Command Palette
Search for a command to run...
揭秘视频推理
揭秘视频推理
摘要
近期视频生成领域的进展揭示了一个出乎意料的现象:基于扩散的视频模型展现出显著的非平凡推理能力。先前的研究将这一能力归因于“帧链”(Chain-of-Frames, CoF)机制,即认为推理过程是沿视频帧顺序展开的。然而,本文挑战了这一假设,并揭示了一种根本不同的机制。我们证明,视频模型中的推理能力主要是在扩散去噪步骤(diffusion denoising steps)中涌现的。通过定性分析与针对性探测实验,我们发现模型在去噪的早期阶段会探索多个候选解,并逐步收敛至最终答案;我们将这一过程称为“步骤链”(Chain-of-Steps, CoS)。除这一核心机制外,我们还识别出若干对模型性能至关重要的涌现式推理行为:(1)工作记忆,支持对中间信息的持久引用;(2)自校正与增强,使模型能够从错误的中间解中恢复;(3)先感知后行动,即早期步骤建立语义 grounding,而后期步骤执行结构化操作。进一步地,在单个扩散步骤中,我们发现了 Diffusion Transformers 内部自演化的功能专业化现象:早期层编码密集的感知结构,中间层执行推理,而后期层则整合潜在表示。受上述发现启发,我们提出了一种无需训练的简单策略作为概念验证,展示了如何通过集成来自相同模型但不同随机种子的潜在轨迹(latent trajectories)来提升推理能力。总体而言,本文系统性地阐明了推理能力如何在视频生成模型中涌现,为未来研究提供了基础,以更好地利用视频模型内在的推理动力学,将其作为智能的新载体。
