Command Palette
Search for a command to run...
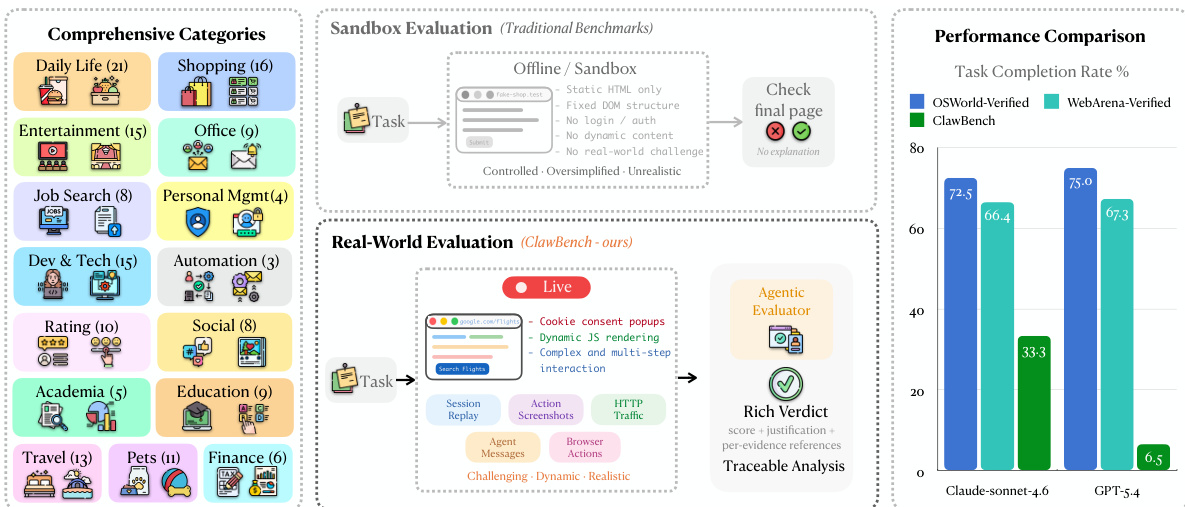
ClawBench:AI Agent 能否完成日常在线任务?
ClawBench:AI Agent 能否完成日常在线任务?
摘要
AI Agent 或许能够实现收件箱的自动化,但它们能否自动化你生活中其他常规的任务呢?日常在线任务为评估下一代 AI Agent 提供了一个真实且尚未解决的测试床(testbed)。为此,我们推出了 ClawBench,这是一个包含 153 项简单任务的评估框架,涵盖了人们在工作和生活中需要定期完成的任务。这些任务横跨 15 个类别、144 个实时平台,从完成购买、预约挂号到提交求职申请,不一而足。这些任务对能力的要求超出了现有 benchmark 的范畴,例如:从用户提供的文档中获取相关信息、在不同平台间进行多步 workflow 导航,以及涉及大量书写操作的任务(如准确填写许多详细的表格)。与现有的在静态页面的离线沙盒中评估 Agent 的 benchmark 不同,ClawBench 直接在生产环境网站上运行,从而保留了真实世界 Web 交互的完整复杂性、动态特性和挑战性。此外,通过一个轻量级的拦截层,系统仅捕捉并拦截最终的提交请求,从而在确保安全评估的同时,避免产生现实世界的副作用。我们对 7 个前沿模型的评估显示,无论是闭源还是开源模型,都只能完成其中极小一部分任务。例如,Claude Sonnet 4.6 的任务完成率仅为 33.3%。ClawBench 的进展使我们向能够作为可靠通用助手的 AI Agent 迈进了一步。
一句话总结
为了评估 AI agent 自动化日常生活和工作活动的能力,研究人员推出了 ClawBench。这是一个包含 144 个真实平台、共 153 个任务的评估框架,它在生产网站上利用轻量级拦截层来保留真实世界的复杂性,结果显示前沿模型在这些动态工作流中表现挣扎,成功率较低,例如 Claude Sonnet 4.6 的成功率仅为 33.3%。
