Command Palette
Search for a command to run...
注意力残差
注意力残差
摘要
在现代 LLM 中,带有 PreNorm 的残差连接已成为标准配置,但其对所有层输出采用固定单位权重进行累加。这种均匀聚合方式导致隐藏状态随深度增加而无控增长,逐步稀释了各层的贡献。为此,我们提出了注意力残差(Attention Residuals, AttnRes),用基于 softmax 的注意力机制替代固定累加,使每一层能够根据学习到的、与输入相关的权重,有选择地聚合先前层的表示。针对大规模模型训练中因关注所有先前层输出而带来的内存与通信开销,我们进一步引入了分块注意力残差(Block AttnRes)。该方法将网络层划分为若干块,并仅在各块级别的表示上执行注意力计算,在保留大部分全量 AttnRes 优势的同时,显著降低了内存占用。结合基于缓存的流水线通信机制与两阶段计算策略,Block AttnRes 成为标准残差连接的实用化即插即用替代方案,且额外开销极小。扩展定律实验表明,该改进在不同模型规模下均表现一致;消融研究进一步验证了基于内容感知的深度方向选择机制的有效性。我们将 AttnRes 集成至 Kimi Linear 架构(总参数量 48B,激活参数量 3B),并在 1.4T tokens 上进行了预训练。结果表明,AttnRes 有效缓解了 PreNorm 带来的稀释效应,使输出幅值与梯度分布在深度维度上更加均匀,并显著提升了所有评估任务上的下游性能。
一句话总结
Kimi 团队提出了注意力残差(Attention Residuals),这是一种新颖的机制,用可学习的 softmax 注意力取代固定的残差权重,以缓解大语言模型中的隐藏状态稀释问题。其优化的 Block AttnRes 变体在降低内存开销的同时,显著提升了训练稳定性,并在各种模型规模下改善了下游任务的性能。
主要贡献
- 本文提出了注意力残差(AttnRes),该机制用可学习的 softmax 注意力取代了固定的单位权重累加,对前序层的输出进行聚合,从而实现跨深度的选择性、内容依赖的表示聚合。
- 为解决可扩展性问题,该工作提出了 Block AttnRes,将层划分为块,并对块级摘要进行注意力计算,将内存和通信复杂度从 O(Ld) 降低至 O(Nd),同时保留了性能提升。
- 在 480 亿参数模型上基于 1.4 万亿 token 预训练的综合实验表明,该方法有效缓解了隐藏状态稀释,产生了更均匀的梯度分布,并且与标准残差连接相比,持续提升了下游任务的性能。
引言
本研究致力于解决在保持高性能的同时高效扩展大语言模型的挑战,这是将先进 AI 部署到现实世界应用的关键需求。先前的方法往往难以应对注意力机制带来的计算开销,或者无法充分利用残差连接以实现大规模下的稳定训练。为了克服这些局限,作者引入了一个以注意力残差为核心的新框架,在优化信息流并降低训练成本的同时,不牺牲模型质量。
方法
作者提出了注意力残差(AttnRes)以解决标准残差连接在深度网络中的局限性。在标准架构中,隐藏状态更新遵循固定的递归关系 hl=hl−1+fl−1(hl−1),这展开后相当于对所有前序层输出的均匀求和。这种固定的聚合方式导致隐藏状态的幅度随深度线性增长,从而稀释了各层的贡献。AttnRes 用一种可学习的、依赖于输入的跨深度注意力机制取代了这种固定累加。
