Command Palette
Search for a command to run...
RAGEN-2:Agentic RL 中的推理崩溃
RAGEN-2:Agentic RL 中的推理崩溃
摘要
多轮 LLM Agent 的 RL training 本质上是不稳定的,且推理质量直接决定了任务性能。熵(Entropy)被广泛用于追踪推理的稳定性。然而,熵仅能衡量相同输入下的多样性,无法反映推理过程是否真正对不同输入做出了响应。在 RAGEN-2 中,我们发现即使在熵值稳定的情况下,模型也可能依赖于看似多样但与输入无关(input-agnostic)的固定模板。我们将这种现象称为“模板崩溃”(template collapse),这是一种熵及所有现有指标都无法察觉的失效模式。为了诊断这一失效问题,我们将推理质量分解为输入内多样性(即 Entropy)和跨输入可区分性(即 Mutual Information, MI),并引入了一系列用于在线诊断的互信息(mutual information)代理指标。在多种任务中,Mutual Information 与最终性能的相关性显著强于 Entropy,使其成为衡量推理质量更可靠的代理指标。我们进一步通过信噪比(Signal-to-Noise Ratio, SNR)机制来解释模板崩溃现象。低奖励方差(reward variance)会削弱任务梯度,导致正则化项占据主导地位,从而抹除跨输入的推理差异。为解决这一问题,我们提出了 SNR-Aware Filtering 方法,利用奖励方差作为轻量级代理指标,在每次迭代中筛选出高信号的 prompt。在规划(planning)、数学推理、网络导航和代码执行等任务中,该方法均能持续提升输入依赖性(input dependence)和任务性能。
一句话总结
通过将 template collapse(模板崩溃)识别为一种 agentic reinforcement learning 模型在熵值稳定的情况下仍采用与输入无关的推理模式的失败模式,RAGEN-2 研究提出使用互信息代理进行诊断,并引入了 SNR-Aware Filtering(信噪比感知过滤)来提升在规划、数学推理、网络导航和代码执行任务中的性能。
核心贡献
