Command Palette
Search for a command to run...
QuanBench+: 一个用于 LLM-Based 量子代码生成的统一多框架 benchmark
QuanBench+: 一个用于 LLM-Based 量子代码生成的统一多框架 benchmark
Ali Slim Haydar Hamieh Jawad Kotaich Yehya Ghosn Mahdi Chehimi Ammar Mohanna Hasan Abed Al Kader Hammoud Bernard Ghanem
摘要
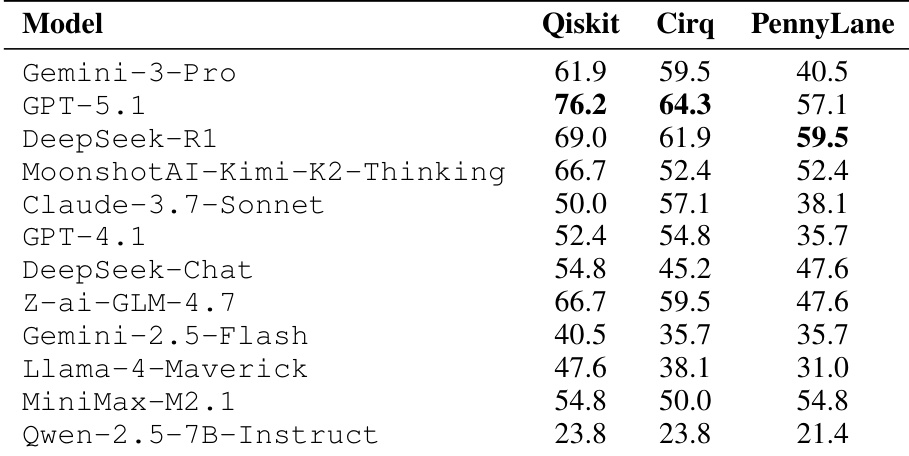
虽然 Large Language Models (LLMs) 已越来越多地应用于代码生成,但量子代码生成(quantum code generation)的评估目前大多局限于单一框架内,这使得研究者难以将量子推理能力与对特定框架的熟悉程度区分开来。为此,我们推出了 QuanBench+,这是一个涵盖 Qiskit、PennyLane 和 Cirq 的统一 benchmark,包含 42 个对齐任务,涵盖了量子算法、门分解(gate decomposition)以及态制备(state preparation)等领域。我们通过可执行的功能测试对模型进行评估,并报告了 Pass@1 和 Pass@5 指标,同时针对概率性输出采用了基于 KL-divergence 的接受度衡量标准。此外,我们还研究了基于反馈修复(feedback-based repair)后的 Pass@1 表现,即模型在遇到运行时错误或错误答案后进行代码修正的能力。跨框架评估结果显示,最强的单次生成(one-shot)得分在 Qiskit 中达到 59.5%,在 Cirq 中为 54.8%,在 PennyLane 中为 42.9%;在经过反馈修复后,最高得分分别提升至 83.3%、76.2% 和 66.7%。这些结果表明虽然研究取得了明显进展,但可靠的多框架量子代码生成问题仍未得到解决,且目前仍高度依赖于特定框架的知识。