核心贡献
- 本研究引入了 CLAWBENCH,这是一个由 144 个真实平台上的 153 个常规任务组成的评估框架,这些任务需要诸如导航多步工作流和执行写密集型操作等复杂能力。
- 该框架利用轻量级拦截层来捕获并拦截最终的提交请求,从而能够在生产网站上进行安全评估,而不会产生现实世界的副作用。
- 研究人员实现了一个 agentic evaluator,它在 agent 轨迹与人类参考轨迹之间进行步骤级对齐,以提供二元成功判定和结构化的理由说明。
引言
随着 AI agent 向自动化日常生活和工作任务迈进,它们必须应对真实网络环境的复杂性。现有的基准测试通常依赖于简化的合成沙盒或只读任务,无法捕捉诸如填写详细表格或预约挂号等改变状态、写密集型操作的难度。作者引入了 CLAWBENCH,这是一个由 144 个真实生产平台上的 153 个日常任务组成的评估框架。为了在保持生态效度的同时确保安全性,作者利用了一个专门的拦截层来拦截最终的提交请求,允许 agent 与真实网站进行交互而不会产生意外的现实世界后果。该框架提供了一种可扩展、可追溯的方法,用于评估前沿模型处理实际网络的多步工作流和动态特性的能力。
数据集

-
数据集组成与来源:作者引入了 CLAWBENCH,这是一个由分布在 144 个真实生产平台上的 153 个真实世界网络任务组成的基准测试。任务被组织成 8 个高层类别组,并侧重于写密集型操作,例如进行预订、购买或申请,这些操作需要修改服务器端状态。
-
任务详情与过滤:每个任务由自然语言指令、起始 URL 以及 HTTP 请求层级的特定终端提交目标来定义。为了确保质量和可用性,作者应用了多阶段过滤流水线,以移除涉及付费订阅、地理限制服务或已不再活跃的网站的任务。研究人员使用人工标注员来实例化现实的目标,并验证每个任务保持可完成且可复现。
-
数据处理与拦截:一个关键的技术特征是拦截信号的人工标注。人类专家在执行 ground-truth 期间检查浏览器网络流量,以识别不可逆提交的准确 HTTP 端点、方法和 payload schema。这使得框架能够拦截终端请求,确保 agent 可以在完成工作流的同时,不会引起实际金融交易等现实世界的副作用。
