Command Palette
Search for a command to run...
当数字开口说话:在 Text-to-Video Diffusion Models 中对齐文本数字与视觉实例
当数字开口说话:在 Text-to-Video Diffusion Models 中对齐文本数字与视觉实例
Zhengyang Sun Yu Chen Xin Zhou Xiaofan Li Xiwu Chen Dingkang Liang Xiang Bai
摘要
Text-to-video diffusion models 已经实现了开放式的视频合成,但在生成 prompt 中指定的准确物体数量方面往往面临挑战。我们提出了 NUMINA,这是一个无需训练(training-free)的“先识别后引导”(identify-then-guide)框架,旨在提升数值对齐(numerical alignment)能力。NUMINA 通过选择具有辨别性的自注意力(self-attention)和 cross-attention heads,推导出一种可计数的潜在布局(latent layout),从而识别 prompt 与布局之间的一致性问题。随后,该框架会对该布局进行保守的精细化处理,并通过调制 cross-attention 来引导重新生成。在本文提出的 CountBench 基准测试上,NUMINA 在 Wan2.1-1.3B 模型上将计数准确率提升了高达 7.4%,在 5B 和 14B 模型上分别提升了 4.9% 和 5.5%。此外,该方法在保持时序一致性(temporal consistency)的同时,还提升了 CLIP 对齐度。这些结果表明,结构化引导可以与 seed 搜索及 prompt 增强相辅相成,为实现计数准确的 text-to-video diffusion 提供了一条切实可行的路径。代码已开源至:https://github.com/H-EmbodVis/NUMINA。
一句话总结
为了提高文本到视频扩散模型中的数值对齐能力,作者提出了 NUMINA,这是一个无需训练的“先识别后引导”(identify-then-guide)框架。该框架从具有判别性的 attention heads 中推导出可计数的潜在布局(latent layouts),并通过调节 cross-attention 进行引导式再生。在 CountBench 测试中,该方法使 Wan2.1-1.3B 模型的计数准确率提升了高达 7.4%,使 5B 和 14B 模型的准确率提升了高达 5.5%,同时改善了 CLIP 对齐度并保持了时间一致性。
核心贡献
- 本文引入了 NUMINA,这是一个无需训练的“先识别后引导”框架,旨在提高文本到视频扩散模型中的数值对齐能力。