一句话总结
为了评估基于 LLM 的量子代码生成能力,作者引入了 QuanBench+,这是一个涵盖 Qiskit、PennyLane 和 Cirq 的统一基准测试。该基准通过 42 个对齐的任务和可执行的功能测试表明,虽然基于反馈的修复(feedback-based repair)提高了 Pass@1 和 Pass@5 分数,但可靠的多框架量子推理仍然是一个尚未解决的挑战。
核心贡献
- 本研究引入了 QuanBench+,这是一个评估跨三个不同框架(Qiskit、PennyLane 和 Cirq)的量子代码生成的统一基准。该基准由 42 个对齐的任务组成,涵盖量子算法、门分解(gate decomposition)和状态准备(state preparation),旨在区分可移植的量子推理能力与特定框架的知识。
- 研究人员实现了一种可执行的功能评估方法,通过测量统计数据根据任务成功与否来定义正确性。该方法利用 Pass@k 指标以及基于 KL 散度的概率输出验收机制,以确保功能等价但语法不同的电路被正确识别为有效。
- 本研究通过单次生成(one-shot generation)和基于反馈的修复两种方式,对模型性能进行了全面分析。结果表明,虽然 Qiskit 的单次生成分数最高可达 59.5%,但应用基于反馈的修复可以显著提高性能,最高分数在 Qiskit 中提升至 83.3%,在 Cirq 中提升至 76.2%,在 PennyLane 中提升至 66.7%。
引言
随着量子计算向实际软件应用迈进,大语言模型(LLMs)越来越多地被用于自动化 Qiskit、PennyLane 和 Cirq 等各种生态系统中的代码生成。目前的基准测试通常专注于单一框架,这使得人们难以判断模型的失败是源于量子推理能力差,还是仅仅因为缺乏对特定 API 的熟悉程度。作者引入了 QuanBench+,这是一个统一的多框架基准,通过在 42 个对齐的任务中保持任务意图不变,从而隔离这两种失败模式。通过利用可执行的功能测试和基于 KL 散度的概率输出验收机制,作者提供了一种标准化的方法来评估模型是具备可移植的量子推理能力,还是仅仅掌握了特定框架的知识。
