Command Palette
Search for a command to run...
Autoreason: 知晓何时停止的自我修正机制
Autoreason: 知晓何时停止的自我修正机制
摘要
迭代式自我修正(Iterative self-refinement)之所以失效,主要归结为三个原因:首先是 prompt bias(提示词偏差),即对抗性批判式 prompt 会导致模型幻觉出并不存在的问题;其次是 scope creep(范围蔓延),即每一次修订过程都会导致文档范围在不受控的情况下不断扩张;最后是 lack of restraint(缺乏约束力),即模型几乎从不拒绝进行修改,即便当前的输出已经足够优秀。这三个因素共同导致了输出质量的渐进式退化。为此,我们提出了 autoreason。该方法通过将每一次迭代结构化为三种选择,从而解决了上述三个问题:保持不变的原有版本 (A)、对抗性修订版本 (B) 以及综合版本 (AB)。随后,由不具备 prompt 历史或会话上下文的新 agent 通过盲审 Borda count(博达计数法)对这些候选版本进行评判。这种机制确保了“不做任何改动”始终是一个同等地位的选项,并且评估者不会受到产生修订版本时所携带的偏见影响。该方法的价值在中层模型(mid-tier models)上体现得最为显著,因为这类模型的生成能力与自我评估能力之间的差距最大。在使用 Haiku 3.5(成本约为 Sonnet 4 的十分之一)时,autoreason 在三项任务中均获得了 42/42 的 Borda 分数,实现了完美全胜;相比之下,标准的 refinement 基准测试反而导致同一模型的输出质量下降,甚至低于未经修正的单次生成(single pass)结果。通过对五个模型层级(Llama 8B、Gemini Flash、Haiku 3.5、Haiku 4.5、Sonnet 4)的测试发现,该方法的优势在中层模型达到顶峰,而在两个极端层级均有所下降:即模型弱到无法生成多样化的备选方案(如 Llama),或模型强到不再需要外部评估(如 Sonnet 4)。Haiku 4.5 的表现证实了这种趋势:在代码任务的私有测试集上,其准确率达到 60%(与 Sonnet 的单次生成持平),此时 autoreason 在留存测试(held-out tests)上的增益完全消失,尽管它在可见测试集(visible tests)上仍有 4 个百分点的提升。
一句话总结
作者提出了 Autoreason,这是一个自我改进框架,通过将每次迭代结构化为在未改变的现有方案(incumbent)、对抗性修订(adversarial revision)和综合方案(synthesis)之间的三方选择,来缓解提示词偏差、范围蔓延和缺乏约束的问题。该框架通过独立的 Agent 使用盲审 Borda count 进行评估,使模型能够在输出达到最优时停止改进。
核心贡献
- 本文引入了 autoreason,一种将迭代改进结构化为在未改变的现有方案、对抗性修订以及两者综合方案之间的三方选择的方法。
- 该方法利用没有先前提示词历史或会话上下文的新 Agent,通过盲审 Borda count 来评判候选方案,从而防止了标准自我改进中常见的偏差和范围蔓延。
- 实验结果表明,使用 Haiku 3.5 时,autoreason 在三项任务中实现了 42/42 的完美 Borda 分数,显著优于会导致输出退化的标准改进基准方法。
