Command Palette
Search for a command to run...
FORGE:面向制造场景的细粒度 Multimodal Evaluation
FORGE:面向制造场景的细粒度 Multimodal Evaluation
摘要
制造业正日益采用 Multimodal Large Language Models (MLLMs),旨在实现从简单的感知向自主执行的转型。然而,当前的评估体系未能反映真实制造环境的严苛需求。由于现有数据集存在数据稀缺以及缺乏细粒度领域语义的问题,这一进程受到了阻碍。为了弥补这一差距,我们推出了 FORGE。首先,我们构建了一个高质量的 multimodal 数据集,该数据集结合了真实的 2D 图像与 3D point clouds,并标注了细粒度的领域语义(例如精确的型号)。随后,我们在工件校验、结构表面检测和装配校验这三项制造任务中,对 18 个最先进的 MLLMs 进行了评估,结果显示其性能存在显著差异。与传统认知相反,瓶颈分析表明,visual grounding 并非主要的限制因素;相反,领域特定知识的匮乏才是关键瓶颈,这为未来的研究指明了清晰的方向。除了评估工作外,我们还展示了我们的结构化标注可以作为一种可操作的 training 资源:在我们的数据上对一个 3B 参数的紧凑型模型进行 supervised fine-tuning,使其在留存的制造场景中的准确率实现了高达 90.8% 的相对提升。这为实现领域适配型制造 MLLMs 的实用路径提供了初步证据。代码和数据集可通过以下链接获取:https://ai4manufacturing.github.io/forge-web。
一句话总结
为了解决当前制造业评估中的局限性,作者推出了 FORGE,这是一个细粒度的多模态评估框架和数据集。该框架将 2D 图像和 3D 点云与特定领域的语义相结合,揭示了在涵盖工件验证、结构表面检测和装配验证任务的 18 个最先进 MLLM 的评估中,主要的瓶颈在于领域知识不足,而非视觉 grounding 能力。
核心贡献
- 本文引入了 FORGE,这是一个高质量的多模态数据集,它将真实的 2D 图像与 3D 点云相结合,并纳入了诸如精确型号等细粒度的领域语义。