- 该方法通过选择具有判别性的 self-attention 和 cross-attention heads 来识别提示词与布局之间的一致性问题,从而推导出可计数的潜在布局,随后对其进行细化并在再生过程中用于调节 cross-attention。
- 在新的 CountBench 数据集上的实验表明,该框架在 Wan2.1-1.3B 模型以及更大的 5B 和 14B 模型上将计数准确率提高了高达 7.4%,同时增强了 CLIP 对齐度并保持了时间一致性。
引言
文本到视频 (T2V) 扩散模型对于娱乐和教育领域的高质量视频合成至关重要,但它们经常无法生成文本提示词中指定的准确物体数量。由于 numeral tokens 的语义接地(semantic grounding)较弱,以及压缩的时空潜在空间内实例可分离性不足,当前模型在数值对齐方面面临挑战。虽然重新训练模型可能解决这些问题,但计算成本以及对大规模、精确标注数据集的需求使其变得不切实际。作者利用了一个名为 NUMINA 的无需训练的框架,该框架采用“先识别后引导”范式,在去噪过程中纠正这些不一致性。通过选择具有判别性的 attention heads 来推导出可计数的潜在布局,并利用该布局引导再生,NUMINA 在提高各种模型规模计数准确率的同时,保持了时间相干性和视觉保真度。
方法
作者提出了 NUMINA,这是一个用于数值对齐视频生成的无需训练框架,它遵循“先识别后引导”范式,通过两个阶段的流水线运行。如下图所示,整个框架始于包含数字的文本提示词和一个采样的噪声向量,它们被用于生成初始视频。第一阶段为“数值失配识别”,通过分析 DiT 模型的 attention 机制来提取反映场景可计数结构的显式布局信号。该布局随后在第二阶段“数值对齐视频生成”中使用,以引导重合成过程并纠正计数偏差。
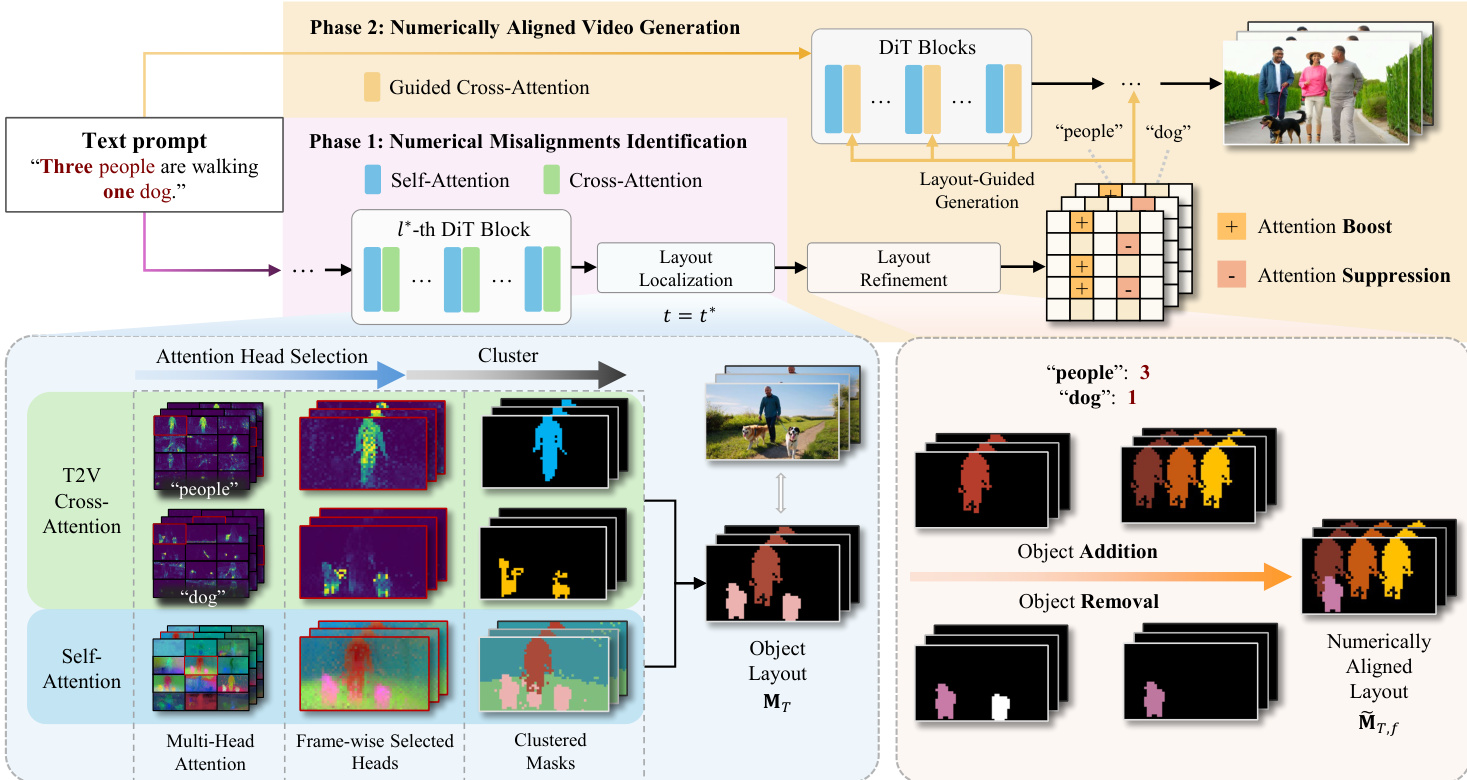
在第一阶段,该方法通过分析 DiT 的 attention 机制来识别计数偏差。这包括选择最具实例判别性的 self-attention head 和最集中于文本的 cross-attention head,然后融合它们的 maps 以获得一个显式可计数的实例级布局。通过处理 self-attention maps,使用三个互补的分数来衡量实例可分离性:前景与背景的分离度、结构丰富度和边缘清晰度。这些分数被组合成一个判别性分数,并选择分数最高的 head 以提供具有最高实例可分离性的布局。对于提示词中的每个目标名词 token,通过分析 cross-attention map 来识别具有最高峰值激活的 head,这表明模型与特定视觉区域的对齐情况。随后,这些选定的 self- and cross-attention maps 被融合,为每个目标名词构建一个可计数的的前景布局。
