Command Palette
Search for a command to run...
以笔触而非像素进行思考:通过交织推理实现的流程驱动型图像生成
以笔触而非像素进行思考:通过交织推理实现的流程驱动型图像生成
摘要
人类绘画是一个循序渐进的过程:首先规划全局布局,接着绘制粗略草图,随后进行检查并细化细节;最重要的是,每一步都基于不断演进的视觉状态。然而,在图文交织数据集上训练的统一多模态模型,是否也能想象出这一系列中间状态的链条?在本文中,我们提出了过程驱动图像生成(process-driven image generation),这是一种将合成任务分解为“思维与动作交织的推理轨迹”的多步范式。我们的方法并非通过单步生成图像,而是在多个迭代周期中展开,每个周期包含四个阶段:文本规划(textual planning)、视觉草图绘制(visual drafting)、文本反思(textual reflection)以及视觉精细化(visual refinement)。其中,文本推理明确地规定了视觉状态应如何演进,而生成的视觉中间态又反过来约束并锚定(ground)下一轮的文本推理。过程驱动生成面临的核心挑战源于中间状态的模糊性:模型应如何评估每一张部分完成的图像?我们通过密集的逐步监督(step-wise supervision)来解决这一问题,并维持两个互补的约束:对于视觉中间态,我们强制要求空间与语义的一致性;对于文本中间态,我们在保留先验视觉知识的同时,使模型能够识别并纠正违背 prompt 的元素。这使得生成过程变得显式、可解释且可直接监督。为了验证所提方法的有效性,我们在多种 text-to-image 生成 benchmark 上进行了实验。
一句话总结
加州大学圣迭戈分校等机构的研究人员提出了一种过程驱动的图像生成范式,该范式通过文本规划、视觉草图、文本反思和视觉细化这四个阶段的循环,将合成过程分解为思维与行动交织的推理轨迹,并利用对中间状态的密集、逐步监督,以确保在各种文本到图像生成基准测试中的空间和语义一致性。
核心贡献
- 本文引入了过程驱动的图像生成,这是一种多步范式,将合成过程分解为思维与行动交织的推理轨迹。该方法通过包含文本规划、视觉草图、文本反思和视觉细化的四个迭代阶段展开。