- 本文引入了 template collapse 的概念,这是多轮 LLM agent 训练中的一种失败模式,即模型依赖于看似多样化但并不响应特定输入的与输入无关的推理模板。
- 这项工作提出了一个新的诊断框架,通过一系列互信息代理将推理质量分解为输入内多样性(within-input diversity)和跨输入可区分性(cross-input distinguishability)。这些代理比传统的熵指标与最终任务性能具有更强的相关性。
- 研究人员提出了 SNR-Aware Filtering,这是一种利用奖励方差作为信号强度代理,在训练期间选择高信号 prompt 的方法。在规划、数学、网络导航和代码执行方面的实验表明,该方法同时提高了输入依赖性和整体任务性能。
引言
使用 reinforcement learning 训练多轮 LLM agents 是开发自主推理系统的关键任务,但其本质是不稳定的。虽然研究人员通常使用熵来监测推理稳定性,但熵仅衡量单个输入内部的多样性,无法检测模型何时开始依赖固定的、与输入无关的模板。作者将这种现象识别为 template collapse,这是一种推理看起来很多样化但失去了对特定输入依赖性的失败模式。为了解决这个问题,作者利用互信息 (MI) 代理来诊断输入依赖性,并引入了 SNR-Aware Filtering,该方法使用奖励方差来选择高信号 prompt,并在训练期间保持有效的任务梯度。
数据集

-
数据集组成与来源:作者利用了由七个合成且完全可控的环境组成的多元测试平台,旨在评估各种决策机制。这些环境包括 Sokoban(网格谜题)、FrozenLake(导航)、MetaMathQA(数学推理)、Countdown(算术游戏)、SearchQA(多轮搜索)、WebShop(电子商务导航)和 DeepCoder(程序综合)。DeepCoder 特别借鉴了 PrimeIntellect、TACO 和 LiveCodeBench v5。
-
关键子集详情:
- Sokoban:使用具有可配置维度和箱子数量的程序化生成谜题,以研究不可逆的规划。
- FrozenLake:一个导航任务,具有 2% 的随机转移率,以模拟随机动态和稀疏奖励。