可计数布局的构建方式是:通过聚类从 self-attention map 生成空间提案(proposals),并通过抑制低激活值并应用基于密度的聚类来处理 cross-attention map,从而形成一个焦点掩码(focus mask)。提案根据其与焦点掩码的语义重叠程度进行过滤,具有足够重叠的区域被保留为有效实例。最终的布局是一个 2D 语义图,其中属于有效区域的每个像素都被分配相应的类别标签,从而生成一个包含不相交前景区域的地图,这些区域理想情况下对应于单个物体实例。
在第二阶段,识别出的布局被用于在生成过程中纠正计数错误。这是通过一种保守的两步法实现的:布局细化和布局引导生成。布局细化过程调整逐帧布局图,以匹配从提示词中解析出的目标计数。对于物体移除,擦除目标类别中最小的区域以尽量减少视觉影响。对于物体添加,使用布局模板插入一个新实例。如果存在现有实例,则将最小的现有区域复制作为模板;否则,使用一个圆形。通过最小化一个启发式代价函数来将模板放置在最佳位置,该函数平衡了与现有布局的重叠度、与空间中心的距离以及跨帧的时间稳定性。生成的细化布局在纠正计数错误的同时保留了原始的空间组织。
最后,细化后的布局通过对 cross-attention 进行无需训练的调节来引导再生过程。这是通过修改 pre-softmax attention scores 或偏置项(bias term)来实现的,并由一个单调递减的强度函数进行缩放,该函数在去噪过程早期应用更强的引导。对于物体移除,通过在对应于类别 token 的区域将偏置项设置为一个较大的负常数来进行 attention 抑制,从而有效地抑制不需要的实例生成。对于物体添加,则在新区域增强 attention。如果实例是通过手动圆形模板化的,则将偏置项设置为标量系数。如果通过现有参考区域模板化,则用参考区域的平均分数覆盖 pre-softmax scores,从而将预训练的 attention 特性转移到新位置。这一过程确保了稳定的控制叠加并保持了整体视觉保真度。
实验
研究人员使用 CountBench 在各种模型规模和架构(包括 Wan 和 CogVideoX)上评估了 NUMINA,这是一个旨在测试复杂文本到视频场景中数值保真度的新基准。实验表明,NUMINA 在保持时间一致性和高视觉质量的同时,显著提高了计数准确率和语义对齐度。结果显示,该方法具有高度的可扩展性,在计数较多的场景中非常有效,并为传统的试错策略(如 seed search)提供了一种更高效、更可靠的替代方案。
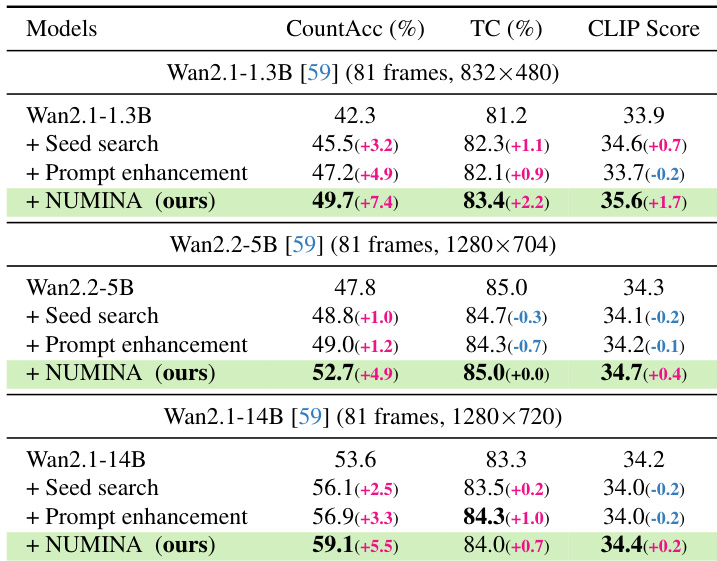
