Command Palette
Search for a command to run...
MegaStyle:通过一致性 Text-to-Image Style Mapping 构建多样化且可扩展的 Style Dataset
MegaStyle:通过一致性 Text-to-Image Style Mapping 构建多样化且可扩展的 Style Dataset
Junyao Gao Sibo Liu Jiaxing Li Yanan Sun Yuanpeng Tu Fei Shen Weidong Zhang Cairong Zhao Jun Zhang
摘要
在本文中,我们介绍了 MegaStyle,这是一个新颖且可扩展的数据策展(data curation)pipeline,旨在构建一个风格内一致(intra-style consistent)、风格间多样(inter-style diverse)且高质量的风格数据集。我们通过利用当前大型生成模型一致的“文本到图像”风格映射能力来实现这一目标,这些模型能够根据给定的风格描述生成相同风格的图像。在此基础上,我们策划了一个多样化且平衡的 prompt 库,其中包含 17 万个风格 prompt 和 40 万个内容 prompt,并通过内容与风格 prompt 的组合,生成了大规模风格数据集 MegaStyle-1.4M。利用 MegaStyle-1.4M,我们提出了风格监督的对比学习(style-supervised contrastive learning)方法,用以 fine-tune 一个名为 MegaStyle-Encoder 的风格编码器,从而提取具有表现力的、特定于风格的表示(representations);此外,我们还训练了一个基于 FLUX 的风格迁移模型 MegaStyle-FLUX。广泛的实验证明了在风格数据集中保持风格内一致性、风格间多样性和高质量的重要性,同时也验证了所提出的 MegaStyle-1.4M 的有效性。此外,在 MegaStyle-1.4M 上训练后,MegaStyle-Encoder 和 MegaStyle-FLUX 能够提供可靠的风格相似度度量和具有泛化能力的风格迁移,为风格迁移社区做出了显著贡献。更多结果请访问我们的项目网站:https://jeoyal.github.io/MegaStyle/。
一句话总结
作者提出了 MegaStyle,这是一个可扩展的数据策展流水线,它利用一致的文本到图像风格映射来构建 MegaStyle-1.4M 数据集,该数据集具有高度的风格内一致性和风格间多样性。此外,他们利用风格监督的对比学习开发了 MegaStyle-Encoder 和 MegaStyle-FLUX,用于可靠的风格相似度测量和可泛化的风格迁移。
核心贡献
- 本文介绍了 MegaStyle,这是一个可扩展的数据策展流水线,利用大型生成模型一致的文本到图像映射来创建 MegaStyle-1.4M 数据集。该数据集通过结合包含 170K 个风格提示词和 400K 个内容提示词的多样化库来构建,以确保风格内一致性和风格间多样性。
