Command Palette
Search for a command to run...
MARS:赋能 Autoregressive Models 的 Multi-Token Generation
MARS:赋能 Autoregressive Models 的 Multi-Token Generation
Ziqi Jin Lei Wang Ziwei Luo Aixin Sun
摘要
自回归(Autoregressive, AR)语言模型每次仅生成一个 token,即便在给定前文语境的情况下,连续 token 具有高度可预测性。我们提出了 MARS(Mask AutoRegreSsion),这是一种轻量级的 fine-tuning 方法,旨在训练经过 instruction-tuned 的 AR 模型在单次 forward pass 中预测多个 token。MARS 不需要任何架构修改,不增加额外参数,并能生成一个与原 AR 模型调用方式完全一致且性能无损的单一模型。与需要维护一个独立草案模型(draft model)与目标模型并行的 speculative decoding,或是在其上附加额外预测头的 Medusa 等 multi-head 方法不同,MARS 仅需在现有的 instruction 数据上进行持续训练。在每次 forward pass 生成一个 token 的情况下,MARS 在六个标准 benchmark 上的表现达到或超过了 AR 基准模型。当被允许每步接受多个 token 时,MARS 在保持基准水平准确度的同时,实现了 1.5-1.7 倍的吞吐量提升。我们进一步开发了一种用于 batch inference 的 block-level KV caching 策略;在 Qwen2.5-7B 模型上,相比使用 KV cache 的 AR 模型,该策略实现了高达 1.71 倍的 wall-clock speedup(实际运行时间加速)。最后,MARS 支持通过置信度阈值(confidence thresholding)进行实时速度调节:在高请求负载下,推理服务系统可以即时提高吞吐量,而无需更换模型或重启,为模型部署提供了一个实用的延迟-质量(latency-quality)调节旋钮。
一句话总结
通过利用一种无需架构修改或额外参数的轻量级微调方法,MARS 使经过指令微调的 autoregressive 模型能够通过持续训练实现 multi-token 生成,在实现高达 1.7 倍吞吐量的同时,还能通过置信度阈值进行实时速度调节。
核心贡献
- 本文引入了 MARS (Mask AutoRegreSsion),这是一种轻量级微调方法,使经过指令微调的 autoregressive 模型能够在不增加额外参数或修改架构的情况下,在单次前向传播中预测多个 tokens。