-
多层记录与评估:作者使用同步的五层记录基础设施来捕获人类 ground-truth 轨迹和 agent 执行轨迹。这些层包括:
- 通过视频进行的会话录制。
- 每一步操作的截图。
- 完整的 HTTP 流量日志,包括请求体和 payloads。
- agent 消息的结构化 JSON 日志,包括推理链和 tool calls。
- 低层级的浏览器操作,如鼠标坐标和按键。
-
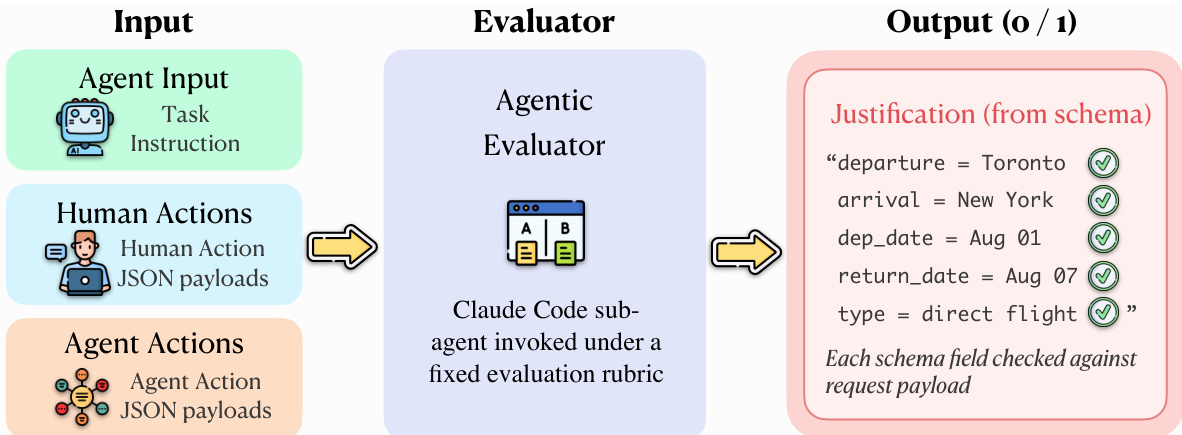
在评估中的使用:该数据集通过将 agent 的完整行为轨迹与人类 ground-truth 参考进行比较来评估 AI agent。一个 Agentic Evaluator 在五个多模态层之间执行步骤级对齐以确定成功与否,从而实现深度的诊断追溯,以准确识别 agent 的推理或操作在何处偏离了人类参考。
方法
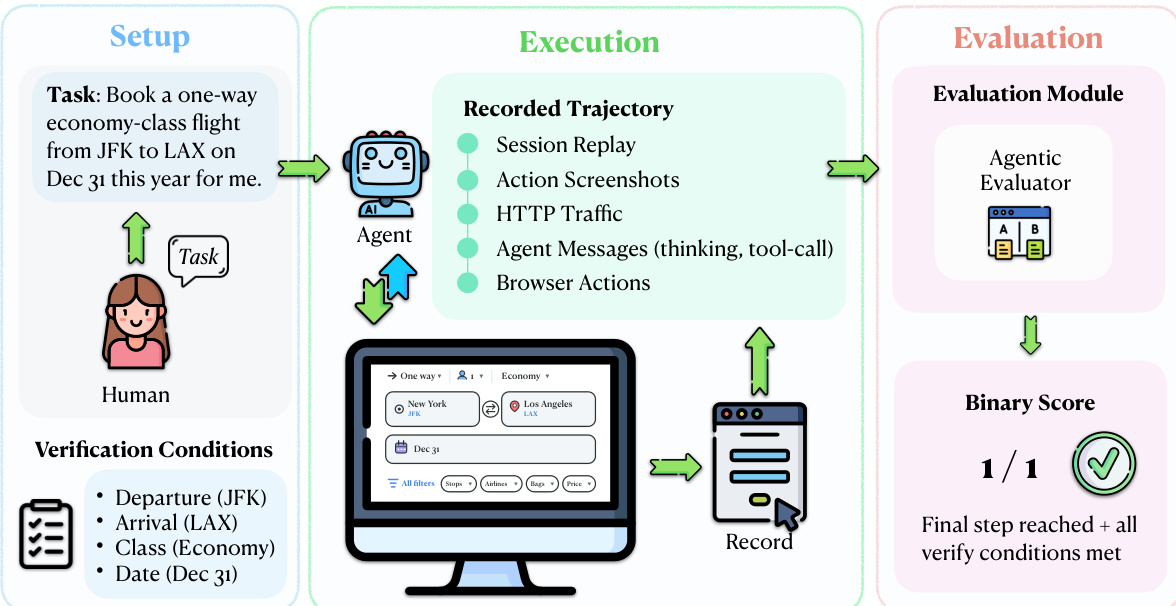
作者利用了一个以 agent 与人类执行之间的多层轨迹比较为核心的真实世界评估框架。该方法的核心是拦截机制,它通过仅捕获任务的最终请求而不允许其到达服务器,从而实现安全且具有生态效度的评估。请参考框架图,它展示了从任务设置到评估的整体流程。该机制通过一个轻量级的 Chrome 扩展程序和一个监控传出 HTTP 请求的 Chrome DevTools Protocol (CDP) 服务器来实现。当 agent 操作触发了与人类标注的 URL 模式和 HTTP 方法匹配的请求时,系统会捕获完整的请求 payload(包括表单字段、headers 和查询参数),拦截该请求使其无法到达服务器,并将其连同时间戳和标签页 URL 一起记录在本地。所有其他请求(如页面加载和动态内容获取)都会原样通过,从而保留 agent 的交互体验。
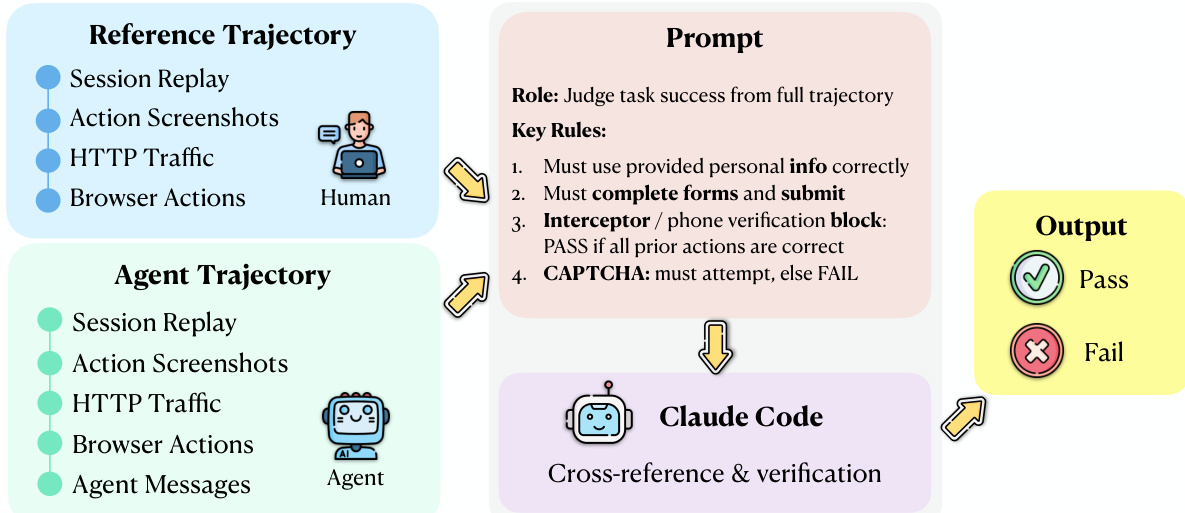