一句话总结
商汤研究院与南洋理工大学的学者提出,视频推理能力是在扩散去噪过程中通过“步骤链”(Chain-of-Steps)机制涌现的,而非跨越视频帧产生。这一发现揭示了自我修正等涌现行为,并使得一种无需训练的集成潜在轨迹策略成为可能,从而增强推理能力。
主要贡献
- 本文提出了“步骤链”(CoS)机制,证明了基于扩散的视频模型中的推理是沿着去噪步骤展开的,而非跨越视频帧。在此过程中,模型在早期探索多种候选解,并逐步收敛至最终答案。
- 本研究识别出三种对性能至关重要的涌现推理行为:用于持久参考的工作记忆、用于从中间错误中恢复的自我修正能力,以及“先感知后行动”的动态机制,即早期步骤建立语义基础,后续步骤执行操作。
- 提出了一种无需训练的推理策略,通过集成具有不同随机种子的相同模型的潜在轨迹来提升推理能力。实验表明,该方法保留了多样化的推理路径,并增加了收敛至正确解的可能性。
引言
基于扩散的视频模型最近在时空一致的环境中展现了意想不到的推理能力,为超越静态图像和文本的机器智能提供了新的基础。先前的研究错误地将这种能力归因于“帧链”(Chain-of-Frames)机制,即推理按顺序跨越视频帧展开,导致其真实的内部动态未被充分探索。作者通过揭示推理主要是在扩散去噪步骤中涌现的(他们将其称为“步骤链”),挑战了这一假设。他们识别出了模型架构中关键的涌现行为,如工作记忆、自我修正和功能层专业化。利用这些见解,团队引入了一种简单的无需训练的策略,通过集成多次模型运行的潜在轨迹,在生成过程中保留多样化的候选解,从而提升推理性能。