- MetaMathQA:一个数学问答任务,正确性通过与标准答案的精确匹配来确定。
- Countdown:一个组合算术任务,agent 必须构建表达式以达到目标数字。
- SearchQA:一个需要迭代网络搜索和信息综合的多轮环境。
- WebShop:一个具有庞大动作空间和真实产品目录的交互式电子商务模拟。
- DeepCoder:一个编程基准测试,agent 生成 Python 函数以通过特定的测试用例。
-
训练与使用:作者使用 veRL/HybridFlow 技术栈训练了一个 Qwen2.5-3B 模型。训练过程涉及比较不同的 RL 算法,包括 PPO、DAPO、GRPO 和 Dr. GRPO,进行多达 400 次 rollout-update 迭代。在每次迭代中,模型使用 8 的 prompt batch size 和每个 prompt 16 个 trajectory 的 group size,在每个环境中收集 128 个 trajectories。
-
处理与奖励工程:
- 奖励塑造 (Reward Shaping):作者应用特定的奖励结构来引导学习,例如为 MetaMathQA 应用递减奖励方案(每次后续重试奖励减半),以及为 Countdown 基于格式和解法正确性应用多层级奖励。
- SNR-Aware Filtering:在应用此过滤技术时,作者按保持率(keep rate)减少有效的 minibatch size,并相应地缩放每步 loss,以保持可比的优化步长。
方法
作者解决了闭环多轮 agent reinforcement learning 中的 template collapse 挑战,其中策略 πθ 根据观测 ot 生成推理 tokens zt 和可执行动作 at,形成 trajectories τ={ot,zt,at,rt}t=1T。一个关键见解是,标准的 reinforcement learning 目标(如 PPO 或 GRPO)对所有输入应用统一的正则化(例如 KL 散度、熵奖励),这可能会无意中促进与输入无关的推理。这种现象的特征是输入 prompt X 与生成的推理 Z 之间的互信息 I(X;Z) 较低,表明模型未能根据特定问题调整其推理。作者通过对策略梯度的信噪比 (SNR) 分析将此问题形式化,并将 prompt 内奖励方差低识别为 template collapse 的主要原因。
