Command Palette
Search for a command to run...
OpenSeeker:通过完全开源训练数据,推动前沿搜索 Agent 的民主化
OpenSeeker:通过完全开源训练数据,推动前沿搜索 Agent 的民主化
Yuwen Du Rui Ye Shuo Tang Xinyu Zhu Yijun Lu Yuzhu Cai Siheng Chen
摘要
深度搜索能力已成为前沿大语言模型(LLM)智能体(Agent)不可或缺的核心能力。然而,由于缺乏透明且高质量的训练数据,高性能搜索智能体的研发长期被工业巨头所主导。这一持续存在的数据稀缺问题,从根本上阻碍了广大研究社区在该领域的开发与创新进程。为弥合这一差距,我们推出了 OpenSeeker。这是首个实现前沿级性能的全开源搜索智能体(包含模型与数据),其核心突破源于两项技术创新:(1) 基于事实的可扩展可控问答合成:通过拓扑扩展与实体混淆技术逆向构建网络图,生成具有可控覆盖范围与复杂度的复杂多跳推理任务;(2) 去噪轨迹合成:采用回溯总结机制对轨迹进行去噪处理,从而引导教师 LLM 生成高质量的动作。实验结果表明,OpenSeeker 仅需在一次训练运行中使用 11.7k 个合成样本进行训练,即可在 BrowseComp、BrowseComp-ZH、xbench-DeepSearch 和 WideSearch 等多个基准测试中达到最先进(SOTA)的性能。值得注意的是,仅通过简单的监督微调(SFT)训练,OpenSeeker 的表现便显著超越了目前排名第二的全开源智能体 DeepDive(例如在 BrowseComp 基准上,29.5% 对 15.3%);甚至在 BrowseComp-ZH 基准上,其表现(48.4% 对 46.7%)也超越了经过大规模持续预训练、监督微调及强化学习(RL)训练的工业界竞争对手 Tongyi DeepResearch。我们已完全开源了完整的训练数据集与模型权重,旨在推动前沿搜索智能体研究的民主化,并构建一个更加透明、协作的生态系统。
一句话总结
来自上海交通大学的研究人员推出了 OpenSeeker,这是一个完全开源的搜索智能体。它利用基于事实的可扩展问答合成与去噪轨迹技术,仅通过简单的监督微调,便在复杂基准测试中实现了最先进(SOTA)的性能。
主要贡献
- 本文提出了一种基于事实的可扩展可控问答合成方法,通过拓扑扩展和实体模糊化逆向工程构建网络图,生成具有可调节难度的复杂多跳推理任务。
- 提出了一种去噪轨迹合成技术,利用回顾性摘要清理教师模型的历史上下文,从而生成高质量的动作序列;同时让智能体在原始噪声数据上进行训练,以提升其鲁棒性。
- 本文发布了完全开源的 OpenSeeker 智能体,包括其完整的训练数据集和模型权重。该智能体仅使用 11.7k 个合成样本进行简单的监督微调,便在多个基准测试中取得了最先进(SOTA)的性能。
引言
深度搜索能力对于大型语言模型智能体在互联网上导航以获取准确、实时的信息至关重要,然而由于缺乏透明、高质量的训练数据,该领域长期被工业巨头主导。先前的开源努力未能弥合这一差距,因为它们要么扣留训练数据集,要么仅发布部分数据,要么依赖无法支持前沿性能的保真度较低的样本。为了解决这些局限性,作者推出了 OpenSeeker,这是首个完全开源的搜索智能体。它通过两项关键创新实现了最先进(SOTA)的结果:利用基于事实的可扩展可控问答合成功能生成复杂的多跳推理任务,以及利用去噪轨迹合成技术教导模型如何从噪声网络内容中提取信号。
数据集
-
数据集构成与来源:作者通过逆向工程网络图,构建了一个包含复杂查询、真实答案和最优工具使用轨迹的高保真数据集 D。他们利用了约 68GB 的英文和 9GB 的中文网络数据,将每个查询锚定在现实世界的拓扑结构中,确保事实依据并消除幻觉风险。
-
各子集的关键细节:合成流程分为两个阶段:生成构建(Generative Construction)用于创建候选对,双重标准验证(Dual-Criteria Verification)用于筛选难度和可解性。任务难度是刻意的设计选择,通过调整子图大小 k 来控制,从而校准推理复杂度和信息覆盖范围,构建出从直接检索到多跳调查的课程体系。