作者在文本到视频生成任务上将 NUMINA 与基准模型和现有策略进行了对比。结果显示,NUMINA 在不同模型规模下都能持续提高计数准确率,同时保持或增强了时间一致性和语义对齐度。该方法优于 seed search 和提示词增强,特别是在物体数量较多的复杂场景中。与基准模型和现有策略相比,NUMINA 显著提高了计数准确率。该方法在所有测试模型中均保持或提高了时间一致性和语义对齐度。NUMINA 使较小的模型在计数准确率上能够超越较大的基准模型。
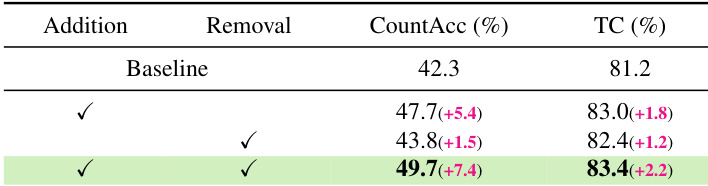
作者通过比较基准结果与添加物体添加和移除操作后的结果,评估了 NUMINA 对计数准确率和时间一致性的影响。结果表明,两种操作都能提高计数准确率,两者的结合实现了最高的性能,同时也增强了时间一致性。添加物体显著提高了基准的计数准确率。结合添加和移除操作可获得最高的计数准确率和时间一致性。该方法在增强数值对齐的同时,保持或提高了时间一致性。
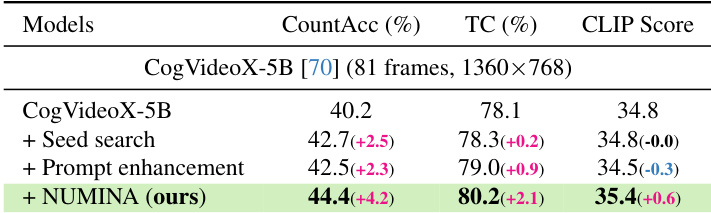
作者在 CogVideoX-5B 上评估了 NUMINA,结果显示与基准方法相比,在计数准确率、时间一致性和 CLIP 分数方面均有显著提升。结果证明 NUMINA 在保持或提高生成质量的同时增强了数值对齐。与基准和增强策略相比,NUMINA 大幅提高了计数准确率。该方法提升了时间一致性和 CLIP 分数,表明更好的视频质量和对齐度。NUMINA 通过单次生成即可实现更高的性能,避免了对 seed search 或提示词增强的需求。
作者引入了 NUMINA,这是一种增强文本到视频生成中数值对齐的无需训练的方法。结果显示,NUMINA 在各种模型上显著提高了计数准确率,同时保持或提高了时间一致性和语义质量。与基准模型和现有策略相比,NUMINA 大幅提升了计数准确率。该方法在不降低视频质量的情况下改善了时间一致性和语义对齐。将 NUMINA 与其他增强技术结合使用可获得最高的性能。
作者分析了不同超参数值对计数准确率的影响。结果显示,各种设置产生的性能相似,准确率仅有微小差异,表明该方法在各种配置下都具有稳定性。不同的超参数设置产生了相当的计数准确率,仅有轻微波动。该方法对超参数值的变化表现出鲁棒性,显示出稳定的性能。超参数值的变化对整体计数准确率的影响极小。
通过与基准模型和现有增强策略进行对比,评估了 NUMINA 在提高文本到视频生成过程中数值对齐方面的有效性。结果表明,该方法在各种模型规模和复杂场景下都能持续增强计数准确率和时间一致性。此外,该方法被证明具有高度的鲁棒性和稳定性,即使在超参数配置发生变化时也能保持高性能。