评估协议运行在源自 agent 和人类参考轨迹的五个同步证据流上:会话回放、截图、HTTP 流量、浏览器操作和 agent 消息。如下图所示,评估模块使用一个实现为 Claude Code sub-agent 的 Agentic Evaluator,在 agent 和人类轨迹之间执行显式对齐。该评估器接收任务指令、agent 轨迹和人类参考轨迹作为输入,并应用固定的评估准则来确定任务是否成功。评估过程包括识别对应的步骤、检测差异、验证所需字段和操作是否正确,以及确认 agent 是否达到了与人类参考等效的终端状态。
Agentic Evaluator 为每个任务生成一个二元判定,指示成功或失败。对于任务 t,令 q(t) 表示任务指令,Ta(t) 表示 agent 轨迹,Th(t) 表示人类参考轨迹。评估器 A 将这些输入映射为一个二元任务级判定:Score(t)=A(q(t),Ta(t),Th(t)),,其中 Score(t)∈{0,1},1 表示任务成功完成。任务集 T 的总成功率定义为 SR=∣T∣1∑t∈TScore(t),,其中 ∣T∣ 是被评估的任务数量。这种对比评估设计利用了完整的多层记录,并将成功判定建立在具体的个人演示之上,避免了仅依赖可能存在歧义的任务指令。
Agentic Evaluator 通过在固定评估准则下调用 Claude Code sub-agent 来运行。评估器的输入包括任务指令、人类操作 payloads 和 agent 操作 payloads。评估器将 agent 的执行与人类参考轨迹进行比较,后者由会话回放、操作截图、HTTP 流量和浏览器操作组成。评估过程涉及将 agent 的轨迹与人类参考进行交叉引用,并验证特定条件,例如正确的表单填写和提交。输出是一个带有结构化理由说明的二元分数,指示是否达到了最终步骤并满足了所有验证条件。
