Command Palette
Search for a command to run...
ECHO: 基于 One-step Block Diffusion 的高效胸部 X 线报告生成
ECHO: 基于 One-step Block Diffusion 的高效胸部 X 线报告生成
摘要
胸部 X 线报告生成(Chest X-ray report generation, CXR-RG)具有大幅减轻放射科医生工作负担的潜力。然而,传统的自回归视觉-语言模型(Vision-Language Models, VLMs)由于需要进行序列化的 token 解码,面临着推理延迟高的问题。基于 Diffusion 的模型通过并行生成提供了一种极具前景的替代方案,但它们仍需经过多次去噪迭代。虽然将多步去噪压缩为单步可以进一步降低延迟,但由于 token 分解式去噪器(token-factorized denoisers)引入了平均场偏差(mean-field bias),往往会导致文本连贯性下降。为了应对这一挑战,我们提出了 ECHO,一种用于胸部 X 线报告生成的、高效的基于 Diffusion 的 dVLM。通过一种新颖的直接条件蒸馏(Direct Conditional Distillation, DCD)框架,ECHO 实现了稳定的“每块单步”(one-step-per-block)推理;该框架通过从在策略(on-policy)diffusion 轨迹中构建非分解监督信号,来编码 token 之间的联合依赖关系,从而缓解了平均场限制。此外,我们还引入了一种响应非对称扩散(Response-Asymmetric Diffusion, RAD)训练策略,在保持模型有效性的同时进一步提升了训练效率。大量实验表明,ECHO 超越了目前最先进的自回归方法,在 RaTE 和 SemScore 指标上分别提升了 64.33% 和 60.58%,同时在不牺牲临床准确性的前提下,实现了 8 倍的推理加速。
一句话总结
提出的 ECHO 是一种用于胸部 X 线报告生成的、基于 diffusion 的高效视觉语言模型。它利用 Direct Conditional Distillation 框架和 Response-Asymmetric Diffusion 训练策略,实现了稳定的每块单步(one-step-per-block)推理,在 RaTE 提升 64.33%、SemScore 提升 60.58% 并超越最先进的 autoregressive 方法的同时,实现了 8 倍的推理加速。
核心贡献
- 本文介绍了 ECHO,一种专为胸部 X 线报告生成设计的离散 diffusion 视觉语言模型,能够实现稳定的每块单步推理。
- 提出了一种新颖的 Direct Conditional Distillation (DCD) 框架,通过使用来自 on-policy diffusion 轨迹的非分解监督来编码 joint token 依赖关系,从而减轻 mean-field 偏差。
