HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

往事并非过往:基于 Memory 增强的 Dynamic Reward Shaping

QuanBench+: 一个用于 LLM-Based 量子代码生成的统一多框架 benchmark


























往事并非过往:基于 Memory 增强的 Dynamic Reward Shaping
QuanBench+: 一个用于 LLM-Based 量子代码生成的统一多框架 benchmark
ELT:用于视觉生成的弹性循环Transformer
ECHO: 基于 One-step Block Diffusion 的高效胸部 X 线报告生成
Matrix-Game 3.0:具有长时程 Memory 的实时流式交互式 World Model
EXAONE 4.5 技术报告
RefineAnything: 用于完美局部细节的多模态区域特定 Refinement
FORGE:面向制造场景的细粒度 Multimodal Evaluation
WildDet3D: 在野外环境下扩展 Promptable 3D Detection
Autoreason: 知晓何时停止的自我修正机制
ActiveGlasses: 通过主动视觉从自我中心视角人类演示中学习操纵技能
MegaStyle:通过一致性 Text-to-Image Style Mapping 构建多样化且可扩展的 Style Dataset
当数字开口说话:在 Text-to-Video Diffusion Models 中对齐文本数字与视觉实例
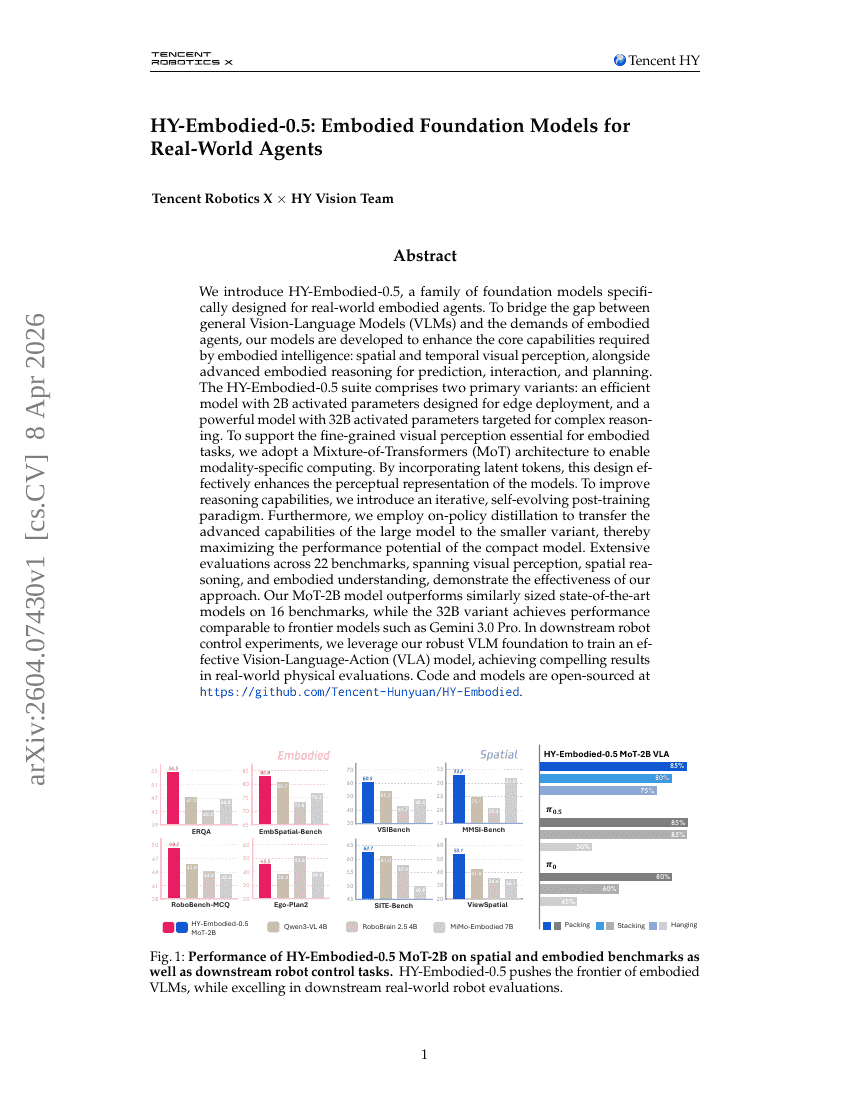
HY-Embodied-0.5:面向真实世界 Agent 的 Embodied Foundation Models
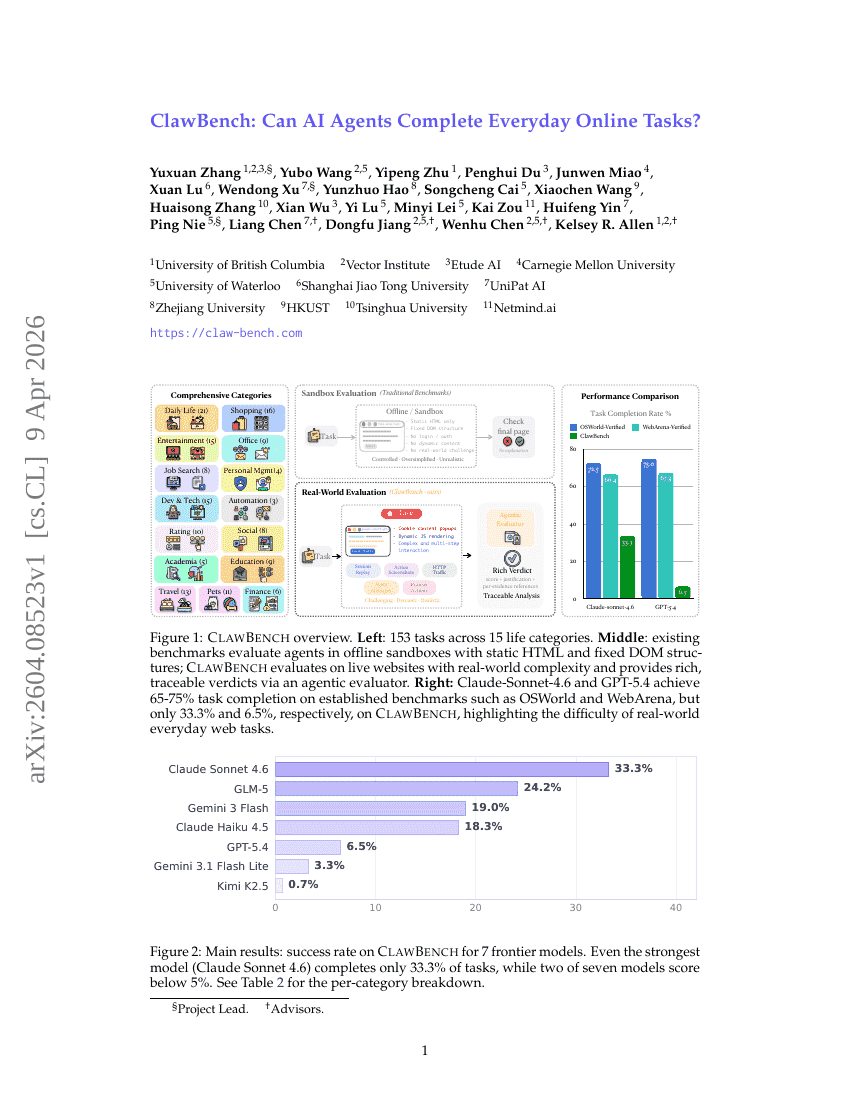
ClawBench:AI Agent 能否完成日常在线任务?