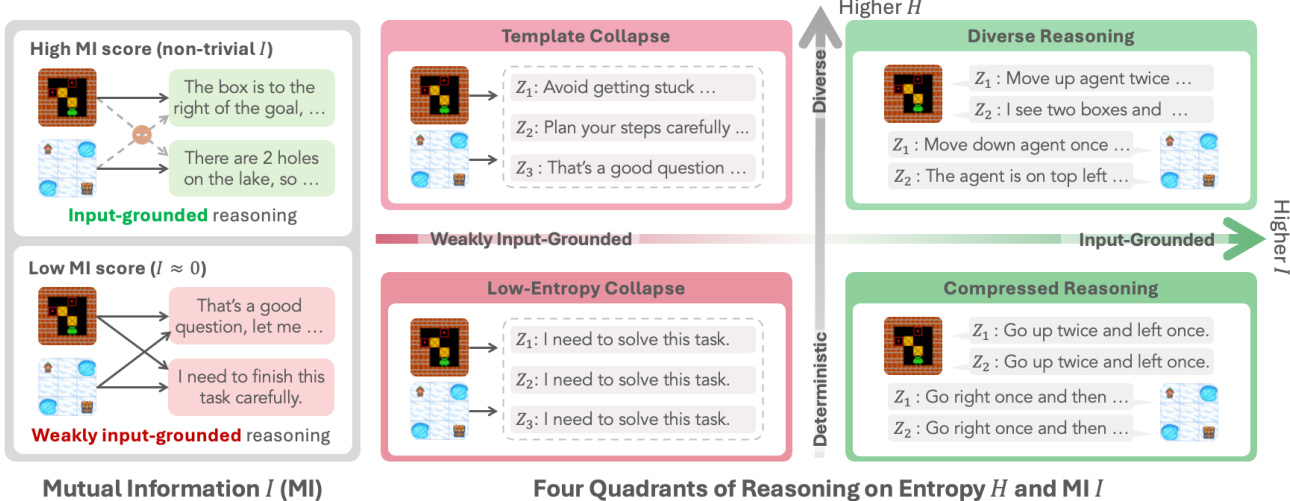
通过分析两个关键维度建立了理解推理机制的框架:通过条件熵 H(Z∣X) 衡量的输入内多样性,以及通过互信息 I(X;Z) 衡量的输入依赖性。如上图所示,这两个轴定义了四种不同的推理机制。高 H(Z∣X) 和高 I(X;Z) 对应于多样化且基于输入的推理,模型会根据特定输入调整其思考过程。相反,低 H(Z∣X) 和低 I(X;Z) 定义了“低熵崩溃”机制,其特征是确定性的、模板式的响应,且与输入的关联较弱。作者认为,使用熵正则化来增加 H(Z∣X) 的标准做法可能会适得其反,因为它可能不会增加 I(X;Z),甚至可能导致其降低,这在定理 M.2 中得到了形式化。template collapse 的核心机制是与任务无关的正则化压倒了与任务相关的信号,这在奖励方差较低的 prompt 上尤为明显。
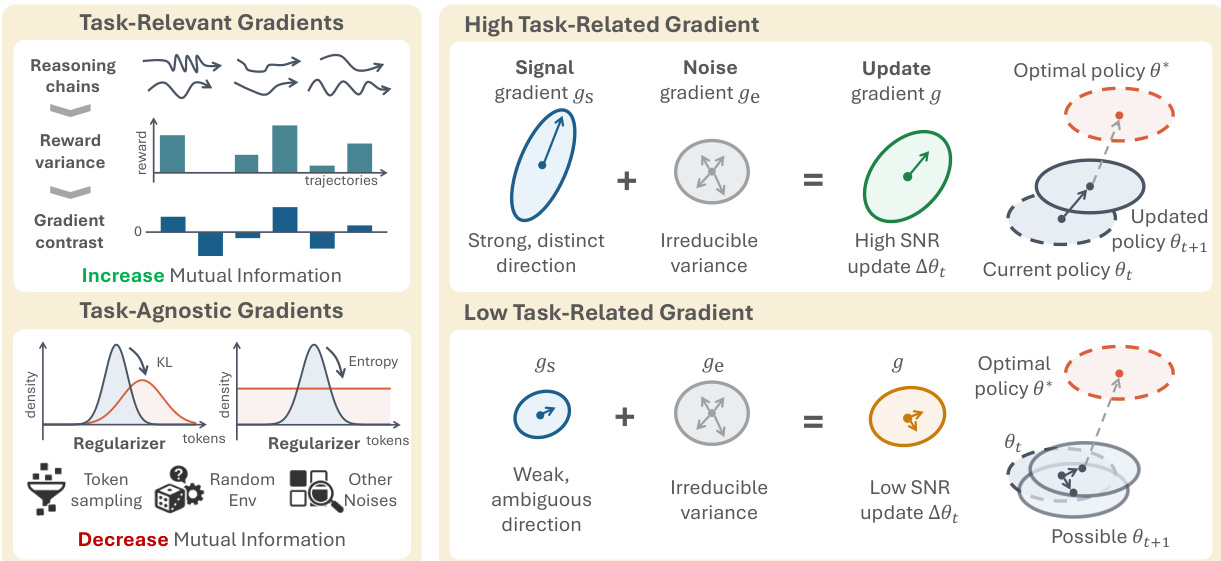
作者对这一现象提供了详细的梯度级解释,如图所示。在高 SNR 机制中,任务梯度 gtask 强且清晰,代表了改进策略的明确信号。这种强信号通过奖励方差得到放大,如定理 H.2 中的 Cauchy-Schwarz 不等式界限所示。正则化梯度 greg 作为一个噪声项,但其影响被强大的任务信号所抵消。相比之下,在低 RV prompt 上,任务梯度 gtask 显著减弱,而正则化梯度 greg 保持不变。这导致总更新被与输入无关的正则化噪声所主导,将策略推向低互信息 I(X;Z) 的状态。这被可视化为更新梯度 g 的一个微弱且模糊的方向,可能导致策略偏离最优策略 θ∗。

为了缓解这个问题,作者提出了一种称为 SNR-Aware Filtering 的方法。这种方法通过根据信号质量选择训练样本来直接解决根本原因。如图所示,该工作流程分为三个步骤。首先,在采样期间,策略为每个 prompt x 生成多个 trajectories。其次,为每个 prompt 计算 prompt 内奖励方差 RV(x),作为任务信号强度的代理。方差较低的 prompt 被识别为信号较弱。