- 该方法利用 [MASK] tokens 作为显式的占位符,训练模型从不完整的上下文中进行预测,在保持六个标准基准测试准确率的同时,实现了 1.5 到 1.7 倍的吞吐量。
- 该工作开发了一种块级 KV caching 策略和基于置信度的阈值机制,两者结合使得在部署期间能够实现高达 1.71 倍的实际运行速度提升,并进行实时的、即时的吞吐量调节。
引言
Autoregressive 语言模型一次生成一个 token,这导致即使后续 tokens 非常容易预测,计算成本也是均匀的。虽然诸如投机采样 (speculative decoding) 和多头架构等方法试图加速这一过程,但它们通常通过需要单独的草稿模型或额外的架构参数和头部而引入了显著的开销。作者利用一种名为 MARS (Mask AutoRegreSsion) 的轻量级微调方法,在不进行任何架构修改或增加额外参数的情况下实现了 multi-token 生成。通过弥合标准 autoregressive 模型与块掩码预测 (block-masked prediction) 之间的设计差距,MARS 允许单个模型作为原始模型的严格超集运行,提供了一个实用的延迟-质量调节旋钮,在部署期间最高可实现 1.71 倍的吞吐量加速。
方法
作者利用双流训练框架,将 multi-token 预测集成到现有的 autoregressive (AR) 模型中,同时保留其核心 AR 功能。该方法命名为 MARS,从预训练的 AR 有监督微调 (SFT) checkpoint 开始,确保模型已经学习了目标数据分布。这使得训练过程可以专注于学习掩码预测范式,而不会破坏模型的根本 AR 能力。
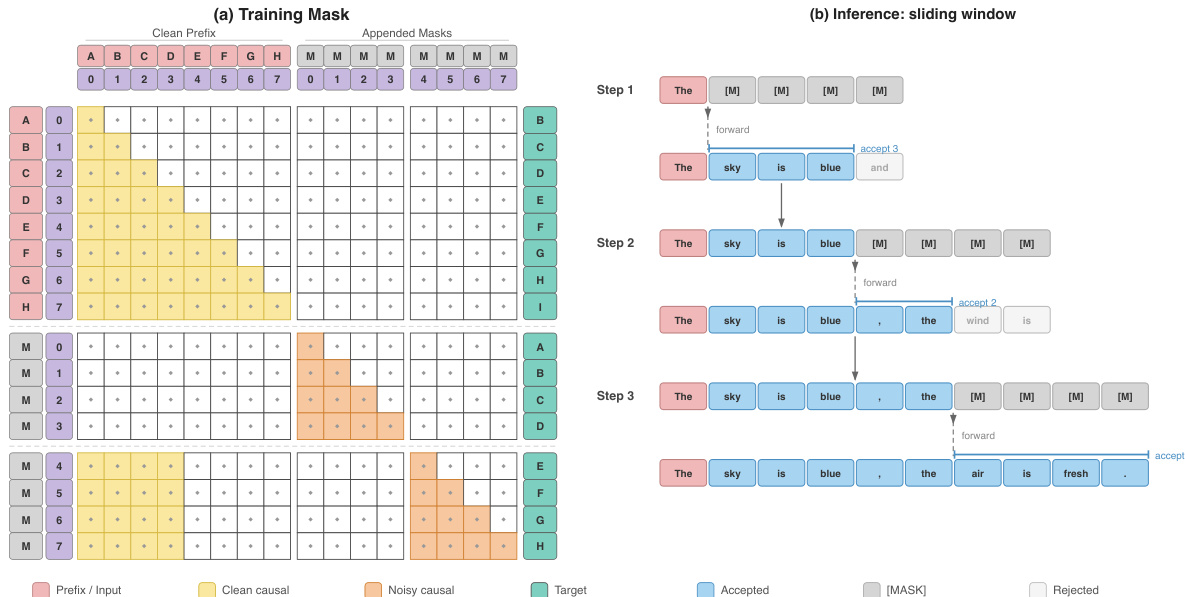
训练过程涉及通过模型并行运行序列的两个副本:一个干净流 (clean stream) 和一个噪声流 (noisy stream)。干净流由原始、未修改的 tokens 组成,用于通过标准的 AR next-token 预测来训练模型。噪声流通过将序列划分为大小为 B 的块,并将每个块内的所有 tokens 替换为 [MASK] 占位符来构建。模型处理长度为 2L 的拼接输入 z=[x;x~],其中前 L 个位置是干净流,后 L 个位置是噪声流。结构化注意力掩码 (structured attention mask) 确保模型的注意力模式保持严格的因果性,从而强制每个位置具有正确的可见性。这种设计本质上弥合了先前块掩码方法中识别出的注意力模式和 logits 对齐方面的差距。注意力掩码 M 的定义如下:干净因果情况为干净流提供标准的因果自注意力;噪声块内因果情况允许每个噪声位置在其自身的块内进行因果注意力;跨流情况允许每个噪声块看到来自所有先前块的干净 tokens,从而为预测提供必要的上下文。噪声流上的训练损失计算为掩码位置上的交叉熵。
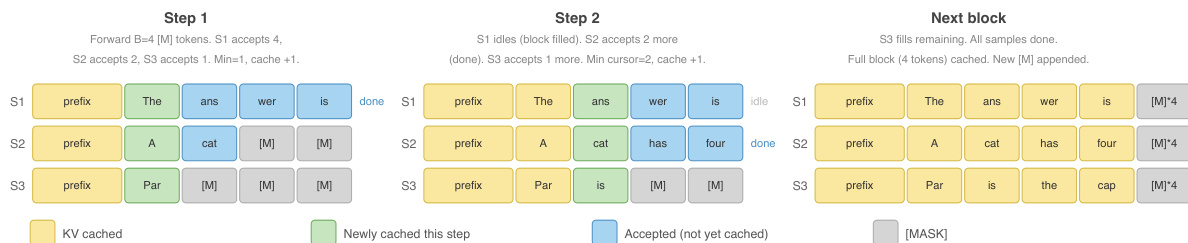