重新审视推理 SFT 中的泛化问题:基于优化、数据与模型能力的条件分析
SkillClaw:通过 Agentic Evolver 实现技能的集体进化
MDPBench:面向真实场景的多语言文档解析基准测试
TC-AE:解锁深度压缩 Autoencoders 的 Token 容量
INSPATIO-WORLD:一种基于时空 Autoregressive Modeling 的实时 4D 世界 Simulator
FlowInOne: 将多模态生成统一为“图像输入、图像输出”的 Flow Matching
MARS:赋能 Autoregressive Models 的 Multi-Token Generation
以笔触而非像素进行思考:通过交织推理实现的流程驱动型图像生成
RAGEN-2:Agentic RL 中的推理崩溃
Vanast: 通过合成三元组监督实现基于人体图像动画的虚拟试穿
ThinkTwice:面向推理与自我修正的 Large Language Models 联合优化研究
ACES:谁在测试测试集?面向代码生成任务的留一法(Leave-One-Out)AUC 一致性研究
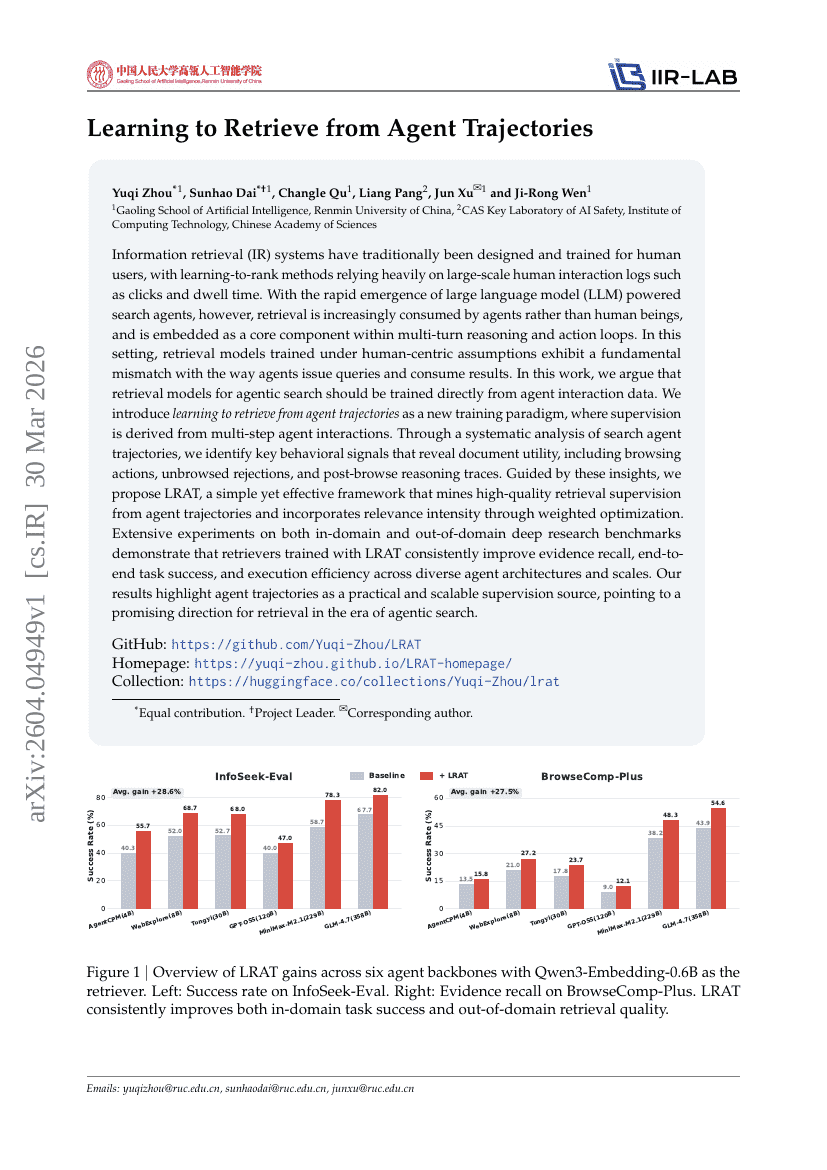
从 Agent Trajectories 中学习检索
Claw-Eval:迈向自主 Agent 的可信 Evaluation
Video-MME-v2:迈向全面视频理解 Benchmark 的下一阶段
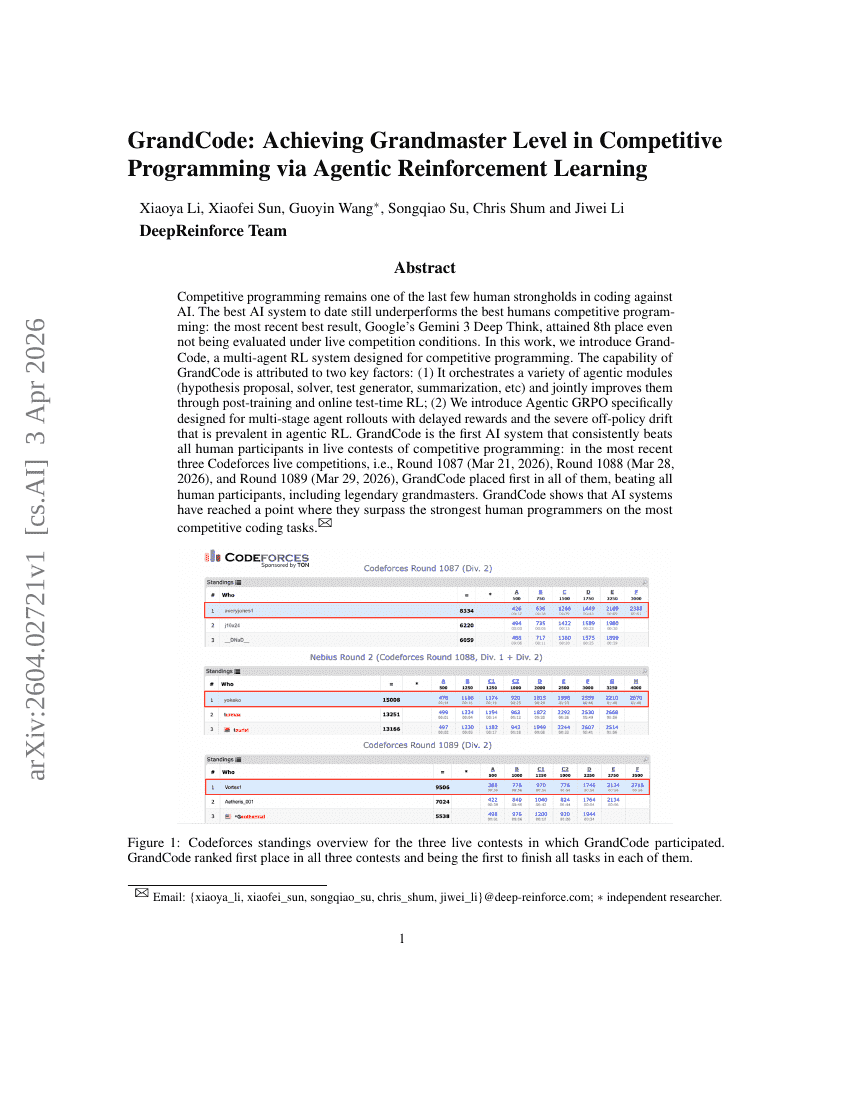
GrandCode: 通过 Agentic Reinforcement Learning 实现竞技编程中的 Grandmaster 水平
LIBERO-Para:针对 VLA 模型改写鲁棒性的诊断性 benchmark 与评估指标
ELT:用于视觉生成的弹性循环Transformer
ECHO: 基于 One-step Block Diffusion 的高效胸部 X 线报告生成
Matrix-Game 3.0:具有长时程 Memory 的实时流式交互式 World Model
EXAONE 4.5 技术报告
RefineAnything: 用于完美局部细节的多模态区域特定 Refinement
FORGE:面向制造场景的细粒度 Multimodal Evaluation
