Command Palette
Search for a command to run...
对齐使语言模型具备规范性,而非描述性。
对齐使语言模型具备规范性,而非描述性。
Eilam Shapira Moshe Tennenholtz Roi Reichart
摘要
后训练对齐(Post-training alignment)旨在优化语言模型以匹配人类偏好信号,然而这一目标并不等同于对观测到的人类行为进行建模。我们在多轮战略博弈(包括讨价还价、说服、谈判以及重复矩阵博弈)中,基于超过 10,000 项真实人类决策,对 120 对“基座模型 - 对齐模型”进行了对比评估。结果表明,在这些情境下,基座模型在预测人类选择方面的表现优于其对齐版本,优势比例接近 10:1;该结论在不同模型家族、提示词(prompt)构建方式以及博弈配置下均具有稳健性。然而,在人类行为更可能遵循规范性预测的情境中,上述模式发生逆转:在对所有 12 类单轮教科书式博弈的测试中,以及在不涉及策略性的彩票选择任务中,对齐模型均占据主导地位;甚至在多轮博弈内部,在第一轮(即交互历史尚未形成之前),对齐模型同样表现更佳。这种边界条件模式表明,对齐过程引入了规范性偏差(normative bias):当人类行为能被规范性解较好地刻画时,对齐有助于提升预测能力;而在多轮战略情境中,由于人类行为受到互惠、报复以及依赖历史情境的适应性等描述性动态(descriptive dynamics)的塑造,对齐反而会损害预测性能。这些结果揭示了在“为人类使用而优化模型”与“将模型作为人类行为的代理”之间存在的根本性权衡。
一句话总结
以色列理工学院的研究人员揭示,后训练对齐引入了规范性偏差,导致对齐模型在预测人类行为时表现失败,而在多轮战略博弈中,基础模型以 10:1 的优势胜出;相比之下,对齐版本仅在单次博弈或非战略场景中取得成功。
主要贡献
- 本文对 120 对基础模型与对齐模型进行了系统性比较,涉及四个多轮战略博弈家族中的 10,000 多个真实人类决策,揭示出基础模型在预测人类选择方面比其对齐版本高出近 10:1 的优势。
- 这项工作提出了一种确定性令牌概率提取方法,该方法绕过文本生成,直接测量模型内部分布与人类决策分布的匹配程度,从而能够在相同输入下公平地比较基础模型和对齐变体。
- 结果表明,对齐诱导了一种规范性偏差,提高了单次教科书式博弈和非战略彩票选择中的预测准确性,但在多轮战略环境中显著降低了性能,因为在这些环境中,人类行为受互惠和依赖历史的适应性驱动。
引言
研究人员越来越多地使用对齐的大语言模型作为行为代理,以模拟人类观点并预测实验结果,但这一做法假设对齐能够保持行为保真度。先前的研究表明,RLHF 和指令微调等对齐技术往往会压缩观点多样性、引入认知偏差并削弱推理能力,但这些发现主要局限于静态判断,而非动态战略互动。作者通过首次对四个博弈家族中的 120 对模型进行基础模型与对齐模型的系统性比较,填补了这一空白,证明对齐使模型变得具有规范性而非描述性,并显著降低了其预测人类完整战略行为范围的能力。
数据集
-
数据集构成与来源 作者在四个战略博弈家族和两个边界条件数据集上评估了模型。主要的战略数据来自 GLEE 基准(Shapira 等人,2024b)和 Akata 等人(2025),而边界测试则利用 Zhu 等人(2025)的程序化生成矩阵博弈以及 Marantz 和 Plonsky(2025)的二元彩票选择。
-
每个子集的关键细节
- 讨价还价:基于鲁宾斯坦模型,该子集包含 1,788 个人类决策,其中玩家交替出价,可选附带自由文本消息,并面对以通胀形式呈现的折现因子。
- 说服:一个持续 20 轮的重复廉价交谈博弈,包含 3,180 个人类决策,其中买家根据卖家的消息决定是否购买,包含长期买家和短视买家两种变体。