为了保持模型的 AR 能力,训练损失通过从干净流 logits 计算的标准 AR next-token 预测损失进行了增强。这种组合损失 L=Lmask+LAR 确保模型持续练习标准的 AR 预测,从而抵消随着块大小增加而发生的 AR 信号侵蚀。该机制将 AR 信号与块大小解耦,即使在较大的块下也能保持高比例的 AR 等效信号。在推理期间,模型以从左到右的滑动窗口方式运行,弥合了与生成顺序相关的最后差距。在每一步中,将 B 个 [MASK] tokens 追加到当前前缀,模型运行单次前向传播以获取所有 B 个位置的 logits。当预测 token 的最大概率满足置信度阈值 τ 时,token 会从左到右连续被接受。被接受的 tokens 被添加到前缀中,并追加新的 [MASK] tokens 以维持窗口大小。这一过程确保了当置信度较低时,模型能平滑地退化到标准的 AR 解码,同时在置信度较高时实现高吞吐量的 multi-token 生成。置信度阈值 τ 可以在服务期间动态调整,以控制吞吐量与质量之间的权衡。
实验
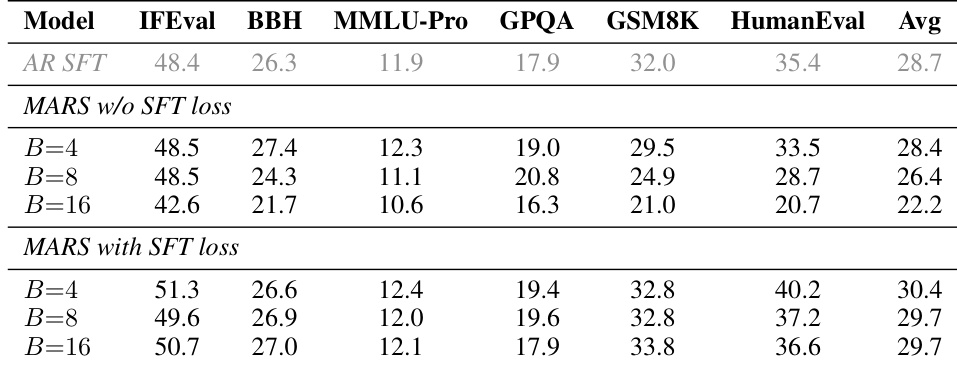
实验在不同的模型规模下评估了 MARS,以验证其在实现高效 multi-token 生成的同时能够保留原始 autoregressive 质量。结果表明,结合 SFT 损失可以防止在使用较大块大小时通常会出现的信号衰减,从而通过置信度阈值实现平滑且可控的速度-质量权衡。此外,块级 KV cache 的实现确保了这些算法改进在批量推理期间能够转化为显著的实际运行速度提升。
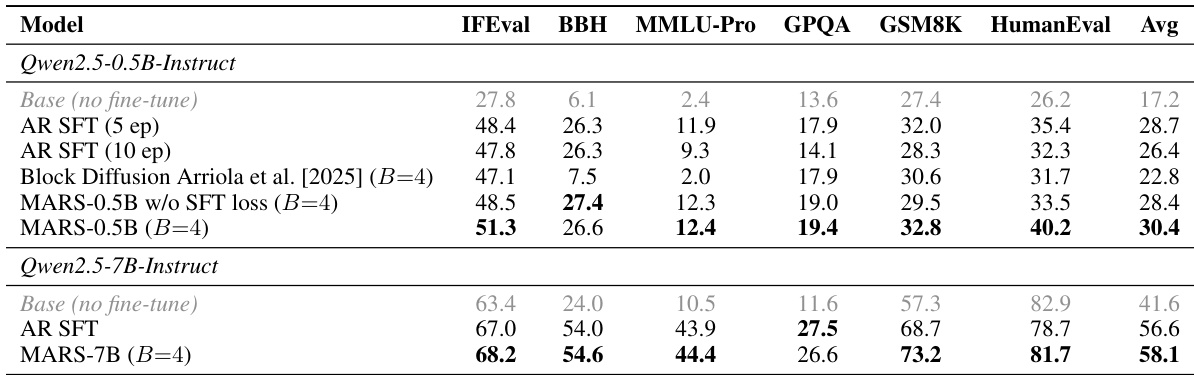
作者在单 token 生成模式下评估了 MARS,以评估其保持原始 autoregressive (AR) 模型质量的能力。结果显示,与 AR SFT 基准相比,MARS 在多个基准测试中保持或提高了性能,在推理和编程任务中观察到了显著的收益。包含 SFT 损失至关重要,因为缺失该损失会导致在较大块大小时性能大幅下降。在单 token 生成模式下,MARS 在推理和编程任务上保持或提高了相对于 AR SFT 的性能。如果不使用 SFT 损失,较大的块大小会导致各基准测试的质量显著下降。SFT 损失稳定了不同块大小下的性能,确保了无论块大小如何都能保持一致的质量。
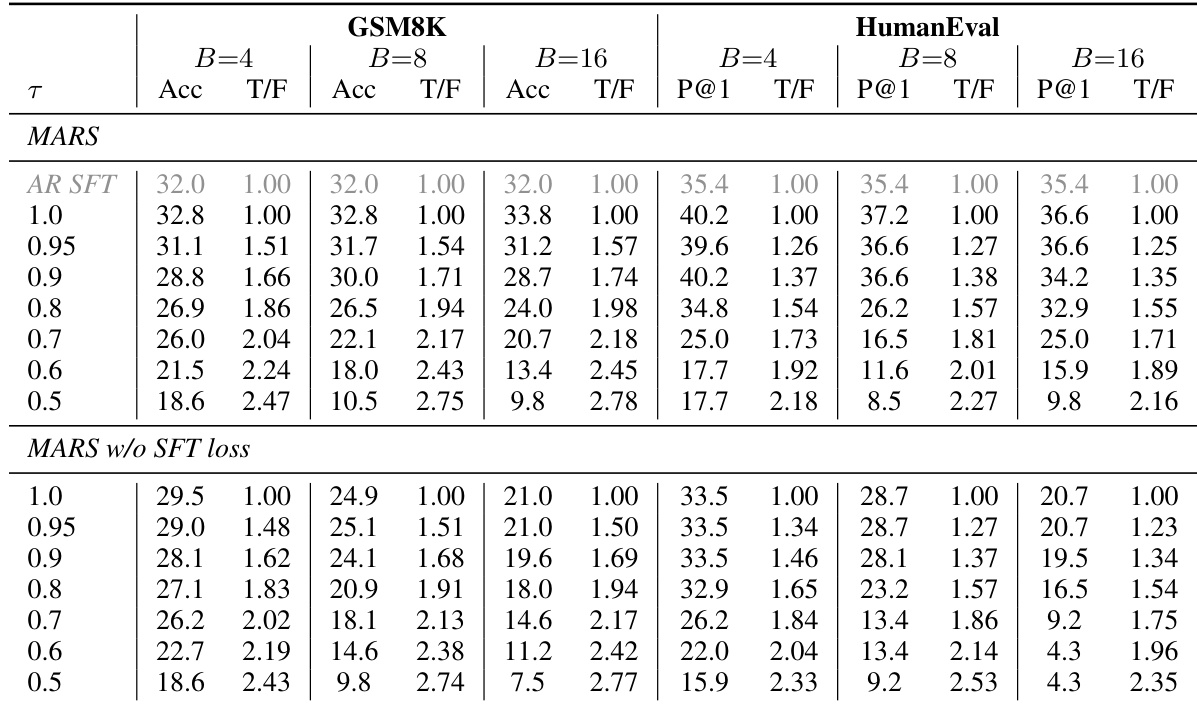
作者在 0.5B 和 7B 两种模型规模下比较了 MARS 的训练设置,突出了硬件、块大小以及是否包含 SFT 损失方面的差异。评估使用贪婪解码,最大生成长度为 256 tokens,MARS 配置为在阈值为 1.0 时每步生成一个 token。7B 模型使用 NVIDIA H200 硬件,块大小为 4;而 0.5B 模型使用了 4、8 和 16 的块大小。在测试配置中,0.5B 模型包含了 SFT 损失,而 7B 模型则排除了 SFT 损失。两个模型均使用 5e-6 的学习率,每个阶段训练 5 个 epoch,7B 模型最大序列长度为 512,0.5B 模型为 48。