请参阅框架图以直观对比不同的残差连接变体。
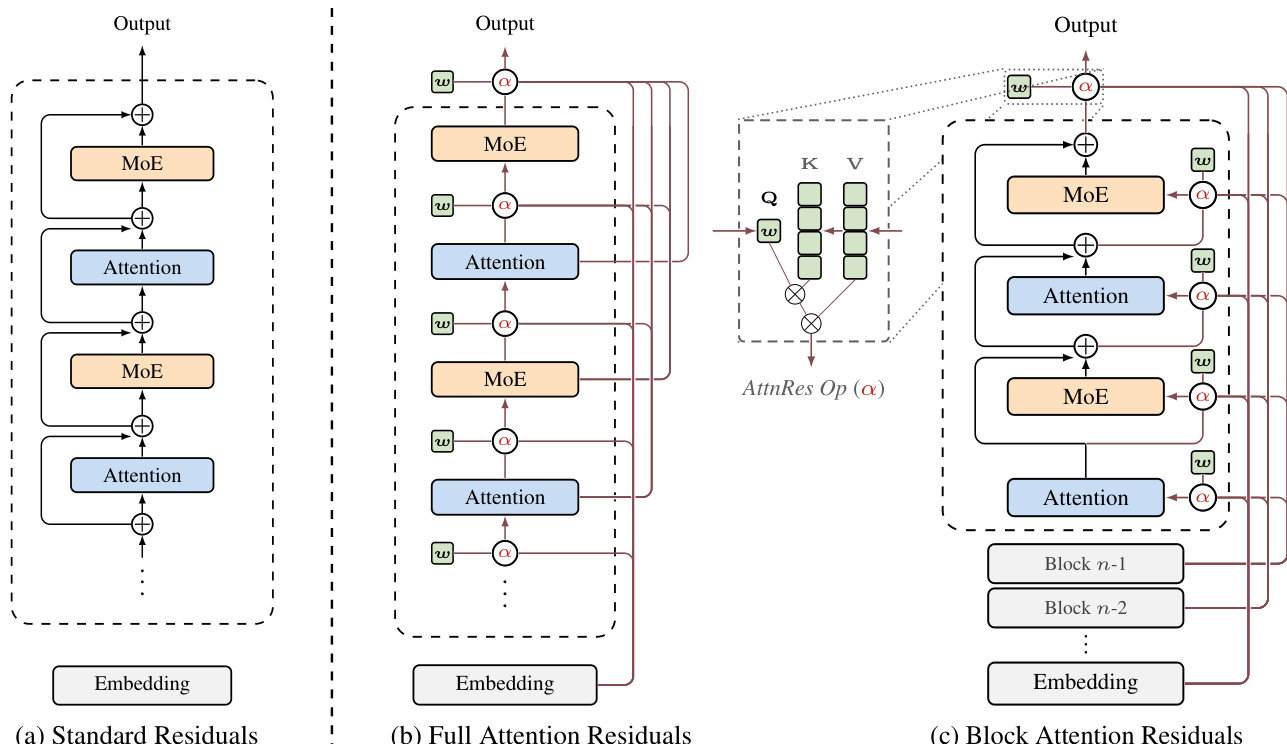
如图所示,标准方法(a)仅简单地将前一层输出相加。相比之下,Full AttnRes(b)允许每一层通过可学习的注意力权重选择性地聚合所有前序层的输出。具体而言,第 l 层的输入计算为 hl=∑i=0l−1αi→l⋅vi,其中 vi 表示第 i 层的输出(当 i=0 时为嵌入向量)。注意力权重 αi→l 通过对核函数 ϕ(ql,ki) 进行 softmax 计算得出,其中 ql=wl 是特定于第 l 层的可学习伪查询向量,而 ki=vi 是从前序输出导出的键。该机制实现了以极小的参数开销进行跨深度的内容感知检索。
为了使该方法适用于大规模模型,作者引入了 Block AttnRes(c)。该变体将 L 层划分为 N 个块。在每个块内,层输出通过求和缩减为单个表示,且注意力仅应用于这 N 个块级表示。这将内存和通信复杂度从 O(Ld) 降低至 O(Nd)。块内累加定义为 bn=∑j∈Bnfj(hj),其中 Bn 是块 n 中的层集合。块间注意力随后在这些块摘要上运行,允许块内的层关注之前的块以及当前块的累加和。
为了支持大规模高效训练,该方法结合了特定的基础设施优化,以处理跨流水线阶段的块表示通信。如流水线通信示例所示,采用了跨阶段缓存以消除冗余数据传输。
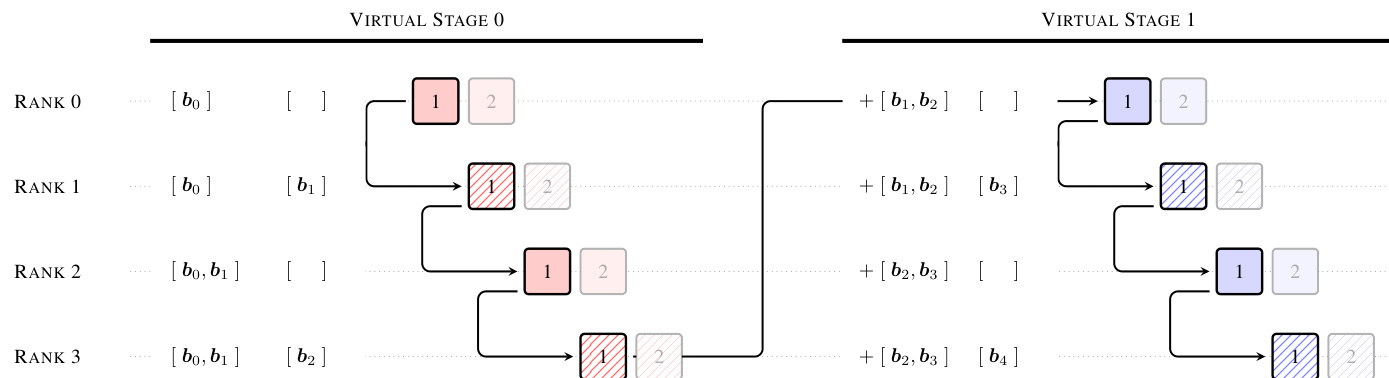
在此设置中,在早期虚拟阶段接收到的块会被本地缓存。因此,阶段转换仅传输自接收方在上一虚拟阶段对应块以来累积的增量块,而非完整历史。这种缓存策略显著降低了每次转换的峰值通信成本,使该方法能够作为标准残差连接的实用即插即用替代品,且训练开销极小。此外,在推理过程中采用两阶段计算策略以分摊跨块注意力成本,进一步最小化了延迟。
实验
- 扩展定律实验验证了 Full 和 Block 注意力残差(AttnRes)在所有模型规模下均持续优于 PreNorm 基线,其中 Block AttnRes 在保持较低内存开销的同时,恢复了 Full 变体的大部分性能增益。
- 主要训练结果表明,AttnRes 通过限制隐藏状态的增长并实现更均匀的梯度分布,解决了 PreNorm 的稀释问题,从而在多步推理、代码生成和知识基准测试中取得了更优越的性能。
- 消融研究证实,通过 softmax 注意力实现的输入依赖加权对性能至关重要,而块级聚合在内存效率与访问深层层的能力之间提供了有效的权衡,优于滑动窗口或全跨层访问。
- 架构扫描显示,与标准 Transformer 相比,AttnRes 将最优设计偏好转向更深更窄的网络,表明该方法能更有效地利用增加的深度来促进信息流。
- 对 learned 注意力模式的分析表明,AttnRes 在保持局部性的同时,建立了指向早期层和 token 嵌入的可学习跳跃连接,而 Block AttnRes 通过隐式正则化成功维持了这些结构优势。