第三,应用过滤机制仅保留高信号 prompt。作者使用 top-p 过滤策略,按奖励方差降序排列 prompt,并保留累计方差质量达到总方差质量比例 ρ 的最小前缀。这种自适应选择确保了策略更新集中在高 SNR prompt 上,有效地过滤掉了会被与输入无关的正则化所主导的低方差 rollout。这一过程防止了 I(X;Z) 的退化并恢复了以输入为条件的推理。
实验
实验通过分析各种任务、算法和模型规模下的梯度动态和互信息,评估了 reinforcement learning agents 中的 template collapse 现象。结果表明,低奖励方差导致任务判别梯度被与输入无关的正则化所淹没,从而导致推理虽然流利但忽略了输入细节。实施 SNR-Aware Top-p 过滤通过优先考虑高信号更新,一致地提高了任务性能并保留了信息内容,证明其比单纯使用基于熵的诊断或正则化更有效。
表格概述了实验中使用的不同环境的关键特征,包括其随机性、回合结构、状态表示和奖励类型。这些特征有助于对任务进行分类并为实验设置提供参考。环境的随机性各不相同,有些是随机的,有些是确定性的。多轮任务涉及多个交互步骤,而单轮任务只有一个步骤。状态表示在基于网格和基于文本的格式之间有所不同,奖励类型分为密集型或二进制。

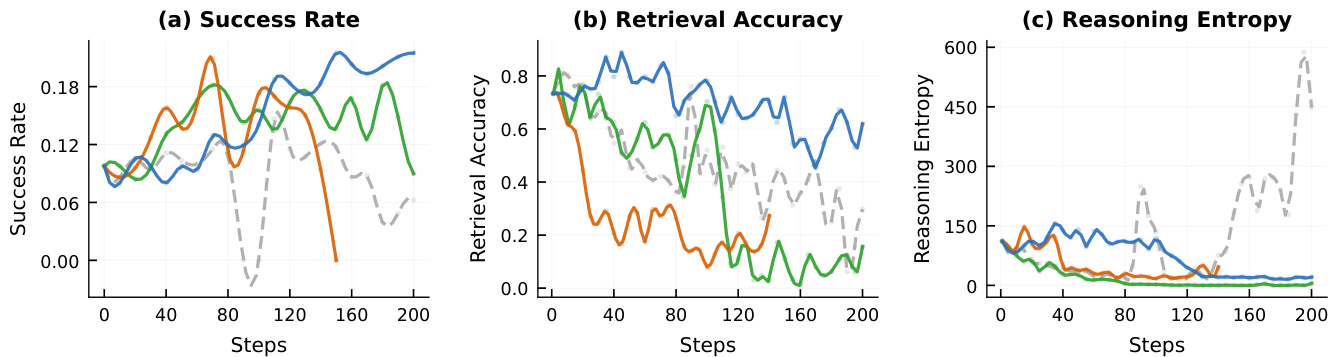
作者比较了 reinforcement learning 训练中不同的干预策略,表明 SNR-Aware Filtering 在防止互信息下降(这在不进行过滤时会发生)的同时,保留了任务性能和推理多样性。在不进行过滤的情况下,任务成功率在初始峰值后急剧下降,检索准确率下降,且推理熵增加,表明发生了 template collapse。相比之下,过滤在整个训练过程中保持了稳定的检索准确率和低熵。SNR-Aware Filtering 防止了在无过滤基线中看到的任务性能和检索准确率下降。在没有过滤的情况下,推理熵显著增加,标志着输入特定推理能力的丧失。过滤维持了稳定的互信息和推理多样性,避免了在未过滤训练中观察到的退化。
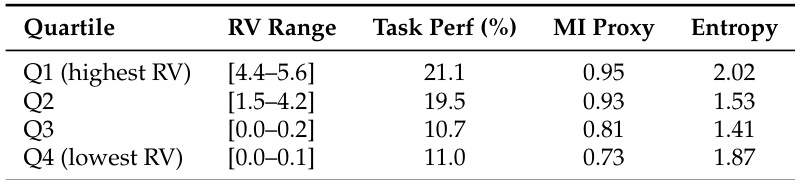