引言
迭代自我改进是提高大语言模型输出的一种常用技术,但由于提示词偏差、不受控制的范围蔓延以及缺乏约束(即模型即使在输出完美时也感到必须进行修改)的问题,它经常面临渐进式退化的困扰。现有方法经常失败,因为它们依赖于单 Agent 循环,或者缺乏允许模型选择“不进行任何修改”的机制。作者利用一种名为 autoreason 的结构化三方选择框架来解决这些问题。通过向使用盲审 Borda count 的独立评审员展示未改变的现有方案、对抗性修订和综合方案,该方法确保了“不做任何事”仍然是一个可行的选项。这种方法对于中层模型特别有效,这些模型具备生成多样化替代方案的能力,但缺乏选择最佳方案的自我评估能力。
方法
作者利用了一种名为 autoreason 的结构化迭代框架,它作为一个由三个不同 Agent 角色驱动的闭环系统运行:Critic、Author 和 Synthesizer,所有角色都在一个迭代循环中运行。该过程始于一个 Task Prompt,用于初始化现有文档,记作 A。在每一次迭代中,一个新的 Critic agent 会评估当前的现有文档 A 并生成批评意见,识别缺点但不提出解决方案。随后,该批评意见会被传递给一个新的 Author agent,它会对现有文档进行修订,从而产生一个新的对抗性修订版,标记为 B。同时,一个新的 Synthesizer agent 会将原始现有文档 A 和对抗性修订版 B 相结合,通过整合两者的最强元素来创建一个综合候选方案 AB。
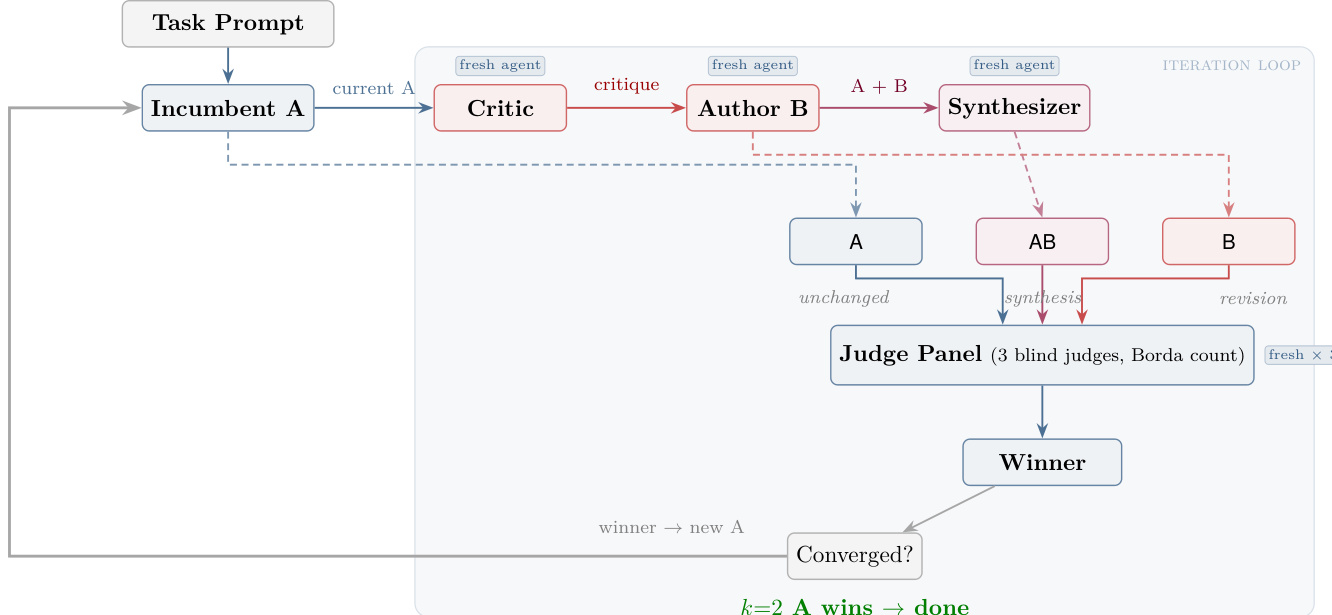
如下图所示,三个候选方案——A(未改变的现有方案)、AB(综合方案)和 B(修订方案)被提交给由三个盲审评审员组成的 Judge Panel。评审员使用 Borda count 系统对候选方案进行排名,分别为第一、第二和第三名分配 3、2 和 1 分,若出现平局,则倾向于现有方案。胜出者根据汇总得分选出,除非现有方案 A 连续两次胜出(触发收敛),否则过程将继续进行。
该框架确保每个 Agent 角色都是一个全新的、隔离的实例,除了任务提示词外没有共享上下文,从而促进了独立性并减少了偏差传播。迭代过程的正式定义为:dt 代表第 t 次迭代的现有文档,每次迭代生成候选方案 {dt,B(dt),S(dt,B(dt))},其中 B 是对抗性修订算子,S 是综合算子。每一步的胜出者通过在 n 个评审员上最大化 Borda 聚合得分来确定,表达式如下:
dt+1=argc∈{A,B,AB}maxi=1∑n(3−ri(c))其中 ri(c) 是评审员 i 分配给候选方案 c 的排名。当现有方案连续赢得 k=2 次迭代时,系统收敛,从而确保输出的稳定性。
实验
实验在主观写作任务、竞技编程和各种模型层级上评估了 autoreason 方法,以确定结构化迭代改进何时奏效。结果表明,autoreason 有效地弥合了模型的生成能力与评估能力之间的差距,特别是对于中层模型,传统的自我改进往往会导致质量退化或不受控制的冗长。最终,研究得出结论,当任务提供足够的决策空间和限定范围时,该方法的有效性达到最大,这使得锦标赛结构能够通过结构化推理而非仅仅是反应式编辑,从初始失败中恢复。