评估模块还包含一个验证组件,用于根据人类参考轨迹检查 agent 的操作。评估过程涉及识别对应的步骤、检测差异以及验证所需字段和操作是否正确。Agentic Evaluator 为每个任务生成一个二元判定,指示成功或失败。任务集 T 的总成功率定义为 SR=∣T∣1∑t∈TScore(t),,其中 ∣T∣ 是被评估的任务数量。这种对比评估设计利用了完整的多层记录,并将成功判定建立在具体的个人演示之上,避免了仅依赖可能存在歧义的任务指令。
实验
CLAWBENCH 基准测试通过允许前沿 AI 模型在真实的生产网站而非静态沙盒上运行,来评估它们完成日常在线任务的能力。通过使用 agentic evaluator 将 agent 轨迹与人类 ground-truth 参考进行对比,该研究验证了模型处理动态内容和多步工作流等现实世界复杂性的能力。研究结果表明,即使是最强的模型在这些真实环境中也表现得非常吃力,在不同的生活类别中表现出高度的不一致性,且无法达到它们在传统受控基准测试中的成功率。
作者在 CLAWBENCH 上评估了多个前沿 AI 模型,该基准测试通过在具有现实世界复杂性的真实网站上评估任务完成情况来进行测试。结果显示,与传统的沙盒基准测试相比,模型在 CLAWBENCH 上的表现明显更差,这表明了现实世界网络任务难度的增加。与传统基准测试相比,模型在 CLAWBENCH 上的成功率大幅下降。性能在不同的任务类别之间存在显著差异,没有单一模型能够表现出均衡的优势。最强的模型在 CLAWBENCH 上也仅能完成少数任务,突显了现实世界网络交互的挑战。
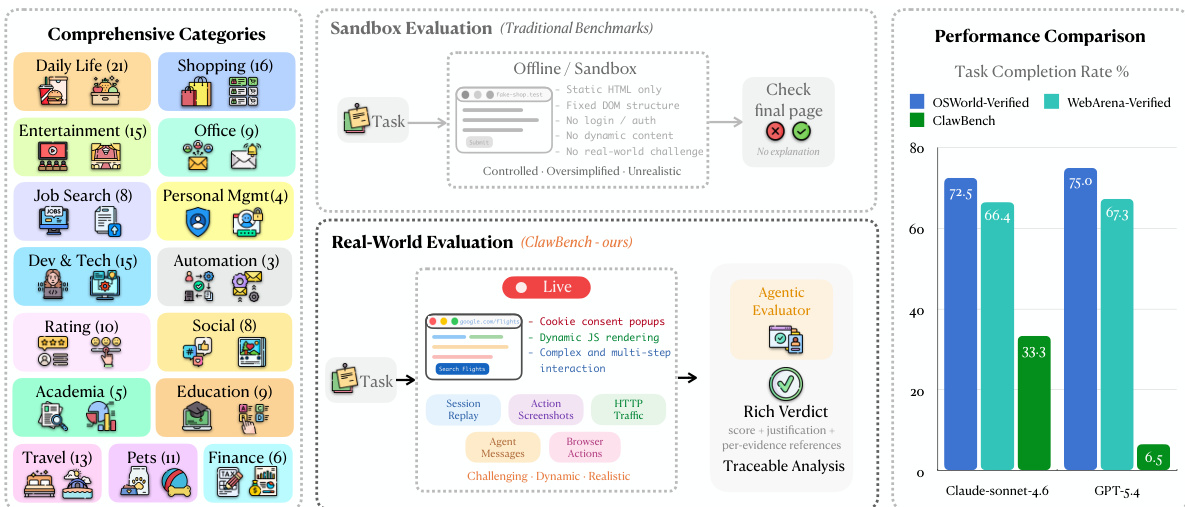
作者提出了 CLAWBENCH,这是一个使用真实环境和多层数据记录系统在现实世界网络任务上评估 AI agent 的基准测试。结果显示,即使是最强的模型也仅实现了较低的成功率,表明在处理日常在线工作流方面存在重大挑战。与使用离线沙盒的现有基准测试不同,CLAWBENCH 在具有现实世界复杂性的真实网站上评估 agent。该基准测试使用多层数据记录系统来捕获详细的 agent 行为,并实现可追溯的评估。即使是表现最好的模型也只有较低的成功率,突显了与传统基准测试相比,现实世界网络任务的难度。