- 研究实施了 Response-Asymmetric Diffusion (RAD) 训练策略和数据归一化范式,以提高训练效率并减少临床幻觉,从而实现了 8 倍的推理加速,并在 RaTE 和 SemScore 指标上取得了显著提升。
引言
自动胸部 X 线报告生成 (CXR-RG) 对于减轻放射科医生的诊断工作量至关重要。虽然 autoregressive 视觉语言模型实现了很高的临床准确性,但由于其顺序解码过程,它们面临着高推理延迟的问题。基于 diffusion 的模型提供了更快的并行生成能力,但由于 token 分解的 denoiser 会引入 mean-field 偏差,它们通常需要多次去噪迭代来保持文本连贯性。作者利用一种新颖的 Direct Conditional Distillation (DCD) 框架来实现稳定的每块单步推理。通过从 on-policy diffusion 轨迹构建非分解监督,ECHO 编码了 joint token 依赖关系以减轻 mean-field 限制,在不牺牲临床准确性的情况下,实现了比最先进的 autoregressive 方法快 8 倍的推理速度。
数据集
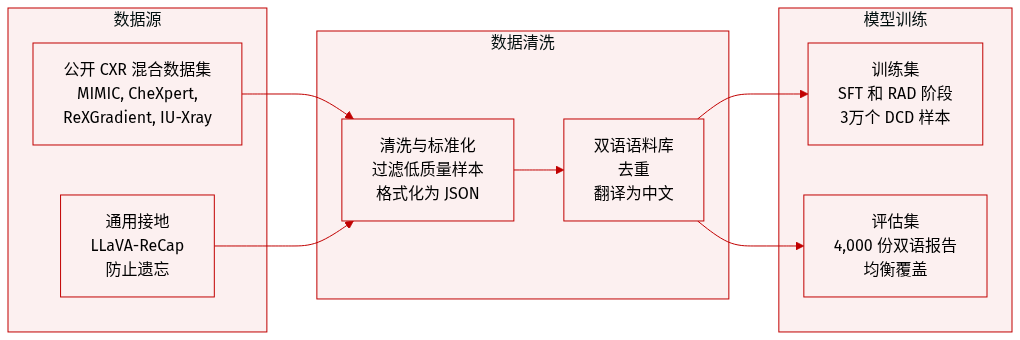
-
数据集组成与来源:作者通过汇总来自四个主要公开来源的数据,构建了一个统一的胸部 X 线 (CXR) 报告语料库:MIMIC-CXR(约 260k 份报告)、CheXpert-Plus(250k 份报告)、ReXGradient(190k 份报告)和 IU-Xray(30k 份报告)。为了防止训练过程中的灾难性遗忘,他们还加入了 LLaVA-ReCap-558K 数据集的一个子集,用于通用的多模态 grounding。
-
数据处理与元数据构建:语料库经过五个阶段的预处理流水线:
- 模态过滤:通过临床实体提取,移除非 CXR 研究和临床描述不完整的样本。
- 标准化:使用基于 prompt 的 BaichuanM2-32B 重写流水线来标准化术语,并在 JSON 中强制执行结构化的 Findings 和 Impression 格式。此过程还通过显式列举所有阴性发现来归一化报告。
- 语义去重:使用 Qwen3-Embedding-8B 和余弦相似度阈值移除近乎重复的数据。
- 双语增强:为了创建双语数据集,作者随机抽取了 50% 的原始报告,并使用 BaichuanM2-32B 将其从英语翻译成中文,并使用特定的 prompt 来保持医学术语和结构。
-
模型训练与评估:
- 训练:作者使用标准化的双语语料库进行监督微调 (SFT) 阶段。对于 Direct Reinforcement Learning (RAD) 阶段,他们使用与 SFT 阶段相同的数据。对于 DCD 阶段,他们从 RAD 训练集中随机抽取 30,000 个样本,确保不同来源数据集的比例代表性。