数据集
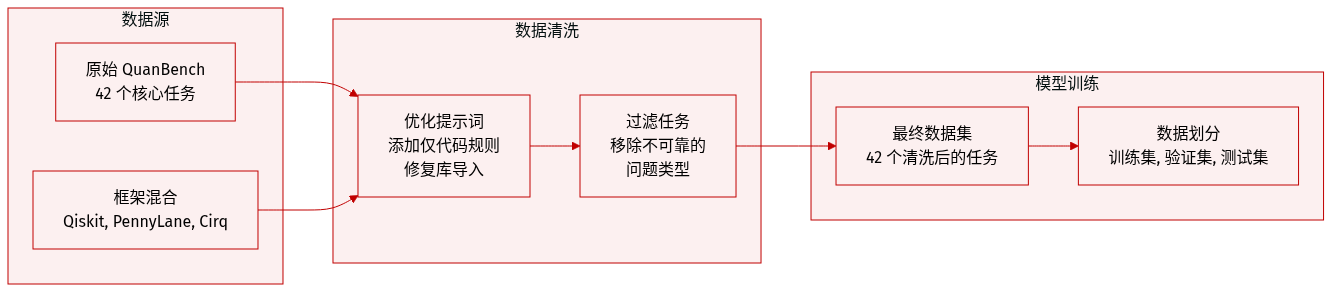
作者使用了 QuanBench+,这是一个源自原始 QuanBench 任务集的数据集。该数据集的结构如下:
- 组成与类别:该基准由 42 个任务组成,分为三个不同类别:量子算法、门分解和状态准备。
- 来源与适配:作者将原始任务适配到了三个特定的量子计算框架:Qiskit、PennyLane 和 Cirq。这种适配涉及修改提示词(prompts),以符合特定框架的 API 和库规范。
- 过滤与精炼:为了确保可靠的跨框架评分,作者从原始基准中移除了两个不符合一致性评估必要标准的任务。
- 提示工程与处理:
- 修改了所有提示词,以确保为每个相应的框架导入正确的库。
- 在每个提示词的开头添加了严格的约束,要求模型仅返回代码。这去除了随附的解释,以提高执行效率和评分一致性。
方法
作者利用了一个模块化的流水线来评估量子代码生成,该流水线围绕一个集成多个量子计算平台的框架构建。过程始于选择要测试的框架(具体为 Qiskit、PennyLane 或 Cirq),每个框架都通过 OpenRouter 管理的统一 API 接口进行访问。这种设置允许在抽象底层实现差异的同时,与不同的量子开发环境进行一致的交互。

如下图所示,选定的框架用于生成量子代码,然后作为 API 请求发送到后端系统。响应被解析以提取生成的代码,随后在隔离的沙盒环境中执行以确保安全性和可重复性。输出会针对标准答案进行验证以评估正确性。对于确定性任务,验证涉及检查生成的程序在预定义测试桩(harness)下是否满足固定的正确性标准。对于概率性任务,正确性由测量结果分布与参考分布的一致性来确定。
为了处理概率性任务,作者根据标准电路执行的内在变异性校准了一个全局验收阈值。对于每个任务,参考分布被计算为标准电路 1000 次重复执行的归一化均值。标准内的变异性通过经验分布与参考分布之间的 Kullback-Leibler (KL) 散度进行量化。然后,从所有任务汇总后的 KL 散度值的第 99.7 百分位数中导出全局阈值,得到阈值 τ=0.05,并在整个评估过程中一致使用。这种校准确保了验收标准考虑了量子测量中自然的 shot noise 和变异性。