- 该方法实现了一个框架,其中文本推理显式地调节视觉状态的演变,而生成的视觉中间体则为随后的文本推理提供 grounding。这在语义推理和生成过程之间创建了互信息流。
- 该工作采用了一种密集的、逐步的监督策略,通过对视觉输出强制执行空间和语义一致性,并为文本推理保留先验知识,从而管理中间状态的歧义性。这种方法允许模型识别并纠正违反 prompt 的元素,其有效性通过在各种文本到图像生成基准测试上的实验得到了验证。
引言
统一的多模态模型旨在将视觉理解和生成集成在单个框架内,以产生复杂的、逻辑结构化的内容。虽然现有方法要么使用离散的视觉 token,要么使用解耦的 LLM 和扩散模块,但它们往往难以将语义推理与生成过程紧密耦合。此外,当前的多轮推理方法将图像视为静态终点而非演变状态,这阻碍了模型在步骤间保持连贯性。作者利用了一种过程驱动的图像生成范式,将合成分解为文本规划、视觉草图、文本反思和视觉细化的交织轨迹。这种方法使模型能够使用文本推理来引导视觉演变,同时利用中间视觉状态来 grounding 并约束后续推理。
数据集
作者从零开始构建了一个基于过程的交织推理数据集,使模型能够在图像生成过程中进行规划、评估和细化视觉状态。该数据集由三个专门的子集组成:
- 多轮生成子集 (Multi-Turn Generation Subset): 包含约 30,000 到 32,000 个样本,该子集专注于将模型从单轮生成过渡到多阶段生成。作者使用基于场景图的采样机制来创建增量的、步骤级的 prompt,以确保空间和语义的连贯性。Ground truth 图像使用 Flux-Kontext 合成并通过 GPT 进行过滤。为了在简单的累加更新之外增加多样性,一部分指令使用 GPT 进行重写,以包含属性修改、交换和删除。每个样本平均包含 3 到 5 个中间视觉状态。
- 指令-中间体冲突推理子集 (Instruction-Intermediate Conflict Reasoning Subset): 该子集包含超过 15,000 个样本,旨在提高文本推理能力。作者采用了一种自采样策略,即在 Multi-Turn 子集上微调的模型生成中间推理轨迹。GPT 作为评判者来评估其与原始 prompt 的一致性。对于冲突实例,数据集包含了文本分析和纠正指令,以教会模型区分不完整但正确的 token 与实际的 prompt 不一致。