- 谈判:双边价格谈判,涉及 1,182 个人类决策,包含三元选择:接受、拒绝或采取与第三方合作的外部选项。
- 重复矩阵博弈:包含 3,900 个决策(每场游戏 1,950 个),来自 195 名参与者,他们与预计算的 GPT-4 策略进行 10 轮囚徒困境和性别战博弈。
- 单次矩阵博弈:程序化生成的一组 2,416 场游戏,涵盖 12 种拓扑结构,包含约 93,000 个聚合的人类决策,过滤后保留 71 个有效对。
- 二元彩票选择:包含 1,001 个非战略问题,参与者在赌博之间进行选择,过滤后保留 90 个有效对。
-
数据使用与处理 作者利用这些数据集在 120 对同一提供商的基础 - 对齐模型对上生成了超过 240 万个预测。对于 GLEE 游戏,人类参与者通过网页界面与 LLM 对手互动,且不知道对手的性质,确保决策未受偏见污染。重复矩阵博弈被格式化为多轮提示,包含收益矩阵和轮次历史。单次矩阵博弈采用平衡格式以控制位置偏差,而彩票选择则以文字描述形式呈现。
-
过滤与元数据构建 该研究排除了基础模型和对齐检查点相同,或对齐模型缺少聊天模板的模型对。对于边界条件数据集,作者应用严格过滤以仅保留有效的同一提供商对,最终在单次矩阵游戏中保留 71 对,在彩票选择中保留 90 对。评估涵盖每模型 10,050 个人类决策,以确保在不同博弈结构下的统计稳健性。
方法
作者将人类决策预测构建为令牌概率提取任务。对于博弈中的每个人类决策点,他们构建一个提示,包含描述游戏规则和参与者角色的系统消息。随后是直到该特定决策点的对话历史。模型随后执行单次前向传递,从最终位置的下一个令牌分布中提取分配给每个决策令牌的 log-概率。例如,在讨价还价场景中,令牌可能是“接受”与“拒绝”。
他们归一化提取的概率以获得预测的决策分布。接受概率的公式定义为:
paccept=∑dp(d)p(yes)其中 d 遍历给定家族的所有决策令牌。这包括讨价还价、说服和矩阵博弈的两个令牌,而谈判则增加一个用于外部选项的第三个令牌。生成的 paccept 值落在 [0,1] 范围内,并捕捉模型对肯定行动的相对偏好。这种归一化消除了非决策令牌的影响。
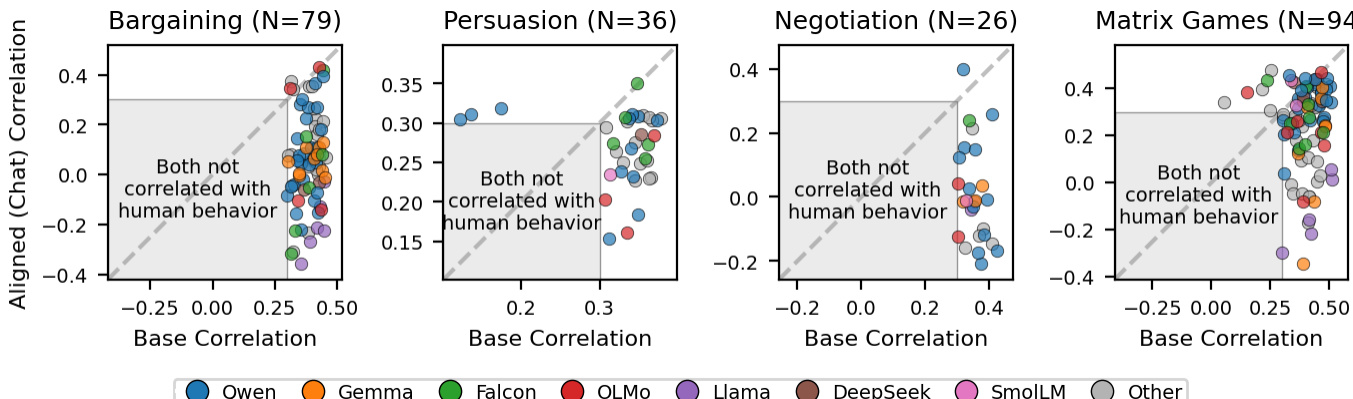
该方法不需要文本生成,也不需要采样。它是模型在决策令牌上的内部概率分布的确定性提取。该方法适用于基础模型和对齐模型,无需不同的解码策略。然而,仅当决策令牌获得大量概率质量时,归一化才是稳健的。当模型将质量主要分配给非决策令牌时,归一化概率变得不可靠。为了解决这个问题,作者在每个博弈家族上应用了两个对级过滤器。第一个是质量过滤器,排除任一模型分配给决策令牌的平均概率质量低于 80% 的对。第二个是最小相关性过滤器,排除两个模型与人类决策的相关性均低于 0.3 的对。这些过滤器在每个家族中独立应用,以确保基础优势在阈值选择上保持稳健。
实验
- 多轮战略博弈(讨价还价、说服、谈判、重复矩阵博弈)验证了基础模型在预测实际人类行为方面显著优于对齐模型,因为对齐引入了规范性偏差,抑制了互惠和报复等描述性动态。
- 单次教科书式博弈和非战略彩票选择验证了对齐模型在人类行为与规范性预测一致的环境中表现出色,表明当缺乏互动历史时,对齐提高了准确性。
- 多轮博弈中的逐轮分析证实,对齐模型在历史积累之前的初始轮次中表现更好,但随着互动历史的发展和战略动态的出现,其预测优势逐渐丧失。
- 跨模型家族、提示格式和博弈参数的稳健性测试验证了性能差距是由模型权重和对齐效应驱动的,而非提示格式或特定博弈配置。
- 总体结论确立了一个根本性的权衡:对齐优化了模型以服务于人类使用和规范性理想,但降低了其作为描述复杂、依赖历史的人类行为代理的效用。