该表比较了在不同置信度阈值和块大小下,包含与不包含 SFT 损失的 MARS 性能。结果显示,与不含 SFT 损失的变体相比,带有 SFT 损失的 MARS 保持了更高的准确率和更平滑的速度-质量权衡,尤其是在块大小增加时。SFT 损失的存在稳定了不同生成速度下的性能。在所有阈值和块大小下,带有 SFT 损失的 MARS 都实现了比不含 SFT 损失更高的准确率。使用 SFT 损失时,multi-token 生成带来的准确率下降是微小且可预测的。如果不使用 SFT 损失,随着块大小的增加,性能会显著下降,这表明该损失对于稳定性非常重要。
作者将 MARS 与 AR SFT 和 Block Diffusion 模型进行了比较,结果显示 MARS 在多个基准测试中保持或超越了原始 AR 模型的性能。结果表明,MARS 在单 token 生成模式下比 AR SFT 和 Block Diffusion 实现了更高的准确率,证实了额外的掩码预测训练在不降低性能的情况下增强了质量。在单 token 模式下,MARS 在多个基准测试中比 AR SFT 和 Block Diffusion 具有更高的准确率。MARS 的收益来自于掩码预测目标,而不是额外的训练计算量。Block Diffusion 表现不佳,这表明并非所有的块预测公式都与 AR 预训练兼容。
该表从四个标准比较了不同的生成方法:token masking、attention pattern、logits alignment 和 generation order。MARS 使用类似于 AR 的因果注意力 (causal attention) 和从左到右的生成方式,但在块内进行掩码 token 预测;而 Block Diffusion 使用双向注意力 (bidirectional attention) 和基于置信度的生成。MARS 使用类似于 AR 的因果注意力和从左到右的生成,但在块内进行掩码 token 预测。Block Diffusion 使用双向块内注意力 (bidirectional intra-block attention) 和基于置信度的生成。MARS 保持了类似于 AR 的右移 logits 对齐 (right-shifted logits alignment),而 Block Diffusion 则不一致。

作者在不同的模型规模和生成模式下评估了 MARS,以衡量其保持或增强原始 autoregressive 模型质量的能力。结果表明,与标准 autoregressive 基准和替代的块预测方法相比,MARS 在推理和编程任务上保持或提高了性能。研究发现,包含 SFT 损失对于稳定性能以及防止随着块大小增加而导致的质量下降至关重要。