- 图像-指令对齐推理子集 (Image-Instruction Alignment Reasoning Subset): 由 15,000 个样本组成,该子集专注于视觉失配问题。它是 Gen-Ref 数据集的扩展,组织为 5,000 个正样本(图像与指令对齐)和 10,000 个负样本(图像与指令不对齐)。GPT 被用于为正向对齐生成解释,并为负向案例生成错误分析及配套的细化指令。
作者使用整个集合对 BAGEL-7B 模型进行端到端监督微调。训练过程扩展了原始目标,以支持在单个自回归序列中实现文本推理与视觉生成之间的无缝切换。
方法
作者利用统一的多模态模型,通过顺序的、交织的文本-视觉推理过程进行图像生成。如下方图表所示,整体框架将生成分解为一个循环往复的四阶段周期:规划 (Plan)、草图 (Sketch)、检查 (Inspect) 和细化 (Refine)。这个循环实现了对文本和视觉演变的细粒度控制,模型生成交织的 text token 和 vision token 序列,并逐步收敛到最终图像。
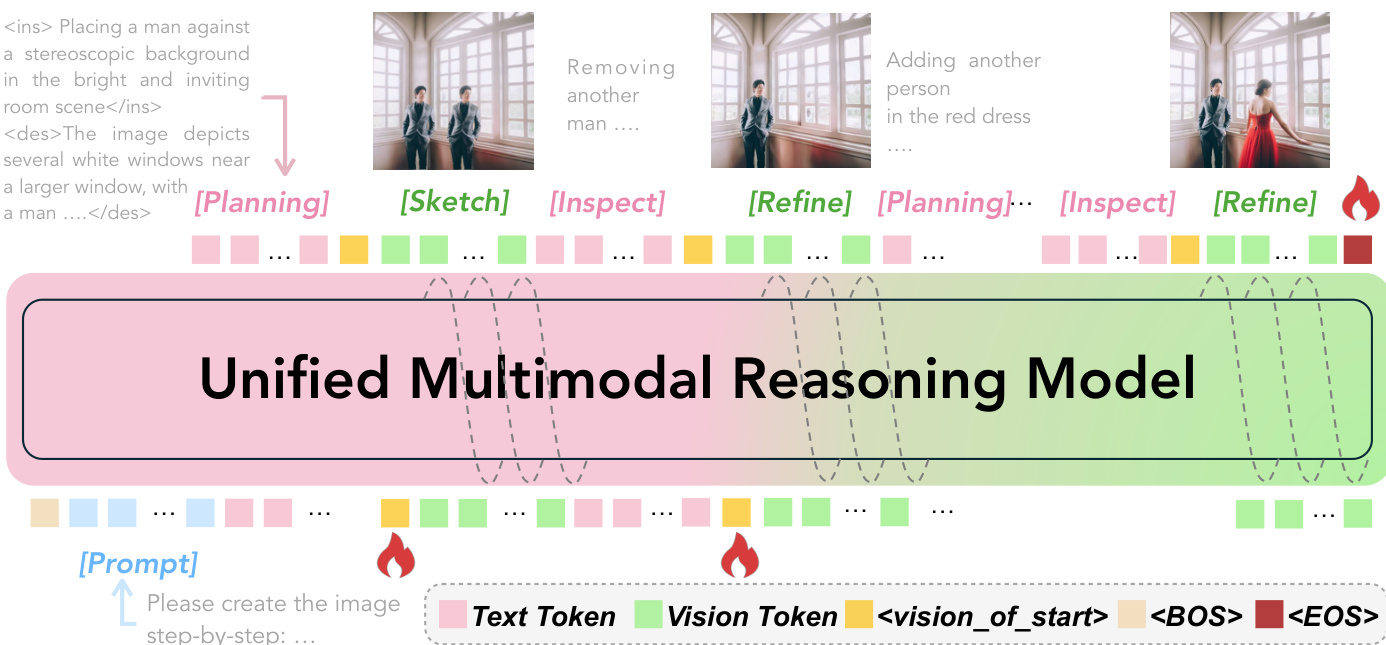
如上图所示,模型在一个在文本 token 和视觉 token 之间交替的统一序列上运行。该过程从输入 prompt 开始,模型生成一个由交替的文本推理步骤 s(i) 和中间视觉状态 v(i) 组成的轨迹。每个文本中间体 s(i) 以两种形式出现:在规划阶段,它包括封装在 <ins>...</ins> 中的特定步骤绘画指令和封装在 <des>...</des> 中的全局场景描述。在检查阶段,如果检测到失配,模型会发出封装在 <refine>...</refine> 中的细化信号。视觉状态 v(i) 也采取两种形式:规划阶段产生一个代表预期更新的粗略草图,而细化阶段则将此草图润色为更准确的视觉表示。所有视觉输出都包裹在 <!-- 和 --> 之间,以显式标记模态转换。
模型的架构构建在统一的多模态骨干网络(如 BAGEL)之上,并针对过程驱动的交织生成任务进行了微调。在训练期间,模型通过仅应用于文本段 s(i) 的交叉熵 (CE) 损失进行自回归优化,以生成 text token。为了实现交织序列的无缝生成,在 <vision_start> 和 <vision_end> token 上添加了一个损失项,以促进文本和视觉模态之间的转换。用于 next-token 预测的 CE 损失正式定义为:
在视觉方面,模型采用 Rectified Flow 范式来生成图像。这涉及在时间步 t∈[0,1] 时,在潜在表示 z0(i) 和目标 z1(i) 之间进行插值:
zt(i)=t⋅z0(i)+(1−t)⋅z1(i)图像生成损失定义为预测流与初始及目标潜在表示之间的实际差异的均方误差:
LMSEimage=E[Pθ(zt(i)∣y<t,T)−(z0(i)−z1(i))2]总训练目标是 CE 损失和 MSE 损失的加权组合,其中超参数 λCE 平衡这两个部分:
Ltotal=λCE⋅LCEtext+LMSEimage在推理过程中,给定文本 prompt T,模型自回归地生成交织的推理轨迹。文本和视觉中间体在一个统一序列中产生,模态转换由特殊 token 控制。一旦发射出由序列结束 token 标记的最终完成图像 I,过程即告终止。该框架允许模型通过一系列可控的、局部化的更新逐步组装最终图像,确保与输入 prompt 的连贯性和对齐。
实验
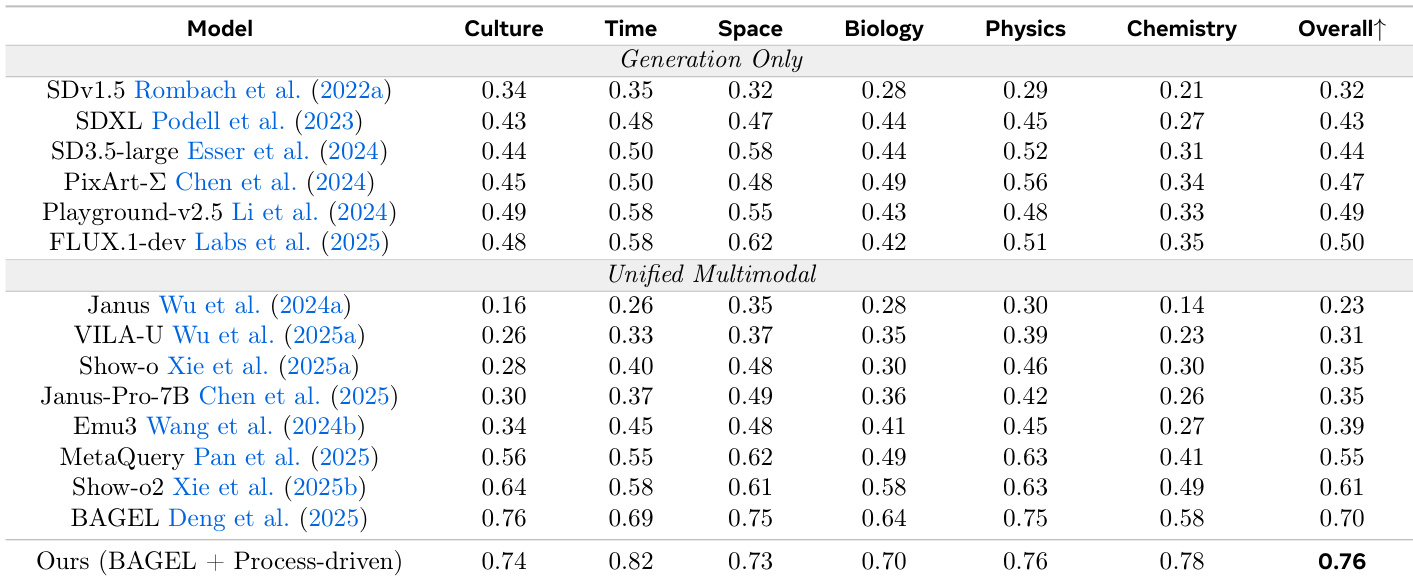
该研究使用 GenEval 和 WISE 基准测试,将过程驱动的交织推理范式与单次生成模型以及现有的基于过程的基准模型进行了对比评估。实验验证了规划、草图、检查和细化的循环能够实现更优的组合对齐和世界知识推理。研究结果表明,通过内化自采样评论和多样化的编辑指令,模型能够有效地检测并纠正视觉-语义不一致,且其数据和推理效率显著高于以往的方法。
作者引入了一种过程驱动的图像生成方法,在文本和视觉之间进行交织推理。结果显示,通过自我批判式细化和语义监督,模型在组合推理任务(特别是在基于空间和属性的评估中)方面取得了改进。该方法通过在生成过程中细化中间视觉状态,提升了空间和属性推理能力。自采样评论由于与模型的内部错误模式对齐,比符号化纠正带来了更好的性能。结合语义和视觉一致性检查增强了不同任务中的组合准确性。
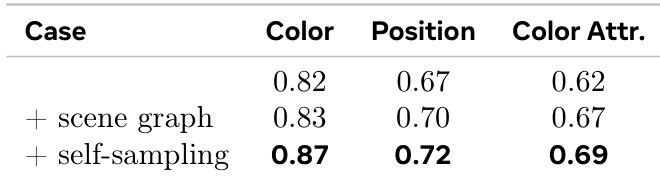