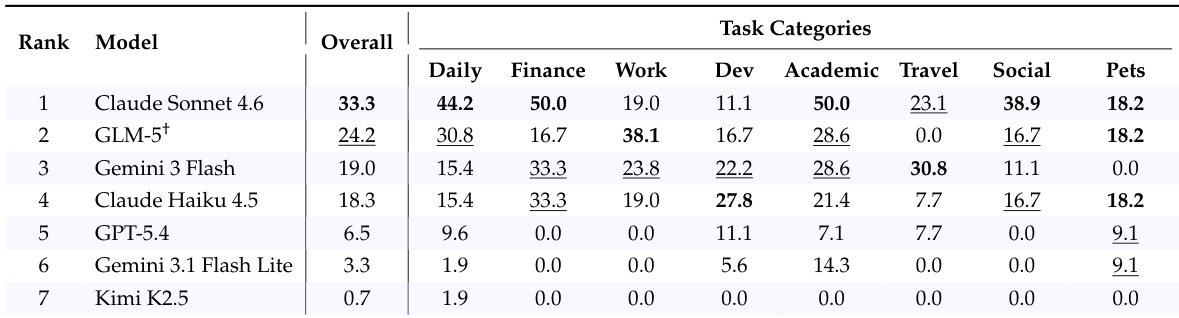
作者在 CLAWBENCH(一个现实世界网络任务基准测试)上评估了七个前沿 AI 模型,并报告了总体成功率和特定类别的成功率。结果显示,最强的模型总体表现仅为中等水平,且在不同任务类别之间存在显著差异,表明在现实世界网络交互中仍面临持续的挑战。顶尖模型在现实世界网络任务上的总体成功率为 33.3%。性能在不同任务类别之间差异很大,没有模型能表现出均衡的优势。即使是表现最好的模型在大多数领域也存在巨大的提升空间。
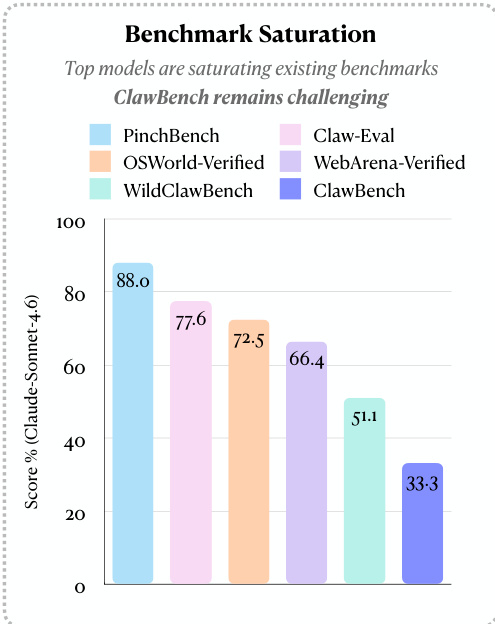
作者比较了模型在不同基准测试中的表现,结果显示顶尖模型在既有基准测试上获得了高分,但在 CLAWBENCH 上得分显著降低。这表明尽管模型在其他平台上有所进步,但 CLAWBENCH 仍然具有挑战性。顶尖模型在既有基准测试上获得高成功率,但在 CLAWBENCH 上成功率要低得多。由于现实世界网络的复杂性,CLAWBENCH 提供了一个更难的评估环境。性能在不同基准测试之间存在差异,对于相同的模型,CLAWBENCH 显示的分数最低。
作者在 CLAWBENCH 基准测试上评估了七个前沿模型,该基准测试在现实世界网络任务上评估 AI agent。结果显示,表现最好的模型成功率为 33.3%,且在不同模型和任务类别之间存在显著差异。Claude Sonnet 4.6 在评估的模型中取得了最高的成功率。性能在不同模型之间差异很大,顶尖模型以显著优势领先于其他模型。模型的优势因任务类别而异,表明在不同领域的能力并不均衡。
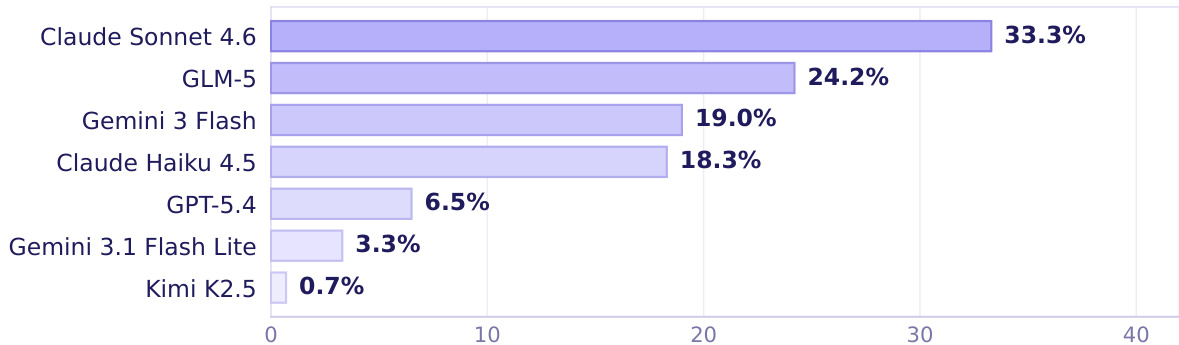
作者使用 CLAWBENCH 评估了多个前沿 AI 模型,该基准测试旨在评估在复杂的真实网络环境而非传统沙盒设置中的任务完成情况。结果表明,目前的模型在处理现实世界网络交互时表现挣扎,在该基准测试上的表现远逊于既有的离线平台。即使是最强的模型在不同任务类别中的成功率也不一致,突显了 AI agent 在处理日常在线工作流能力方面的巨大差距。