实验
QuanBench+ 基准测试评估了一系列前沿和开源权重的 LLMs 在三个框架(Qiskit、Cirq 和 PennyLane)上生成功能性量子代码的能力。评估利用了 Pass@k 指标,并将单次生成与涉及提示词预填充(prompt prefilling)和基于反馈的迭代修复的设置进行了比较。结果揭示了框架难度存在显著的不对称性,Qiskit 最容易,而 PennyLane 最具挑战性,这表明模型性能与特定框架的 API 熟悉程度密切相关。虽然反馈循环有效地修复了许多表层的实现和接口错误,但它们并不能完全弥合性能差距,也无法解决在所有框架中普遍存在的更深层次的语义和推理错误。
柱状图显示了不同模型和框架的 Pass@1 分数,其中 Qiskit 实现了最高的性能,而 PennyLane 最低。基于反馈的修复显著提高了所有框架的分数,但框架之间的相对排名和性能差距保持一致。Qiskit 在各模型中始终获得最高的 Pass@1 分数,PennyLane 在各模型中始终具有最低的 Pass@1 分数,基于反馈的修复提高了所有框架的性能并缩小了模型间的差距。
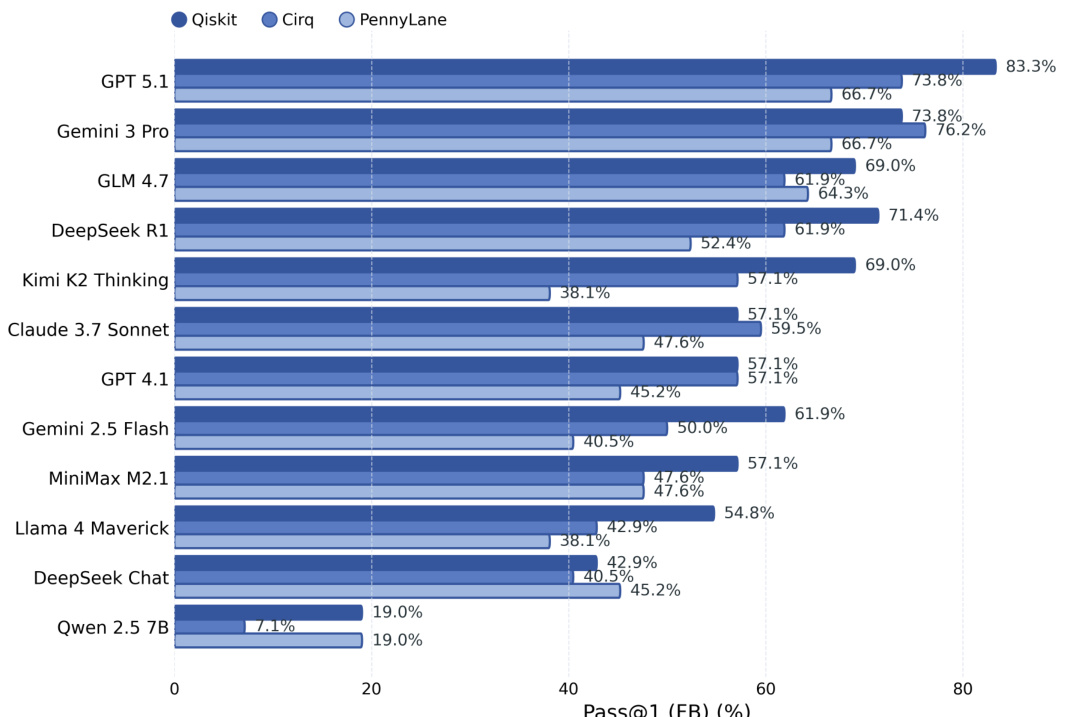
作者比较了三个量子计算框架下的模型性能,显示出一致的难度差异。结果表明 Qiskit 是最容易的框架,PennyLane 是最难的,且性能随模型和框架的变化而显著不同。Qiskit 在各模型中始终产生最高的性能,而 PennyLane 显示出最低的分数。模型排名在不同框架之间发生变化,没有单一模型能主导所有环境。即使在反馈修复之后,框架之间的性能差异仍然存在,表明存在特定框架的挑战。
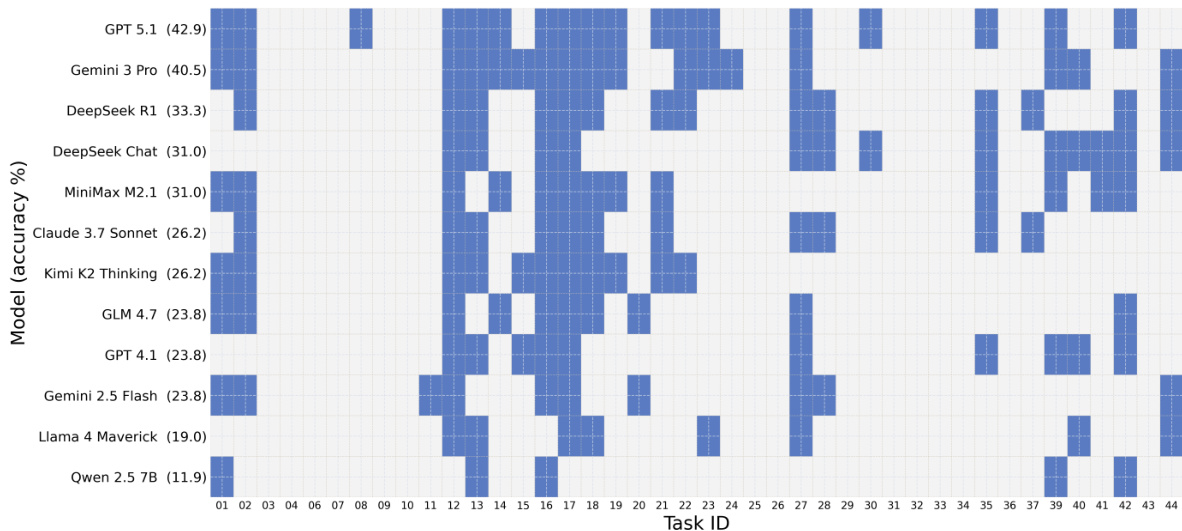