- 提出了一种新颖的风格监督对比学习目标,用于微调 MegaStyle-Encoder,以提取具有表现力的且特定于风格的表示。与现有的基于语义的特征空间相比,这种方法能够实现更可靠的风格相似度测量。
- 研究人员开发了 MegaStyle-FLUX,这是一个基于 FLUX 的风格迁移模型,在 MegaStyle-1.4M 数据集上使用配对监督进行训练。实验表明,该模型实现了稳定且可泛化的风格迁移性能。
引言
图像风格迁移对于艺术生成和数字滤镜等创意应用至关重要,然而当前的方法难以将风格与内容解耦。现有方法通常依赖于自监督学习,这会导致内容泄漏,或者使用由先前的风格迁移模型生成的合成数据集,这些数据集存在多样性低、图像质量差以及单一类别内风格不一致的问题。作者利用大型生成模型一致的文本到图像映射能力来绕过这些限制。他们引入了 MegaStyle,这是一个使用大规模提示词库来生成 MegaStyle-1.4M 数据集的可扩展数据策展流水线。基于此,他们开发了用于精确风格相似度测量的 MegaStyle-Encoder 和用于稳定、可泛化风格迁移的 MegaStyle-FLUX。
数据集

-
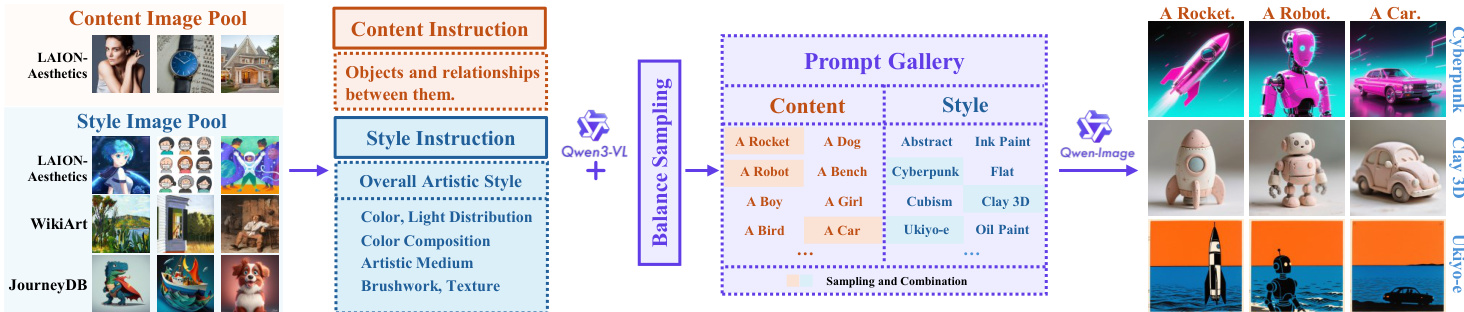
数据集组成与来源 作者引入了 MegaStyle-1.4M,这是一个旨在实现高风格内一致性和风格间多样性的大规模数据集。构建过程始于两个主要的图像池:
- 风格图像池 (2M images): 由来自 JourneyDB 的 1M 张去重图像、来自 WikiArt 的 80K 张图像以及通过 WikiArt 风格描述符过滤后的来自 LAION-Aesthetics 的 1M 张风格化图像组成。
- 内容图像池 (2M images): 由来自 LAION-Aesthetics 的剩余非风格化图像组成。
-
提示词策展与过滤 为了创建一个高质量的提示词库,作者利用 VLM Qwen3-VL 来生成专门的描述:
- 风格提示词 (Style Prompts): 这些提示词专门关注艺术方面,如色彩构成、光照分布、媒介、纹理和笔触,同时忽略内容。
- 内容提示词 (Content Prompts): 这些提示词仅描述物体和视觉关系,不包含任何风格信息。
- 过滤与平衡: 最初的 2M 个提示词经过两阶段采样过程。首先,通过 Nemo-Curator 进行精确、模糊和语义去重,将池缩减至 1M 个提示词。其次,应用层次化 k-means 平衡算法以确保多样化的分布,最终得到 170K 个风格提示词和 400K 个内容提示词。
-
数据集生成与使用 最终的 MegaStyle-1.4M 数据集使用 Qwen-Image 一致的文本到图像映射能力进行合成:
- 生成策略: 对于每个风格提示词,作者随机采样 N 个内容提示词,以创建多个内容与风格的组合。
- 最终输出: 该过程生成了 1.4M 张图像,这些图像共享相同的风格描述符,但描绘不同的语义内容。
- 训练应用: 生成的风格内一致的配对用于训练 MegaStyle-FLUX 等模型,以捕捉细粒度的风格细微差别,如笔触和纹理。
方法