方法
所提出的框架基于 VBVR-Wan2.2,这是一个使用流匹配(flow matching)从 Wan2.2-I2V-A14B 架构微调而来的视频推理模型。其核心机制将扩散去噪过程视为推理的主要轴线。模型学习一个由提示 c 条件化的速度场 vθ(xs,s,c),引导潜在变量 xs 沿着由 xs=(1−s)x0+sx1 定义的连续传输路径,其中 x0 是干净潜在变量,x1 是噪声。通过在每个步骤估计干净潜在变量 x^0=xs−σs⋅vθ(xs,s,c),系统可视化了语义决策的演变。分析表明,早期的扩散步骤充当高层启发式搜索,模型在潜在工作空间中填充多个假设,而后续步骤则剪枝次优轨迹以收敛至解。
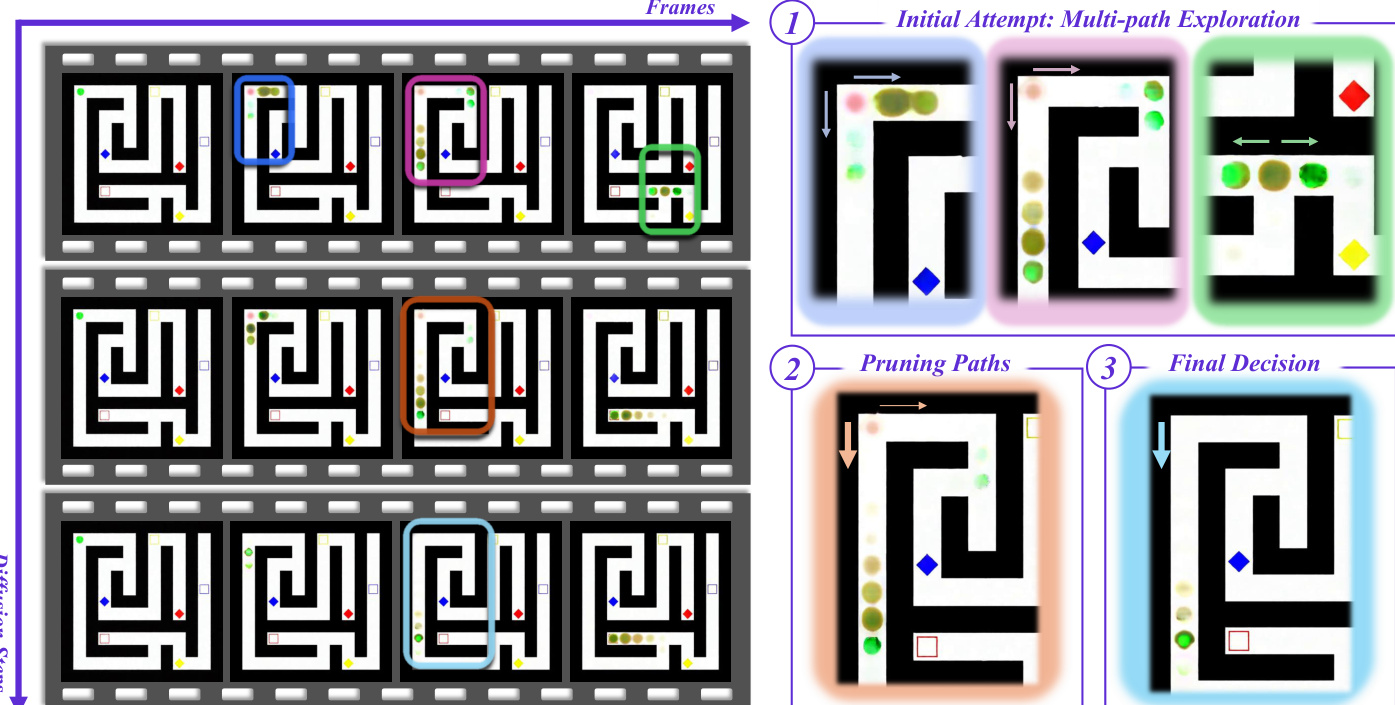
参考框架图以可视化迷宫求解任务中的多路径探索及随后的剪枝过程。
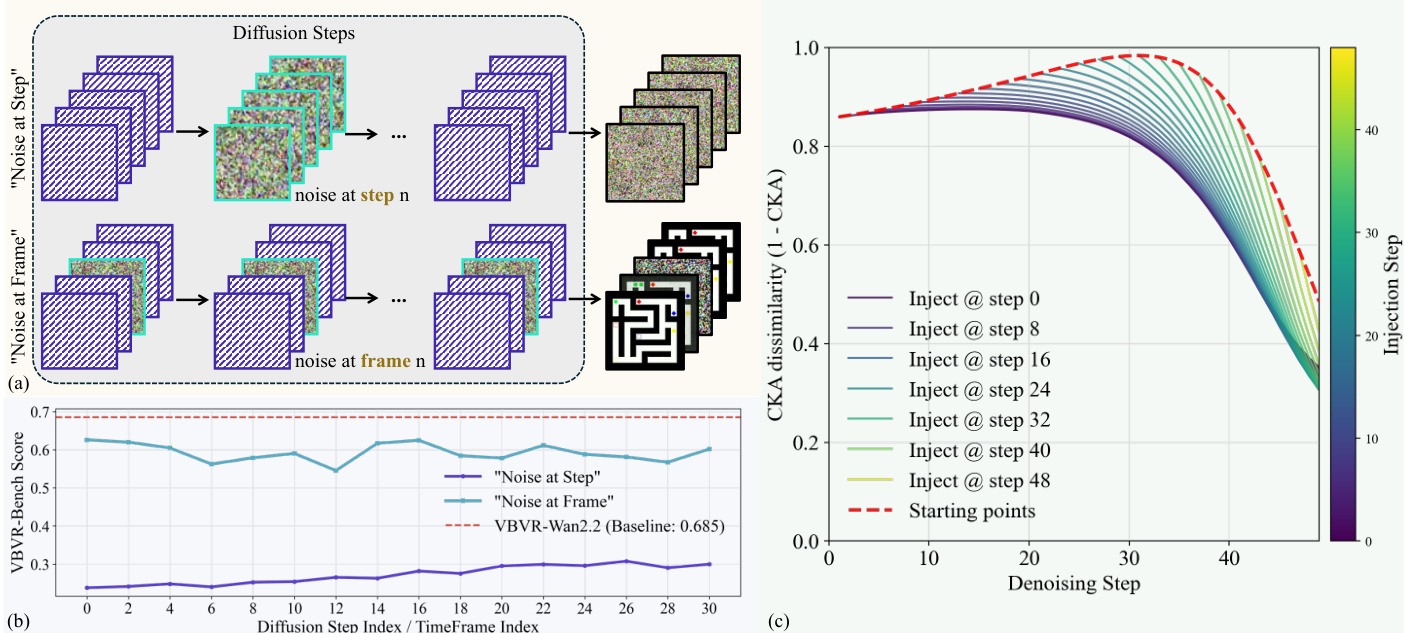
研究进一步分析了噪声注入策略对推理轨迹的影响,比较了在特定扩散步骤与视频帧中注入噪声的效果。
研究识别出两种截然不同的逐步推理模式:多路径探索(Multi-path Exploration),即并行生成多种可能性;以及基于叠加的探索(Superposition-based Exploration),即通过重叠状态完成模式。
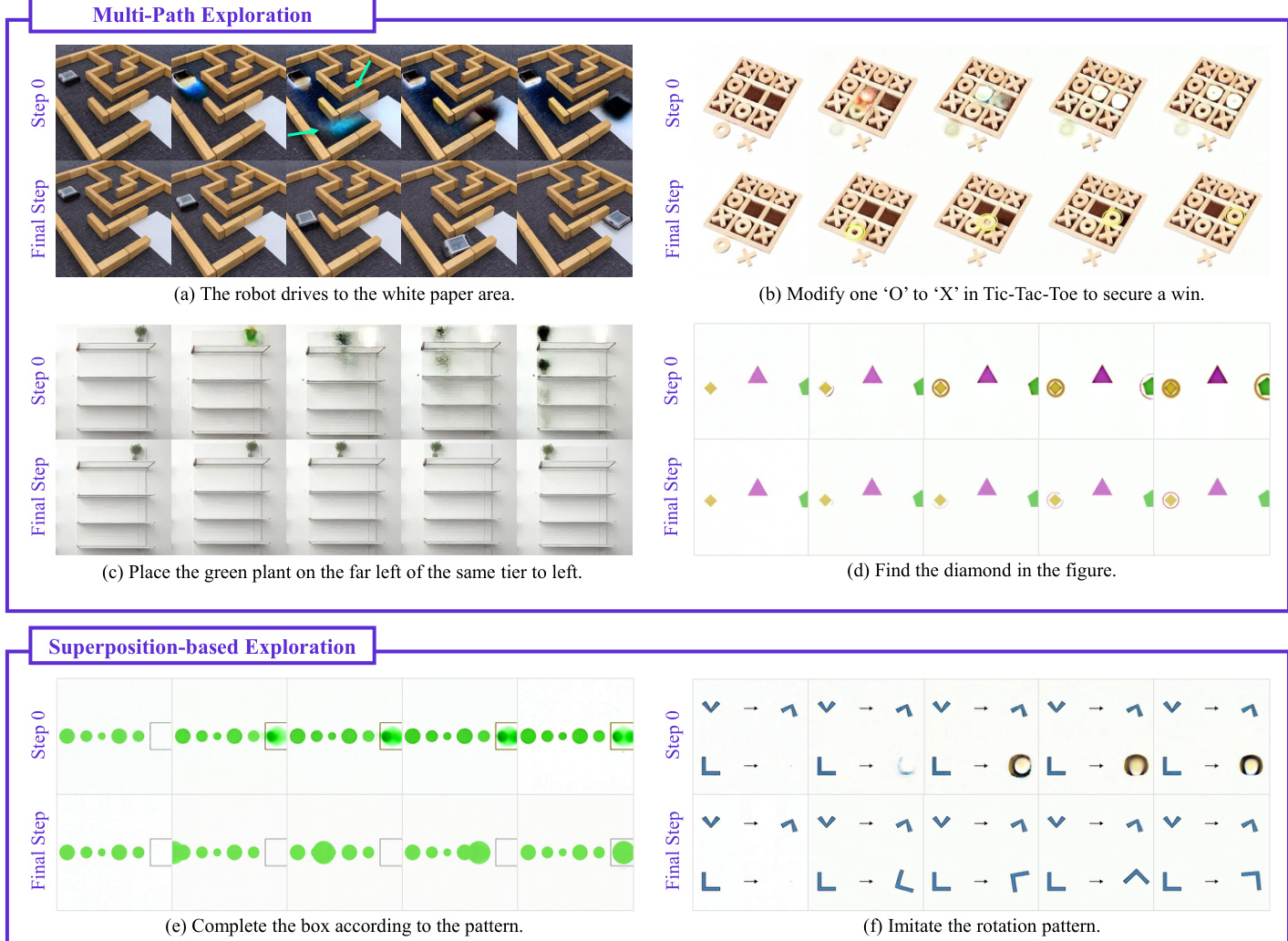