- 评估:评估集由从归一化的 MIMIC-CXR、CheXpert-Plus 和 ReXGradient 数据集中抽取的 2,000 份英语报告和 2,000 份中文报告组成,以确保语言和来源的均衡覆盖。
方法
ECHO 框架通过一个三阶段训练流水线构建,旨在从 autoregressive 视觉语言模型过渡到能够实现每块单步解码的高吞吐量 block diffusion 模型。整体方法从一个基础模型开始,通过连续的适配来优化性能和推理速度。
训练过程在阶段 1 从使用 Lingshu-7B 模型在精选的胸部 X 线 (CXR) 报告语料库上进行持续预训练 (CPT) 开始。这一阶段产生了 ECHOAR,这是一种专门用于生成放射报告的 autoregressive (AR) 视觉语言模型。后续阶段的主要目标是将此 AR 模型转换为一个既能保留领域知识又能实现更快解码的 block diffusion 模型。在阶段 2,作者提出了 Response-Asymmetric Diffusion (RAD) 适配,将 ECHOAR 转换为 ECHOBase。该方法通过避免冗余复制长 vision token 序列,旨在比之前的两阶段方法更高效。如框架图所示,RAD 仅复制训练序列的 response 部分,并采用 block attention mask,允许每个 noisy response block 注意到所有的 vision 和 instruction tokens 以及之前已解码的 blocks。这种非对称设计显著减少了训练 FLOPs,并将适配整合到了单个监督微调 (SFT) 阶段中。
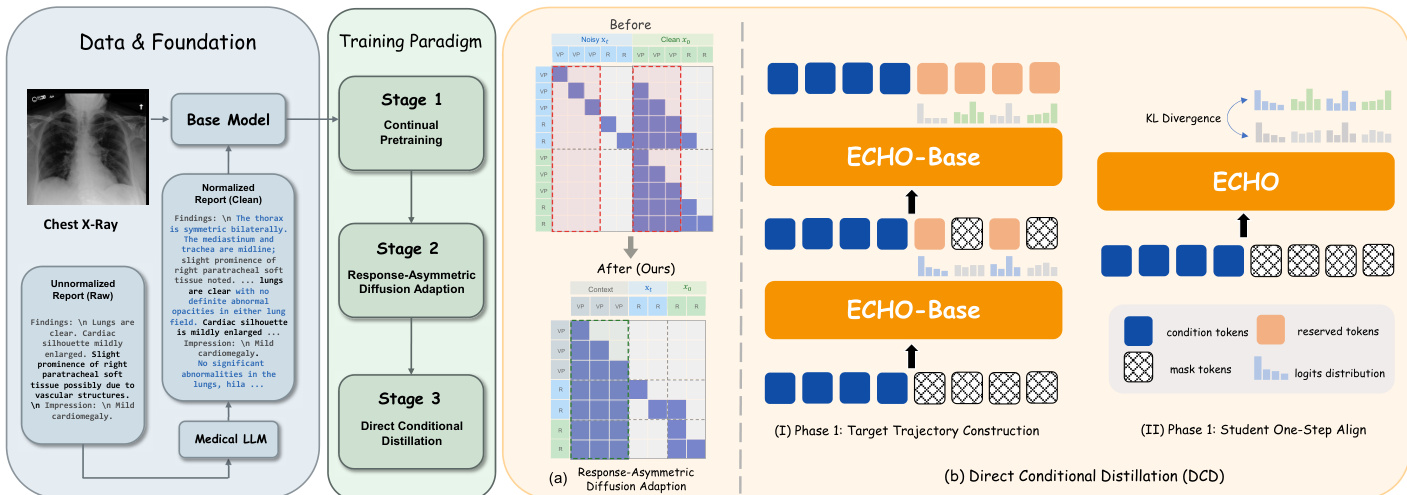
在阶段 3,模型通过 Direct Conditional Distillation (DCD) 进一步优化以实现最大推理吞吐量。目标是将 ECHOBase 转换为一个能够通过单次前向传播生成报告中每个 block 的模型。这需要训练一个学生模型来一步预测整个 block 的 token 分布,因此需要一个非分解的训练目标,以捕捉在教师模型多步去噪过程中积累的 inter-token 依赖关系。DCD 过程由两个迭代阶段组成。在阶段 1 中,从教师模型收集基于置信度启发式的去噪轨迹,其中 tokens 根据其预测置信度被逐步 unmask。该过程中的分布和已确定的 tokens 被用于构建 joint 监督目标。在阶段 2 中,通过最小化学生模型的一步预测与教师模型每个 block 的 joint 分布之间的前向 Kullback-Leibler (KL) 散度,使学生模型与该目标对齐。这种对齐过程通过一种 token 重加权方案得到加强,该方案为去噪过程中较晚被 unmask 的 tokens 分配更高的权重,从而为易受较大 mean-field 偏差影响的位置提供更强的监督。