作者将 autoreason 的变体与基准方法进行了比较,结果显示带有边际要求(margin requirement)的 autoreason 比其他方法获得了更高的 Borda 分数。Critique-and-revise 方法在第一名排名中领先,但 autoreason 变体通过结构化评估展示了更好的整体性能。带有边际要求的 autoreason 获得了比其他方法更高的 Borda 分数;Critique-and-revise 在第一名排名中领先,但 autoreason 变体表现出更好的整体性能;Autoreason 变体在 Borda 评分中优于保守方法和基准方法。
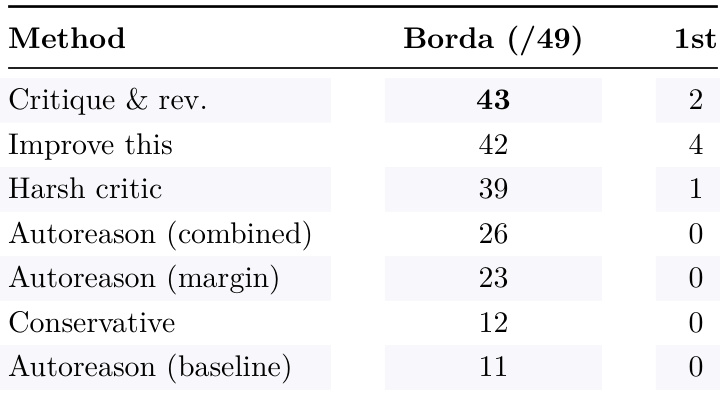
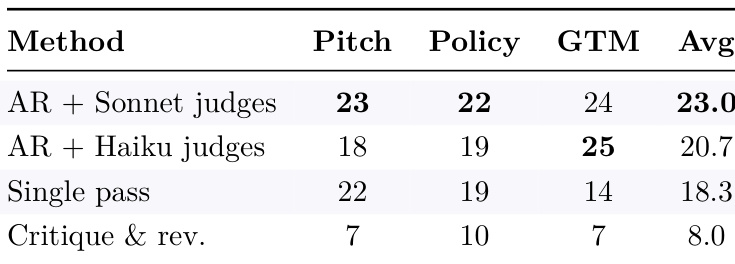
与单次迭代(single-pass)和 critique-and-revise 方法相比,Autoreason 在多个任务中实现了更高的分数。该方法的优势是一致的,在平均性能上比简单的迭代方法有显著提升。Autoreason 在所有任务中均优于 single-pass 和 critique-and-revise 基准;该方法比所有其他方法实现了更高的平均分;Autoreason 在受限任务和开放式任务中均表现出持续的优越性。
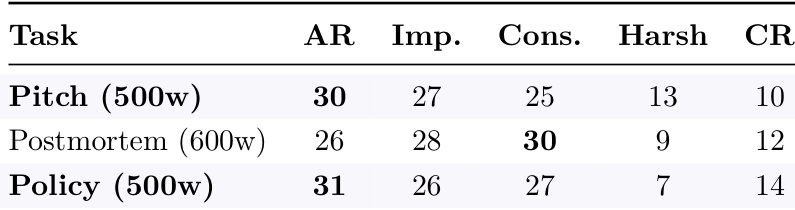
该表比较了 autoreason 与基准方法在受限写作任务上的表现。Autoreason 在三项任务中的两项取得了最高分,而保守基准在 postmortem 任务上表现最好,这表明任务约束会影响哪种方法最有效。Autoreason 在三项受限任务中的两项中优于基准;保守基准在 postmortem 任务中胜出,表明了任务特定的有效性;性能差异突显了任务约束对方法成功的影响。
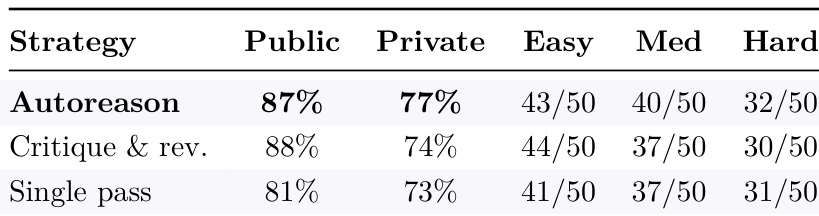
与 critique-and-revise 和 single-pass 策略相比,Autoreason 在私有测试通过率以及中等和困难问题上取得了更高的通过率和更好的表现。该方法在不同难度级别上表现出一致的增益,特别是在没有评估的迭代改进会导致退化的受限领域。Autoreason 在所有问题类型的私有测试通过率中领先;该方法在中等和困难问题上优于 critique-and-revise 和 single-pass 策略;Autoreason 在基准方法发生退化的困难问题上保持了更高的性能。
该表比较了两个任务中不同评审员变体的收敛速度。Chain-of-thought 评审员的收敛速度明显快于基准的整体(holistic)评审员,而分解后的专家(decomposed specialists)在任务 1 上表现出中间水平,但在任务 2 上没有收敛。这表明结构化推理提高了评估效率,但专门的角色并不总是有效的。Chain-of-thought 评审员比基准整体评审员收敛更快;分解后的专家评审员在任务 1 上收敛但在任务 2 上失败;结构化推理提高了收敛速度,但专门的角色可能并不具有普遍有效性。

实验在受限、开放式和不同难度的任务中,将各种 autoreason 变体与 single-pass、critique-and-revise 以及保守基准方法进行了比较。结果表明,autoreason 变体提供了更优的整体性能和一致性,特别是在简单的迭代方法经常退化的困难问题上。虽然通过 chain-of-thought 评审员进行的结构化推理提高了评估的收敛速度,但专门角色的有效性取决于具体的任务需求。