-
模型使用与训练策略:该数据集训练智能体掌握长视野的工具调用,强制其基于原始历史预测专家级的推理和工具调用。训练混合集利用合成对来教导模型处理需要扩展“推理 → 工具调用 → 工具响应”交互链的复杂查询。
-
处理与去噪策略:合成与训练之间存在独特的不对称性。在合成阶段,作者采用回顾性摘要机制,将原始工具响应压缩为摘要版本,以帮助教师生成高质量的推理。然而,最终的训练和推理阶段仅在原始工具响应上运行,迫使模型从内在学习去噪能力,并从噪声上下文中提取相关信息。
方法
所提出的框架通过两个不同的阶段运行:复杂问答对的生成构建以及去噪推理轨迹的合成。
生成构建与验证
作者利用基于图的流程构建高质量的问答对,如下面的框架图所示。

该过程始于问答生成模块。为了模拟自然的信息发现,系统从网络语料库中采样一个种子节点 vseed,并通过遍历出边将其扩展,形成局部依赖子图 Gsub。该子图作为拓扑链接的知识库。为了减少噪声,提取函数识别中心主题 ytheme 并将关键实体提炼为压缩的实体子图 Gentity。生成器 Pgen 随后基于 Gentity 合成初始问题 qinit,并施加结构约束,即推导答案需要遍历多条边。
为了防止智能体利用特定关键词,流程应用了模糊化处理。模糊化算子 Φ 将具体实体 e 映射为模糊描述 e~=Φ(e),从而创建模糊实体子图 G~entity。最终问题 q~ 是通过重写 qinit 以融入这些模糊描述而生成的,同时保留推理逻辑。
生成之后,问答验证器模块采用基于两个标准的拒绝采样方案。首先,难度检查确保问题无法由基础模型 πbase 在闭卷设置下解决(I[πbase(q~)=y]),从而保证外部工具的必要性。其次,可解性检查通过确认模型在提供完整实体子图 Gentity 作为上下文时能够推导出答案 y,来验证逻辑一致性(I[πbase(q~∣Gentity)=y])。
去噪轨迹合成
为了解决网络规模搜索中信息保留与上下文窗口限制之间的挑战,作者提出了一个将生成上下文与训练上下文解耦的合成框架。该过程如下面的轨迹合成图所示。
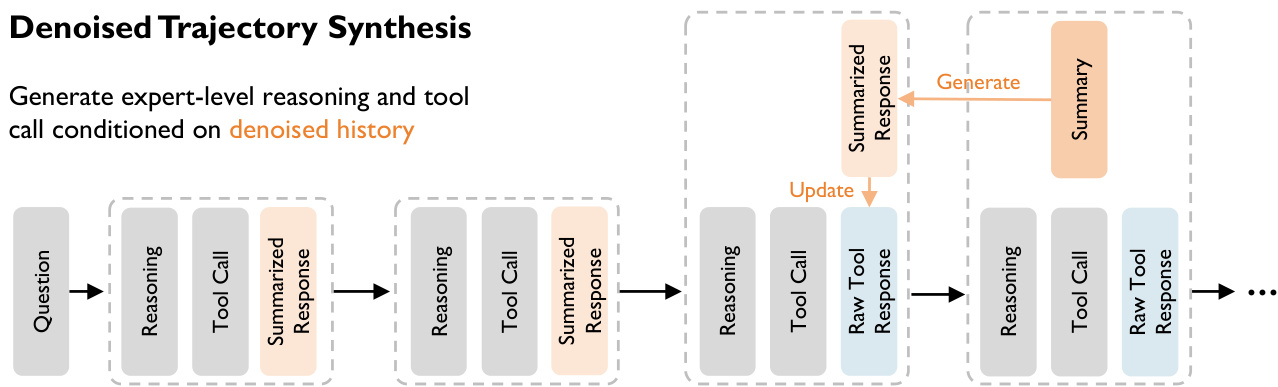
合成采用动态上下文去噪策略,使用“摘要历史 + 原始近期”协议。在任何步骤 t,智能体基于上下文 Ht 生成推理和动作对 (rt,at)。该上下文包括一个摘要化的长期历史,其中过去的观察 oi 被压缩为语义摘要 si,以及来自前一步的原始观察 ot−1。这确保了智能体能够访问最新观察中的所有信号,同时保持对过去的简洁记忆。
该框架在双阶段循环中运行。在决策阶段,智能体利用完整的原始观察 ot−1 来指导其下一步行动。在随后的压缩阶段,一旦获得新观察 ot,摘要器将前一个观察 ot−1 压缩为 st−1,该摘要将替代长期历史中的原始数据用于下一步。
最后,作者实施了一种不对称上下文训练策略以培养鲁棒性。轨迹由“教师”模型使用包含摘要的干净、去噪上下文合成。然而,对于最终训练数据集,“学生”模型被监督以在给定噪声原始上下文 Httrain(去除了摘要)的情况下预测最优推理和动作。这迫使学生在隐式层面学习去噪和信息提取能力,内化处理现实世界非结构化数据所需的逻辑。
实验
- OpenSeeker 仅通过在小型高质量数据集上进行监督微调进行训练,在测试多步导航和深度研究的基准测试中,其表现优于资源密集型的专有模型和复杂的多阶段训练基线,验证了数据质量胜过训练复杂度。
- 与规模相似的模型进行的比较表明,OpenSeeker 的合成数据比更大、噪声更多的数据集显著更有效,证明其去噪轨迹合成成功教导智能体从复杂的网络观察中提取关键信息。
- 与同期学术和企业工作的性能评估确认,OpenSeeker 在数据完全透明且仅采用轻量级监督微调(SFT)方法的情况下实现了最先进(SOTA)的结果,确立了战略性的数据合成可以替代大规模计算和强化学习循环。
- 难度分析显示,合成训练数据在工具调用和令牌长度方面超过了标准基准的复杂度,这种高保真挑战与模型在困难信息检索任务上的卓越性能直接相关。