- 这项工作对 18 个最先进的多模态大语言模型 (MLLMs) 在三个特定制造任务(包括工件验证、结构表面检测和装配验证)中进行了全面评估。
- 研究表明,使用新数据集的结构化标注对紧凑的 3B 参数模型进行监督微调,可以达到高达 90% 的准确率。
引言
制造业正通过使用多模态大语言模型 (MLLMs) 从简单的感知向自主决策转型。虽然传统的计算机视觉模型擅长异常检测等局部任务,但它们缺乏高层规划和执行所需的推理能力。当前的研究受到显著的数据稀缺差距和细粒度领域语义缺失的阻碍,因为大多数现有的基准测试未能考虑到现实工厂环境中所需的严格精度和特定的型号级细节。
作者利用这些挑战引入了 FORGE,这是一个专门为制造业设计的全面多模态基准测试。他们构建了一个高质量的数据集,集成了对齐的 2D 图像和带有细粒度语义(如精确型号)标注的 3D 点云。通过对 18 个最先进的 MLLMs 在三个核心任务(工件验证、结构表面检测和装配验证)中的广泛评估,作者发现领域知识不足而非视觉 grounding 是当前模型的主要瓶颈。最后,他们证明了其结构化标注可以作为有效的训练资源,表明监督微调可以显著提高模型在未知制造场景中的准确率。
数据集
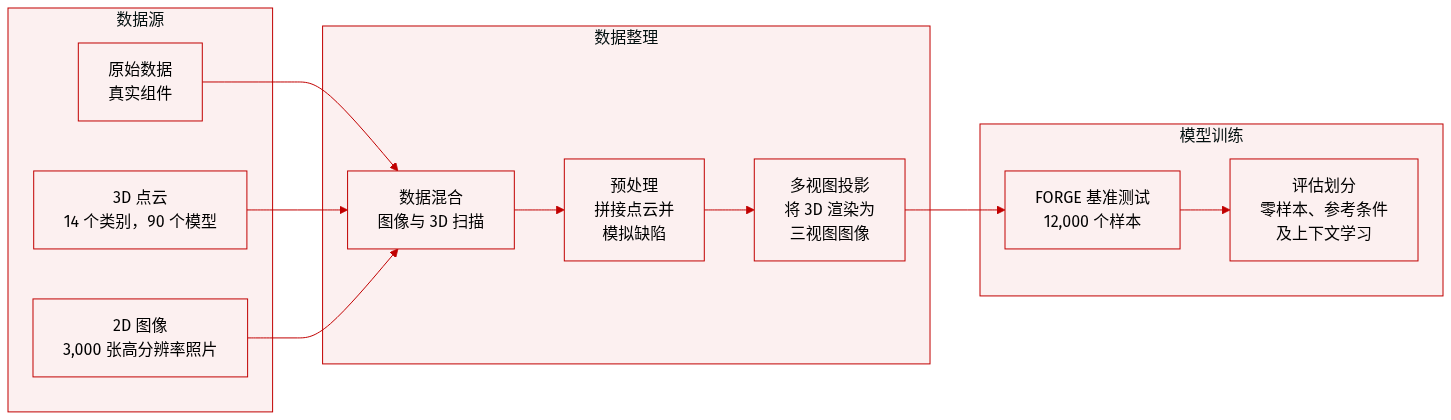
作者开发了 FORGE,这是一个包含约 12,000 个样本的全面基准测试,旨在评估多模态大语言模型 (MLLMs) 在制造语境下的推理和认知能力。
-
数据集组成与来源
- 数据集由通过精密转台和定制夹具收集的真实制造组件构建而成。
- 3D 点云子集: 包含高保真几何数据,涵盖 90 个不同型号的 14 类工件。
- 图像子集: 包含约 3,000 张高分辨率图像(使用 5000 万像素传感器拍摄),涵盖四种制造场景,包括正常样本和异常样本。
-
特定任务细节
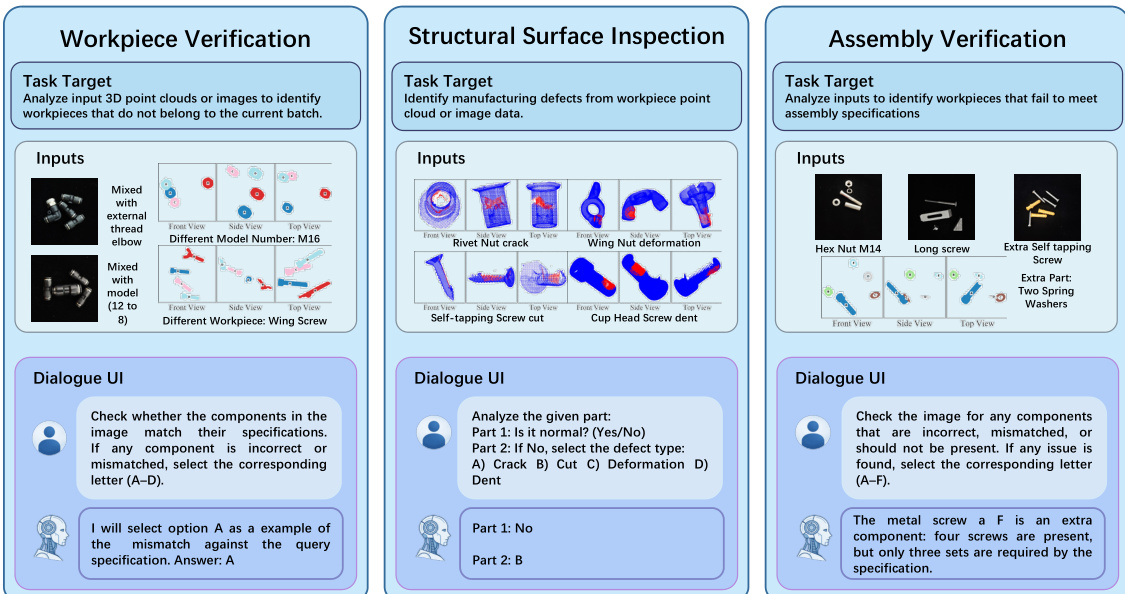
- 工件验证 (WORKVERI): 通过识别错误的工件或型号不匹配来进行物料分类。它包括气动连接器(图像)、杯头螺钉和螺母(点云)等场景。
- 结构表面检测 (SURFINSPI): 针对使用点云数据的 14 种工件类型进行缺陷检测和分类(例如:裂纹、变形、凹痕和切割)。