实验通过根据 RV 将 prompt 分组为四分位数,评估了奖励方差 (RV) 对模型性能的影响。结果显示,随着 RV 降低,任务性能和互信息 (MI) 代理单调下降,表明较高的奖励方差与更好的学习效果相关。最低的 RV 四分位数表现出最弱的任务性能和 MI,而最高的 RV 四分位数取得了最好的结果。随着奖励方差降低,任务性能和 MI 代理在各四分位数之间单调下降。具有最高奖励方差的四分位数实现了最佳的任务性能和 MI 代理。具有最低奖励方差的四分位数显示出最弱的任务性能和 MI 代理。
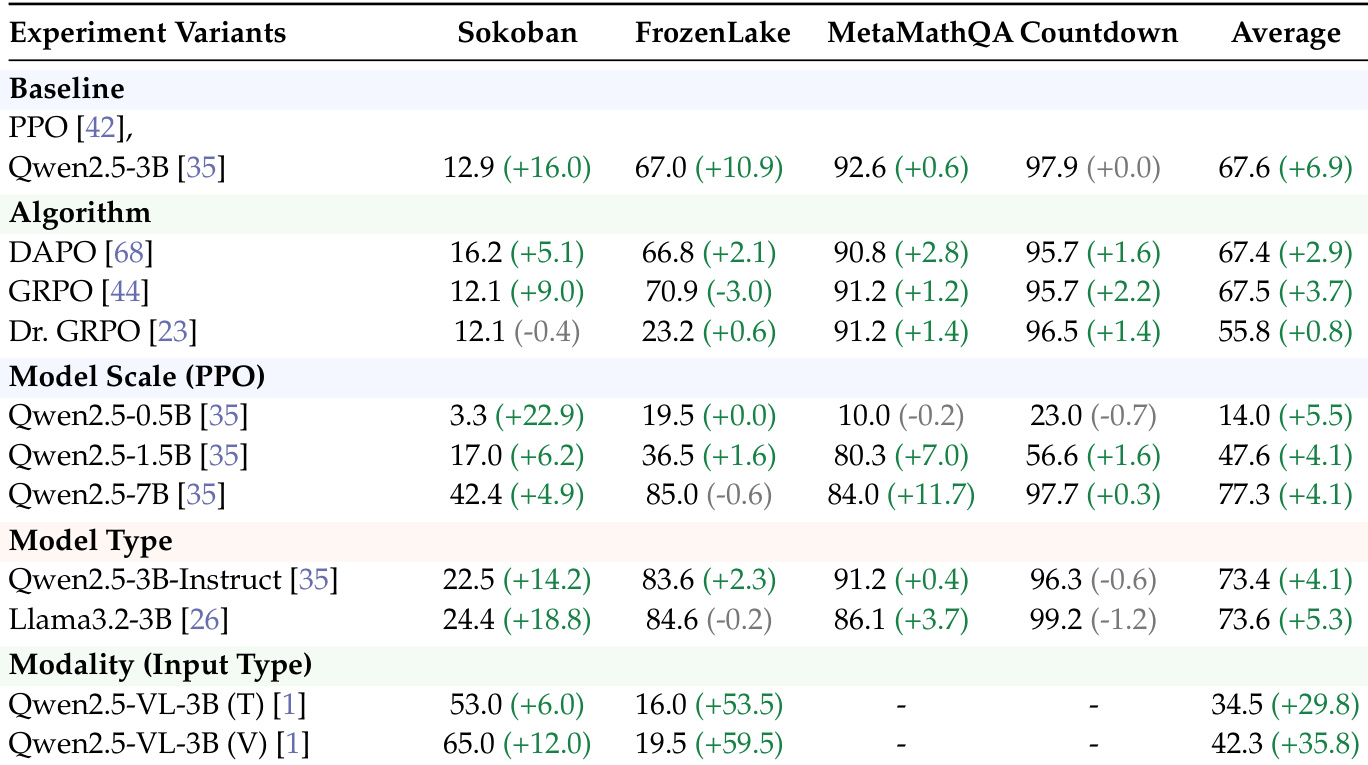
作者在各种 RL 算法、模型规模和输入模态上评估了 SNR-Aware Filtering。结果表明,过滤在不同的配置下一致地提高了峰值任务成功率,证明了其作为增强学习效率的通用方法的有效性。SNR-Aware Filtering 提升了多种 RL 算法和模型规模下的性能。该方法在大多数实验设置中一致地增加了峰值任务成功率。在包括文本和图像条件模型在内的不同输入模态中均观察到了收益。
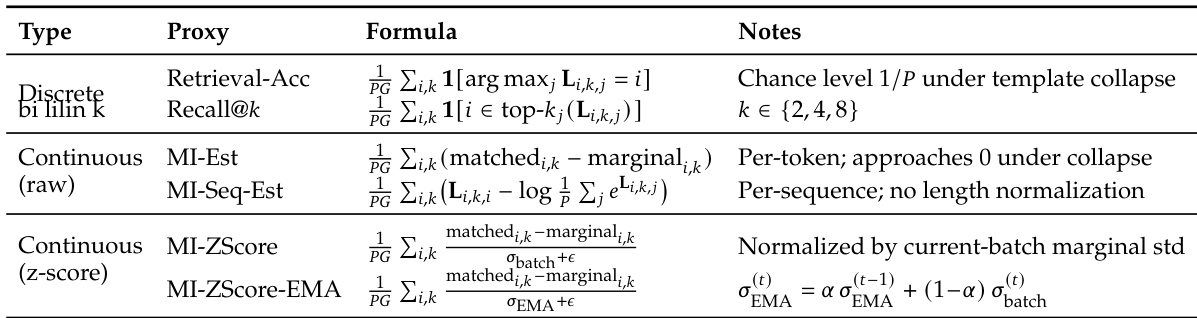
表格概述了用于评估 agent 训练中推理质量的不同互信息代理指标。这些代理在公式和计算方法上各不相同,一些侧重于检索准确率,另一些侧重于归一化分数或基于熵的估计。这些指标旨在通过测量输入依赖性和推理多样性来检测 template collapse。表格列出了多种 MI 代理指标,包括基于检索的和归一化的连续分数,以评估推理质量。不同的代理使用不同的公式,例如基于 argmax 的选择或边际差异,来估计互信息。一些代理(如 MI-ZScore-EMA)结合了平滑和归一化,以便在训练期间更稳健地跟踪 MI 动态。
实验评估了各种 reinforcement learning 环境和干预策略,以评估它们对任务性能和推理多样性的影响。结果表明,SNR-Aware Filtering 防止了 template collapse 并维持了稳定的推理质量,而未过滤的训练会导致互信息和检索准确率的下降。此外,研究结果表明,较高的奖励方差与改进的学习效果相关,并且过滤方法在不同的算法、模型规模和输入模态下一致地增强了峰值成功率。