×L 的单一轴展平,允许每个查询映射到连续的深度范围。然而,为了进一步提高深度利用率,分块/分组感知布局按分块大小 C 对查询进行分组。这将每个分块的有效深度跨度从 T×L 减少到 (C×L)/G,其中 G 是分组查询注意力(GQA)的组数。这种重组最大限度地减少了来自被屏蔽的、超出范围的深度条目的不必要 HBM 流量,并将查询块边界与 G 对齐以简化向量化执行。该实现遵循在线 softmax 更新过程,在归一化之前将来自序列和深度块的 logits 累积到单个片上状态中。
实验
- 效率比较表明,所提出的 MoDA 实现具有可预测的扩展性,随着序列长度的增加或深度利用率的提高,开销变得可忽略不计,同时在长序列场景中保持线性扩展行为。
- 大语言模型的变体分析显示,注入深度键值信息能以极小的计算成本显著提升性能,与重用注意力投影相比,专门为 FFN 层添加深度投影能带来最佳的精度 - 效率权衡。
- 扩展实验证实,MoDA 在不同模型规模(7 亿到 15 亿参数)和多样化的下游任务(包括常识推理和广泛知识基准)中都能提供稳定的性能提升,同时在多个数据域中持续降低验证困惑度。
- 层数研究表明,MoDA 在较浅和较深的模型配置中均保持有效,深度键值注入持续降低验证损失,并在更深层堆叠的后归一化(post-norm)设置中提供更大的收益。
- 注意力可视化显示,模型主动检索跨层深度信息,而不是仅依赖序列上下文,将注意力质量从典型的注意力汇(attention sinks)重新分配到更与任务相关的序列和深度位置。
- 内核实现消融实验验证,结合 Flash 兼容布局、分块感知设计和分组感知索引,相比朴素基线实现了巨大的加速,将运行时间减少了三个数量级以上。