- 装配验证 (ASSYVERI): 评估对装配规则和兼容性的理解。它涵盖四个场景,包括金属/塑料膨胀螺钉和 CNC 夹具(图像),以及螺钉/垫圈/螺母的兼容性(点云)。
-
数据处理与合成
- 2D 图像处理: 通过自动轮廓和坐标提取,随后进行人工精细化,建立 ground-truth 标签。
- 3D 点云合成: 对于 WORKVERI 和 ASSYVERI,作者将 4 到 5 个具有随机方向的单个点云缝合在一起以创建批量样本。对于 SURFINSPI,使用基于形态学的算法和非刚性变形来模拟制造缺陷,缺陷密度限制在 5% 到 15% 之间。
- 数据增强: 对 SURFINSPI 子集进行了每个样本 20 次随机旋转的增强。
-
模态桥接与评估策略
- 多视图投影: 为了弥补 3D 数据与缺乏原生 3D 编码器的 MLLMs 之间的差距,作者将所有 3D 点云渲染为三视图 (3V) 正交投影(前视图、侧视图和顶视图)。
- 评估设置: 该基准测试利用三种不同的设置:Zero-Shot、Reference-Conditioned(提供三个正确的正常案例)以及 In-Context Demonstration(提供类似的图像、查询和正确答案)。
- 错误分类: 场景被分为粗粒度错误(不同的工件/缺失组件)和细粒度错误(不同的型号)。
方法
作者利用一个多模态框架,通过集成多样化数据模态和特定任务架构的结构化流水线来解决工业验证任务。整个系统始于多模态数据基础,该基础处理真实的 2D 图像和 3D 点云以生成细粒度的语义标注。这些标注作为 FORGE 基准测试中后续任务的基础,该基准测试分为三个核心部分:工件验证、结构表面检测和装配验证。每个任务旨在分析制造组件的特定方面,从识别不合格工件到检测表面缺陷以及验证装配规范。
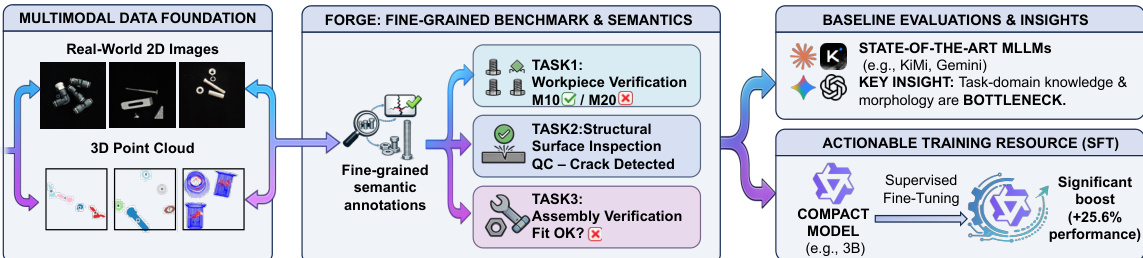
该框架基于统一的标注过程,确保了跨模态的语义一致性。这一基础使得能够为各种工业场景生成高质量的细粒度标签。生成的数据随后用于在多个任务中训练和评估模型。例如,工件验证侧重于识别偏离预期规格的组件,例如型号错误或零件不匹配的组件。结构表面检测通过分析 3D 点云或图像中的表面特征,针对制造缺陷(包括裂纹、切割、变形和凹痕)进行检测。装配验证评估所有必需组件是否齐全且规格正确,识别装配中缺失的零件或多余的元素。