作者采用了一个两阶段的风格迁移框架,首先是数据策展流水线,然后是 MegaStyle-FLUX 模型的设计。如下文图示所示,数据策展过程始于从 LAION-Aesthetics、WikiArt 和 JourneyDB 等开源数据集中收集内容和风格图像。然后,这些图像通过使用 Qwen3-VL 的提示词生成阶段进行处理,该阶段根据精心设计的指令模板生成内容和风格描述。内容提示词专注于物体关系和视觉属性而不含风格元素,而风格提示词则强调艺术特征,如色彩构成、光照分布、媒介、纹理和笔触。为了确保多样性和平衡,作者采用了层次化采样策略,按语义相似度对提示词进行分组,并从每个簇中进行采样,以形成平衡的内容与风格组合集。随后,这些组合通过 Qwen-Image 生成风格图像,从而得到一个适合训练风格迁移模型的配对内容与风格图像数据集。
所提方法的核心涉及训练一个专门的风格编码器 MegaStyle-Encoder,以提取特定于风格的表示。之前的方法依赖于针对语义对齐进行优化的视觉语言模型 (VLMs),这可能无法有效地捕获风格。为了解决这个问题,作者引入了在 MegaStyle-1.4M 数据集上训练的风格监督对比学习 (SSCL) 目标,该数据集提供了风格内一致且风格间多样化的图像对。训练目标将监督对比学习 (SCL) 与图像文本对比损失相结合。对于图像风格提示词对,SCL 损失鼓励编码器为共享相同风格的图像生成相似的表示,同时推开不同风格的表示。图像文本对比损失通过将图像特征与其对应的风格提示词嵌入对齐,进一步正则化模型。该编码器基于 SigLIP 架构,使用 8,192 的大 batch size 进行微调,以增强负样本的多样性并防止模型学习到平凡的线索。在此过程中,仅更新图像编码器参数。
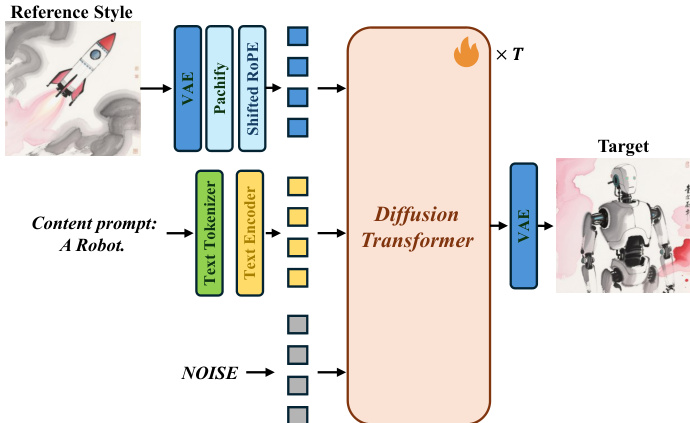
风格迁移模型 MegaStyle-FLUX 构建在 FLUX 文本到图像 (T2I) 模型之上,旨在将风格从参考图像迁移到由文本提示词指定的目标内容。如下文图示所示,该框架将参考风格图像和内容提示词作为输入。参考风格图像通过 FLUX 的 VAE 进行编码并切片为视觉 tokens。然后,这些风格 tokens 与噪声图像 tokens 以及源自内容提示词的文本 tokens 进行拼接。组合后的 tokens 被输入到扩散 Transformer (MM-DiT) 主干网络中,从而生成风格化输出。为了防止位置冲突和跨图像注意力偏差,对参考风格 tokens 应用了偏移 RoPE。在训练期间,仅更新扩散 Transformer,而所有其他组件保持冻结。这种方法使 MegaStyle-FLUX 能够通过利用大规模 MegaStyle-1.4M 数据集实现可泛化且稳定的风格迁移。
实验
评估利用自定义的 StyleRetrieval 基准测试来测试 MegaStyle-Encoder 提取特定风格表示的能力,并使用文本对齐、风格相似度和人类偏好将 MegaStyle-FLUX 模型与最先进的方法进行比较。结果表明,MegaStyle-Encoder 通过避免其他模型中常见的语义内容偏差,提供了卓越的风格检索能力。此外,MegaStyle-FLUX 实现了高度稳定且可泛化的风格迁移,在有效平衡文本对齐与风格准确性的同时,避免了现有方法中出现的内容泄漏或有限的色彩迁移问题。