该架构展现出对复杂任务至关重要的涌现推理行为,包括用于保留关键信息的工作记忆,以及用于细化中间假设的自我修正能力。

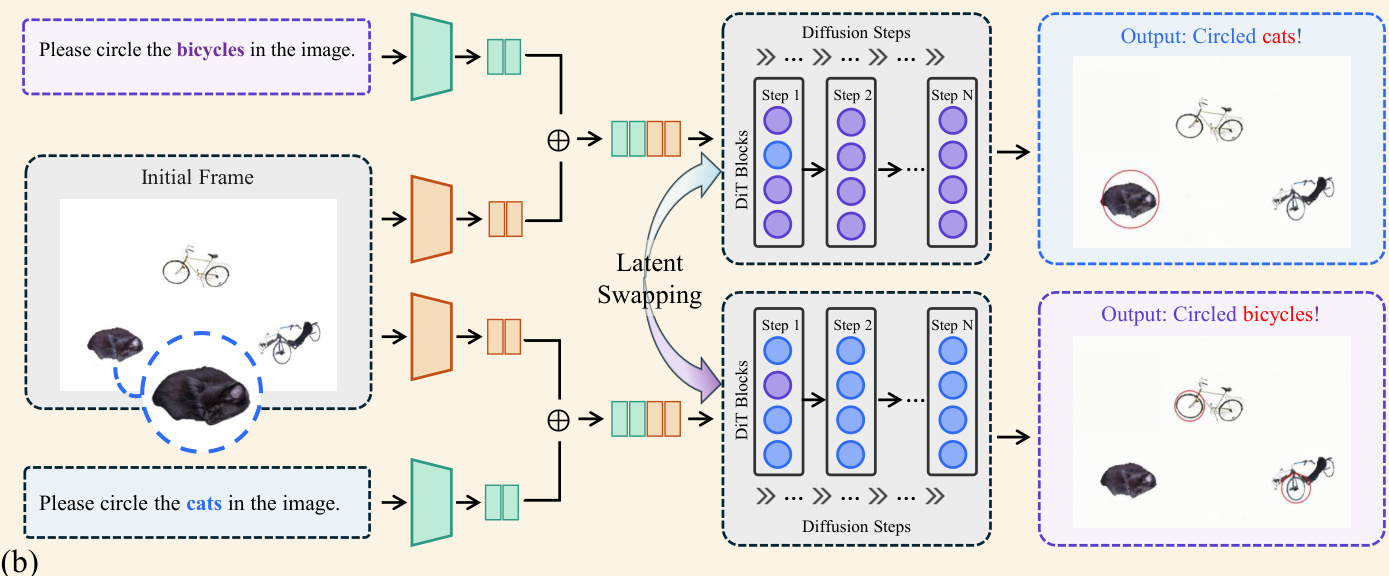
为了稳定这些推理轨迹,实施了一种无需训练的集成策略。该方法利用推理流形中共享的概率偏差,通过执行多次具有不同初始噪声种子的独立前向传递来实现。在关键的早期扩散步骤中,提取中间层(具体为第 20 至 29 层)的隐藏表示并进行时空平均。这种潜在空间集成过滤掉了特定种子的噪声,并将概率分布引导至更稳定的状态。
实验
- “步骤链”分析证实,视频推理发生在扩散去噪步骤之间,而非逐帧进行;模型在收敛至最终结果之前,会并行探索多条解路径。
- 噪声扰动实验证实,破坏特定的扩散步骤会严重降低性能,而破坏单个视频帧则更容易恢复,证明推理轨迹对逐步信息流高度敏感。
- 逐层机制分析揭示了一种分层处理结构:早期的 Transformer 层专注于全局背景上下文,而中间和后续层则集中于前景物体并执行关键的逻辑推理。
- 潜在变量交换实验表明,中间层编码了具有语义决定性的信息,因为改变这些特定深度的表示会直接反转最终的推理结果。
- 关于帧数和模型蒸馏的研究表明,虽然推理并不严格依赖于帧数,但维持最小帧数对于时空连贯性至关重要;而在蒸馏模型中激进的步骤压缩可能会破坏有效推理所需的潜在探索阶段。
- 定性观察识别出多种涌现行为,包括用于保留物体状态的工作记忆、用于修正错误初始假设的自我修正机制,以及“先感知后行动”的过渡,即静态基础建立先于动态运动规划。