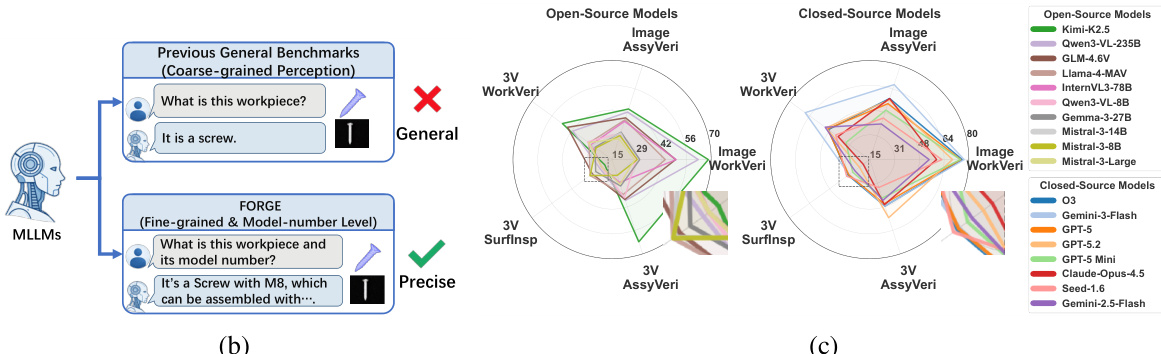
模型架构旨在处理通用感知任务和细粒度的型号级验证。虽然通用模型往往无法捕捉工业应用中细微的要求(例如区分标准螺钉与特定型号),但 FORGE 框架采用了面向精度的方案。这通过从“这是什么工件?”这类粗粒度查询转向“这是什么工件及其型号?”这类更精确的询问得到了体现,后者更适合详细的工业检测。系统通过结合监督微调和紧凑模型优化进一步增强了能力,实现了显著的性能提升。
为了评估框架的有效性,作者使用最先进的多模态大语言模型 (MLLMs) 进行基准评估,突出了对当前方法瓶颈的关键见解。这些评估表明,特定领域的知识和几何理解对于准确验证至关重要。该框架还纳入了可操作的训练资源,例如紧凑模型,这些模型能以极低的计算开销实现大幅性能提升。系统的模块化设计允许其在不同的工业应用中进行扩展和适应,确保了在现实部署中的鲁棒性。
实验
评估针对三个制造任务测试了 18 个多模态大语言模型,以确定它们执行装配验证、表面缺陷分类和组件识别的能力。结果表明,虽然模型展示了强大的语义理解和视觉 grounding 能力,但它们在微观表面形态和细粒度领域特定推理方面表现挣扎。瓶颈分析显示,复杂制造场景中的失败主要源于缺乏深厚的领域知识和关联装配逻辑,而非视觉感知或定位能力较差。
表格比较了几个制造任务的基准测试,突出了数据模态、来源、场景和粒度的差异。FORGE 的特点在于同时使用图像和点云数据、真实场景以及细粒度的型号和工件细节,在列出的基准测试中样本量最大。FORGE 包含图像和点云两种数据模态,而其他基准测试仅使用一种或不使用。FORGE 是唯一使用真实数据评估工件和型号粒度的基准测试。FORGE 拥有最多的样本数量,表明其是一个更全面的评估数据集。

表格展示了视觉 grounding 任务的结果,比较了四种模型在单图和跨图设置下的表现。评估衡量了在空间坐标和零件标签之间进行映射的能力,模型在单图任务中达到了较高的准确率,但在跨图匹配中的表现较低。闭源模型在单图和跨图设置下的准确率均高于开源模型。所有模型在单图任务上的表现都优于跨图任务。对于开源模型,单图和跨图任务之间的性能差距更为明显。