热图可视化了各种模型在不同任务中的单次生成正确性,显示 Qiskit 通常比 PennyLane 和 Cirq 具有更高的准确率。模型在不同任务中表现出不同的性能,一些模型取得了广泛的成功,而另一些则表现出较为分散的结果。在各模型中,Qiskit 始终显示出比 PennyLane 和 Cirq 更高的准确率。模型性能在不同任务间差异显著,部分模型取得广泛成功,部分模型结果较为分散。热图揭示了模型能力的差异,更强大的模型在任务中表现出更一致的成功。
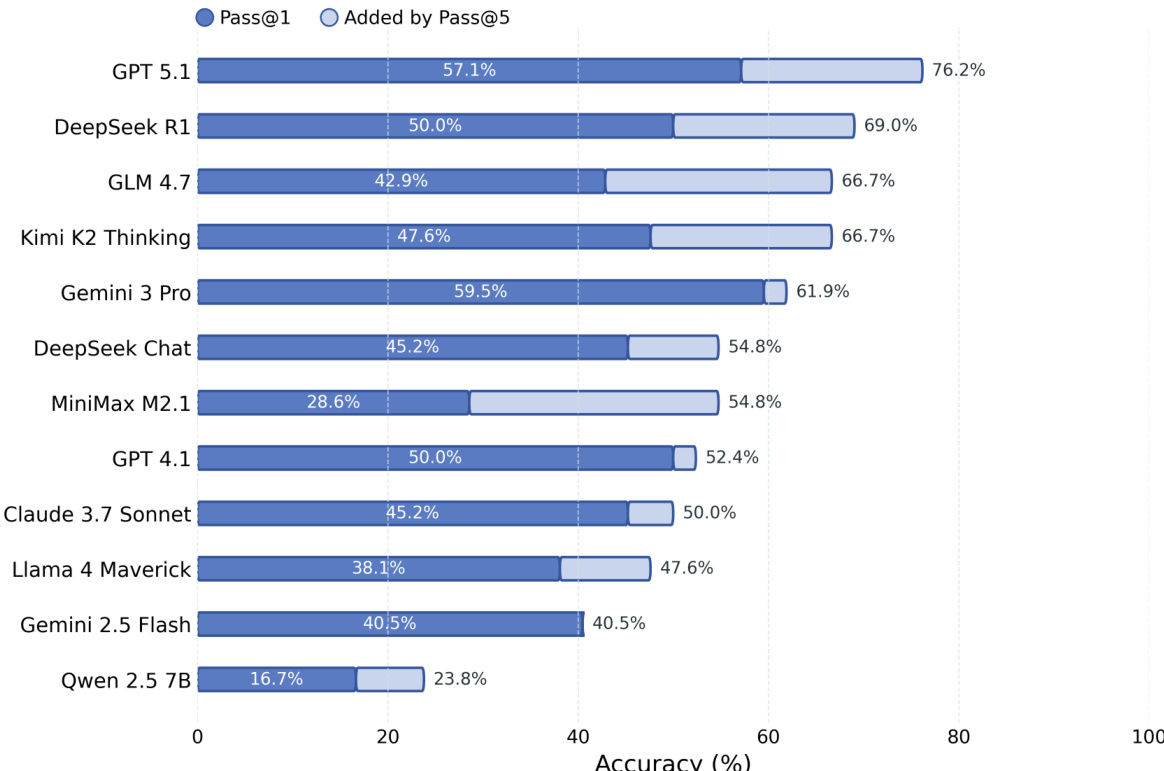
柱状图比较了各种模型的 Pass@1 准确率与通过 Pass@5 实现的额外正确性。结果显示,大多数模型通过生成多个样本获得了显著提升,其中 GPT 5.1 实现了最高的整体准确率,而 Qwen 2.5 7B 从 Pass@5 中获得的提升最小。与 Pass@1 相比,Pass@5 实质性地提高了大多数模型的准确率,GPT 5.1 获得了最高的 Pass@1 和 Pass@5 分数,Qwen 2.5 7B 从 Pass@5 中获得的收益最小。
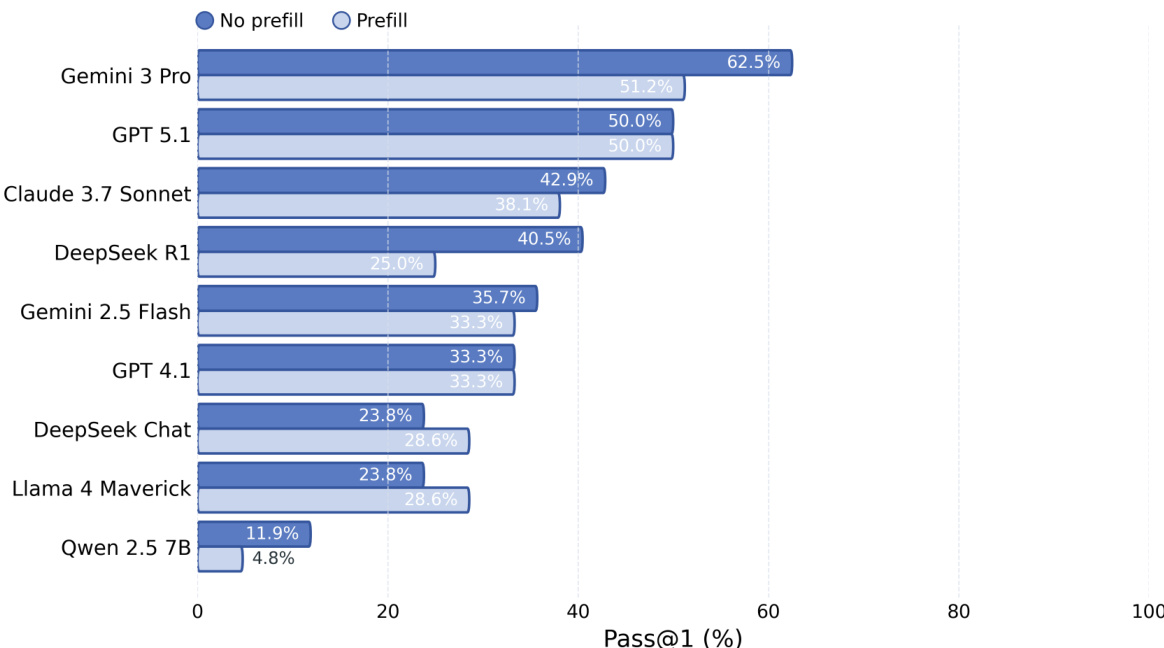
作者比较了多个模型在无预填充(no-prefill)和预填充(prefill)设置下的 Pass@1 性能。结果显示,预填充一致地提高了性能,在模板代码(boilerplate code)更易出错的模型和框架中观察到更大的增益。最强大的模型从预填充中受益较少,这表明预填充主要减少了与设置相关的错误,而非核心推理挑战。预填充提高了所有模型的 Pass@1,对于较弱的模型和设置复杂的框架增益更大。最大的性能提升发生在模板代码容易遗漏的框架中。更强大的模型从预填充中受益较少,表明它主要解决表层的编码错误而非推理问题。
这些实验评估了模型在不同量子计算框架、修复策略和提示设置下的性能,以识别编码准确性的关键驱动因素。结果表明,Qiskit 始终是最容易上手的框架,而 PennyLane 难度最大,且无论是否进行基于反馈的修复,性能差距依然存在。此外,虽然多次采样和预填充技术通过缓解模板代码错误和设置挑战显著增强了准确性,但能力最强的模型对这些改进的敏感度较低。