WildDet3D: 在野外环境下扩展 Promptable 3D Detection
Autoreason: 知晓何时停止的自我修正机制
ActiveGlasses: 通过主动视觉从自我中心视角人类演示中学习操纵技能
MegaStyle:通过一致性 Text-to-Image Style Mapping 构建多样化且可扩展的 Style Dataset
当数字开口说话:在 Text-to-Video Diffusion Models 中对齐文本数字与视觉实例
HY-Embodied-0.5:面向真实世界 Agent 的 Embodied Foundation Models
ClawBench:AI Agent 能否完成日常在线任务?
重新审视推理 SFT 中的泛化问题:基于优化、数据与模型能力的条件分析
SkillClaw:通过 Agentic Evolver 实现技能的集体进化
MDPBench:面向真实场景的多语言文档解析基准测试
TC-AE:解锁深度压缩 Autoencoders 的 Token 容量
INSPATIO-WORLD:一种基于时空 Autoregressive Modeling 的实时 4D 世界 Simulator
FlowInOne: 将多模态生成统一为“图像输入、图像输出”的 Flow Matching
MARS:赋能 Autoregressive Models 的 Multi-Token Generation
以笔触而非像素进行思考:通过交织推理实现的流程驱动型图像生成
RAGEN-2:Agentic RL 中的推理崩溃
Vanast: 通过合成三元组监督实现基于人体图像动画的虚拟试穿
ThinkTwice:面向推理与自我修正的 Large Language Models 联合优化研究
ACES:谁在测试测试集?面向代码生成任务的留一法(Leave-One-Out)AUC 一致性研究
从 Agent Trajectories 中学习检索
Claw-Eval:迈向自主 Agent 的可信 Evaluation
Video-MME-v2:迈向全面视频理解 Benchmark 的下一阶段
GrandCode: 通过 Agentic Reinforcement Learning 实现竞技编程中的 Grandmaster 水平
LIBERO-Para:针对 VLA 模型改写鲁棒性的诊断性 benchmark 与评估指标