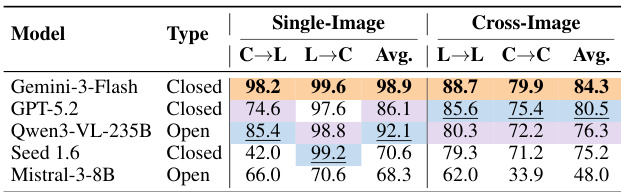
作者在三个制造任务上评估了多个 MLLMs,分析了在不同设置和模态下的性能。结果显示,当前模型在细粒度领域知识和空间推理方面存在困难,特别是在需要详细视觉分析和逻辑推理的任务中。MLLMs 在宏观零件识别上的表现优于微观表面分析。基于参考的方法并不能一致地提高性能,表明缺乏深层的领域理解。三视图评估显示,随着示例的增加,性能会出现下降,这表明模型存在空间混淆。
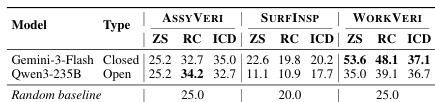
实验在三个制造任务上评估了多模态模型,评估了不同场景和错误类型的性能。结果显示,模型在工件级任务上的表现优于型号级任务,且视觉 grounding 并不是主要瓶颈,这表明领域知识的局限性更为关键。模型在工件级任务上的表现优于型号级任务。视觉 grounding 不是主要瓶颈,表明领域知识的局限性更为显著。在三视图模态下,性能随着示例的增加而下降,表明存在空间混淆。

实验评估了多个 MLLMs 在制造任务中的表现,显示闭源模型通常优于开源模型。性能在不同任务和评估设置之间存在显著差异,在 zero-shot、reference-conditioned 和 in-context demonstration 方法之间存在显著区别。结果强调,领域知识和推理能力是关键瓶颈,而视觉 grounding 并不是主要限制。在大多数任务和设置中,闭源模型比开源模型实现了更高的准确率。In-context demonstration 方法通常比 zero-shot 和 reference-conditioned 设置能提高性能。性能在不同任务之间差异很大,某些任务的准确率明显低于其他任务,表明存在特定任务的挑战。
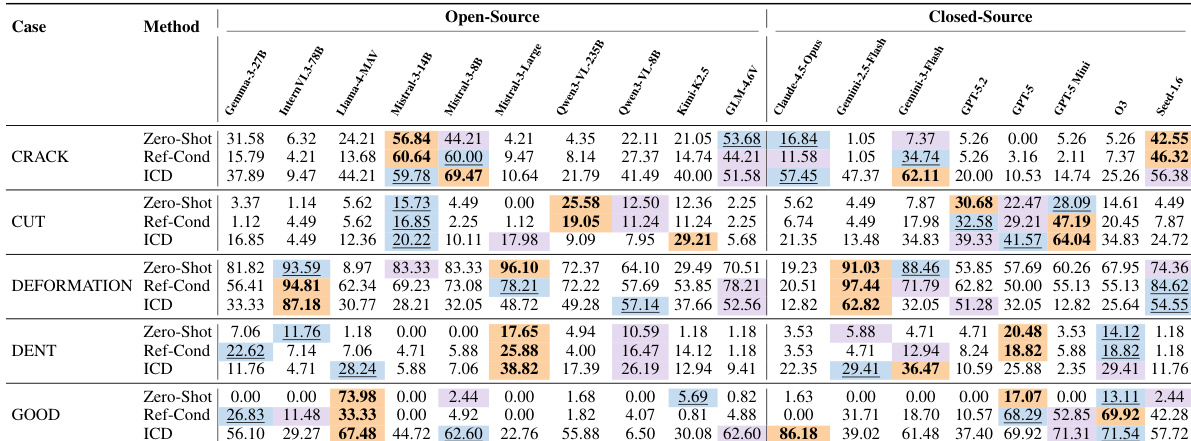
该评估比较了各种制造基准测试以及多个多模态大语言模型在涉及视觉 grounding、零件识别和空间推理的任务中的表现。虽然闭源模型通常优于开源模型,但所有模型在细粒度领域知识和复杂的空间推理方面都表现挣扎,特别是在任务需要微观分析或多视图时。研究结果表明,这些模型的主要局限在于领域特定理解和逻辑推理,而非基础的视觉 grounding 能力。