作者在检索基准测试中将 MegaStyle-Encoder 与其他风格编码器进行了比较,结果显示它在不同主干网络下的 mAP 和 Recall 指标上均取得了卓越的性能。结果表明 MegaStyle-Encoder 一致优于其他方法,证明了其在提取特定风格表示方面的有效性。在所有主干网络中,MegaStyle-Encoder 的 mAP 和 Recall 分数均高于所有其他方法。在风格检索任务中,MegaStyle-Encoder 的表现优于 CLIP、CSD 和 SigLIP。该模型在 ViT-L 和 SoViT 主干网络上均表现出强大的性能,展示了跨架构的鲁棒性。
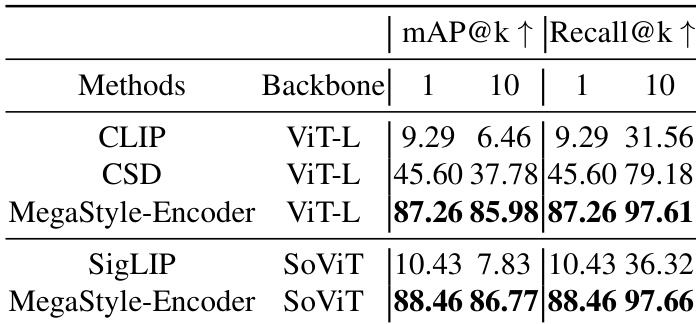
作者在多个基准测试中将 MegaStyle-Encoder 与 CLIP 和 CSD 进行了比较。结果显示,MegaStyle-Encoder 在所有评估指标和数据集的风格检索中均取得了卓越的性能,证明了其在提取特定风格表示方面的有效性。在所有基准测试和指标上,MegaStyle-Encoder 均优于 CLIP 和 CSD。在多个数据集的风格检索中,MegaStyle-Encoder 获得了最高分。该模型在 mAP 和 Recall 方面较基线模型表现出一致的性能提升。

作者将 MegaStyle-FLUX 与其他风格迁移方法进行了比较,结果显示它实现了最高的文本对齐度和具有竞争力的风格对齐度。结果表明,MegaStyle-FLUX 在将生成图像与文本提示词对齐方面优于基线模型,同时保持了强大的风格表示。在所有方法中,MegaStyle-FLUX 获得了最高的文本对齐分数。MegaStyle-FLUX 展示了强大的风格对齐能力,在对比中排名第二。在将生成图像与文本描述对齐方面,MegaStyle-FLUX 优于其他方法。

该表比较了不同的风格数据集在风格和文本对齐指标上的表现。MegaStyle-1.4M 在两项指标上均获得了最高分,证明了其在提供高质量风格和文本对齐方面的有效性。在风格对齐方面,MegaStyle-1.4M 优于其他数据集;MegaStyle-1.4M 获得了最高的文本对齐分数;与 JourneyDB 和 OmniStyle-150K 相比,MegaStyle-1.4M 表现出更优越的性能。

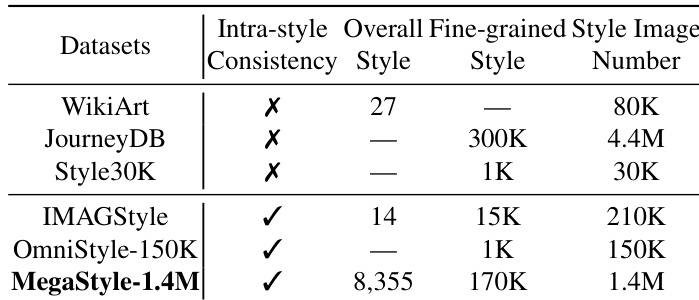
该表基于风格内一致性、风格数量和图像总数比较了不同的风格数据集。MegaStyle-1.4M 实现了高风格内一致性以及大量的风格和图像数量,在这些方面优于其他数据集。MegaStyle-1.4M 实现了高风格内一致性;MegaStyle-1.4M 拥有大量的风格和图像;其他数据集缺乏风格内一致性,或者风格和图像数量较少。
作者通过检索基准测试、风格迁移比较和数据集分析来评估 MegaStyle 框架,以验证其在捕获特定风格表示方面的有效性。结果表明,MegaStyle-Encoder 在各种主干网络下始终优于现有方法,而 MegaStyle-FLUX 在风格迁移过程中实现了卓越的文本对齐。此外,结果显示,与现有数据集相比,MegaStyle-1.4M 数据集提供了更高质量的风格和文本对齐,以及更高的风格内一致性。