作者引入了一种过程驱动的图像生成方法,将推理与视觉合成交织,从而实现了更好的空间和属性对齐。结果显示,与现有的统一多模态模型相比,该方法在多个领域实现了更高的准确率,特别是在需要世界知识和细粒度推理的复杂任务中。该方法通过实现迭代的视觉和文本细化,提升了在组合和属性敏感任务上的表现。它在比以往统一模型使用显著更少的训练数据和推理成本的同时,实现了更高的准确率。自采样评论和多样化的编辑指令是改进中间推理和错误纠正的关键。
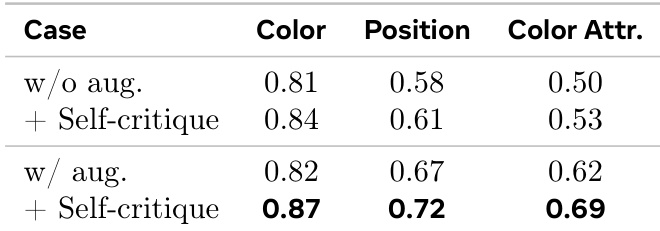
表格展示了自批判增强对模型在不同评估指标上性能的影响。结果表明,添加自批判显著提高了性能,特别是在位置和颜色属性任务中,当同时应用增强和自批判时,观察到的增益最为显著。自批判增强在所有指标上都带来了显著的性能提升。在位置和颜色属性任务中观察到的增益最大。将增强与自批判结合在所有评估类别中均获得了最高性能。
作者提出了一种过程驱动的图像生成方法,将文本规划和视觉草图与检查及细化步骤交织在一起。结果显示,与现有的仅生成模型和统一多模态模型相比,该方法提高了组合准确性和视觉 grounding,特别是在需要精确空间和属性推理的任务中。与仅生成模型和统一多模态模型相比,该方法在组合任务上实现了更高的准确率。它通过交织的文本和视觉推理,展示了在空间和属性推理方面改进的性能。该方法在需要细粒度物体对齐和世界知识推理的基准测试上表现出了优异的结果。
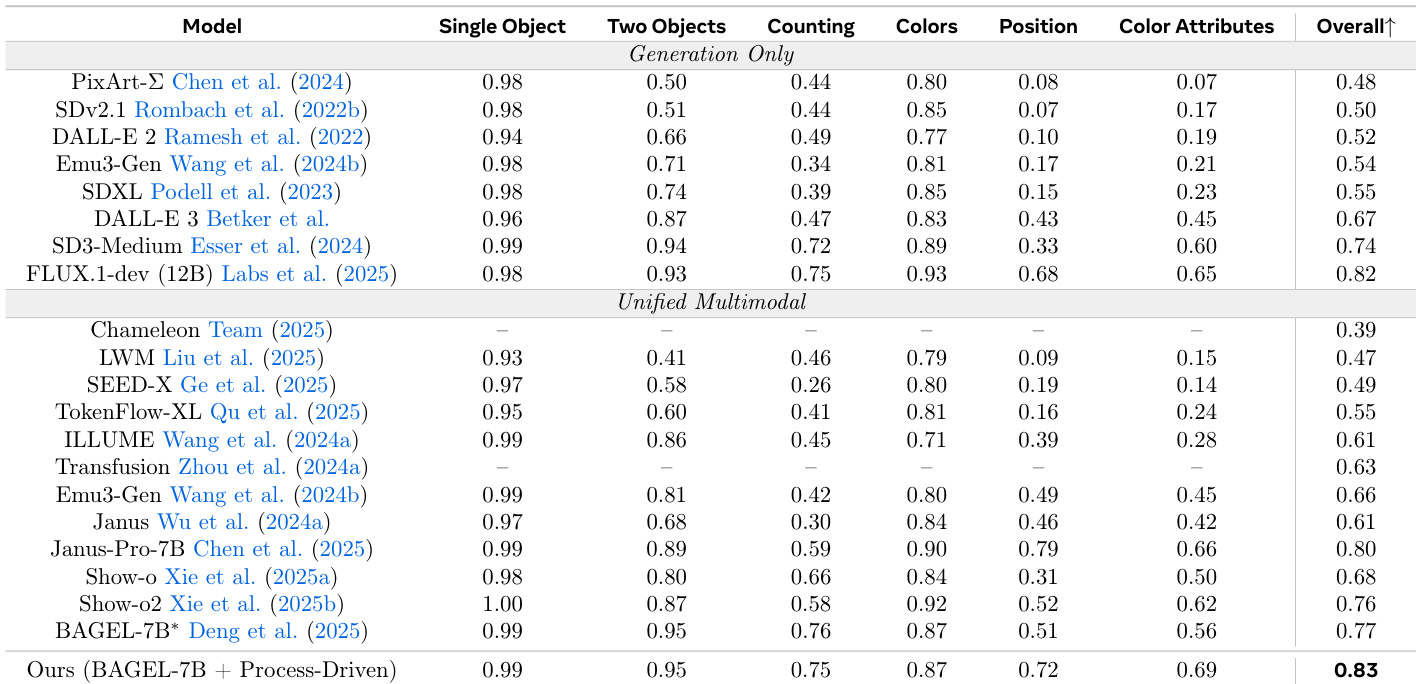
作者评估了互补监督机制对图像生成中组合推理的影响。结果表明,与单独使用任一机制相比,结合指令-中间体冲突和图像-指令对齐监督可以提高多种属性下的性能,特别是在计数和颜色任务中。结合指令-中间体冲突和图像-指令对齐监督提升了组合推理能力。组合方法在计数和颜色任务中获得了最高性能。每种监督机制解决了不同的失败模式,从而带来了协同改进。

作者评估了一种过程驱动的图像生成方法,该方法通过迭代细化和自批判将文本推理与视觉合成交织。实验表明,与现有的统一多模态模型相比,该方法显著增强了组合推理,特别是在空间对齐、颜色属性和计数任务中。结果表明,将自采样评论与互补的语义和视觉监督机制相结合,可以有效地解决不同的错误模式,从而提高整体的 grounding 和准确性。