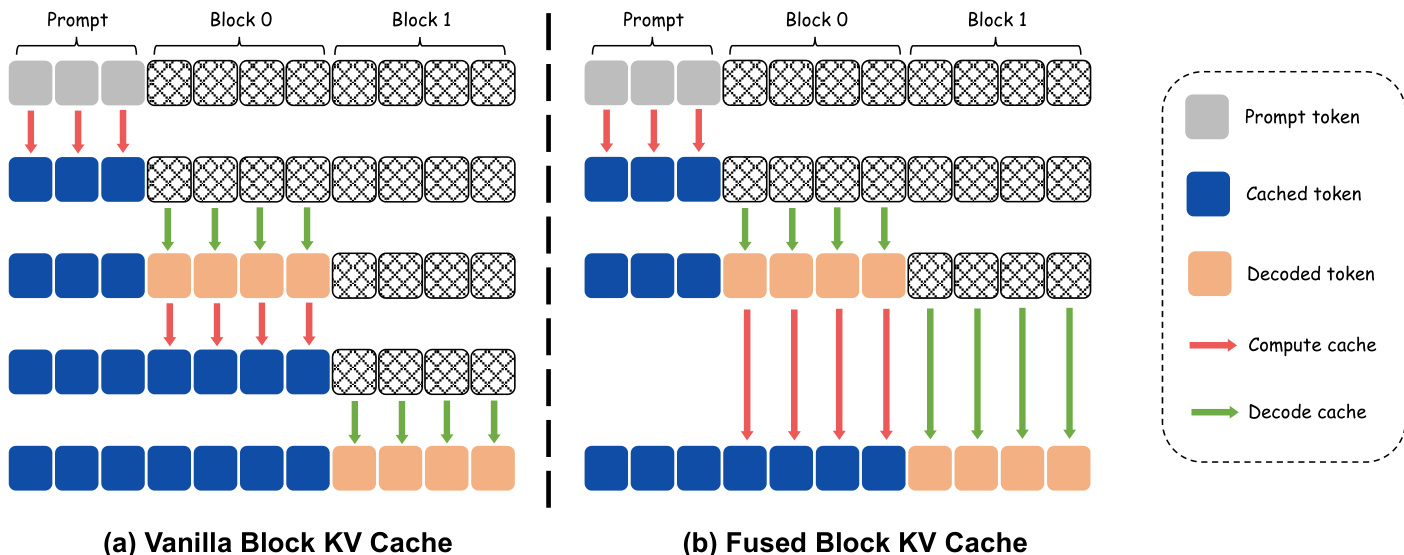
为了进一步最大化推理吞吐量,该框架采用了融合 block key-value (KV) cache 机制。如图所示,标准方法在每个 block 解码后都需要进行专门的前向传播,以更新新生成的 tokens 的 KV cache。对于每块单步模型,这会导致每个 block 需要两次前向传播,使推理成本翻倍。所提出的融合 block KV cache 通过将前一个 block 的 KV 更新直接集成到当前 block 的去噪前向传播中,消除了这一开销。这种融合是通过在单次前向传播中同时处理前一个 block 的已解码 tokens 和当前 block 的 masked tokens 来实现的。模型在对当前 block 的 tokens 进行去噪的同时,同步计算前一个 block 的 key-value 状态,从而无需单独的 KV 更新过程。对于 N 个 response blocks,这一优化将总前向传播次数从 2N 减少到 N,同时保持了原始方法的总 FLOPs,直接降低了推理延迟。

实验
评估将 ECHO 与通用商业模型、autoregressive 医学 VLM 以及基于 diffusion 的 distillation 基线进行了对比,以评估报告质量、临床忠实度和结构稳定性。结果表明,ECHO 在临床准确性和语言流畅性方面始终优于现有的最先进模型,同时通过其 Direct Conditional Distillation 策略提供了更优的质量与速度权衡。此外,消融研究和数据规模分析证实,逐步加权和显式的 end-of-sequence 监督等组件对于减轻生成伪影和确保可靠的临床报告至关重要。
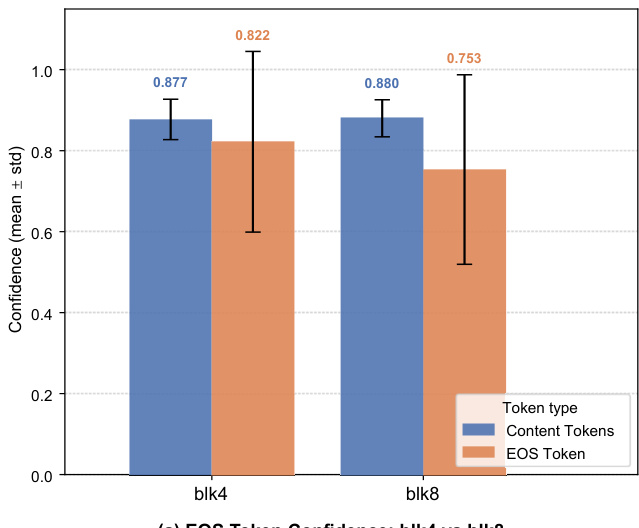
图表比较了两种 block 大小 (blk4 和 blk8) 下 EOS tokens 和内容 tokens 的置信度。结果显示,在两种配置下,内容 tokens 的置信度都高于 EOS tokens,其中 blk4 的差距尤为显著,其内容 token 置信度明显更高。在两种 block 大小中,内容 tokens 的置信度均高于 EOS tokens。内容 tokens 与 EOS tokens 之间的置信度差距在 blk4 中更为明显。与 blk4 相比,blk8 的 EOS token 置信度较低。
作者在语言质量、临床忠实度和结构稳定性指标方面将 ECHO 与最先进的模型进行了比较。结果显示,ECHO 在实现卓越临床准确性的同时,在报告生成中保持了高效率,其表现始终优于通用模型和医学专用模型。与商业、autoregressive 和基于 diffusion 的模型相比,ECHO 在所有指标上均取得了最佳性能。ECHO 在临床忠实度指标上显著优于更大的医学模型。ECHO 展示了良好的速度与质量权衡,具有大幅的解码加速且质量下降极小。
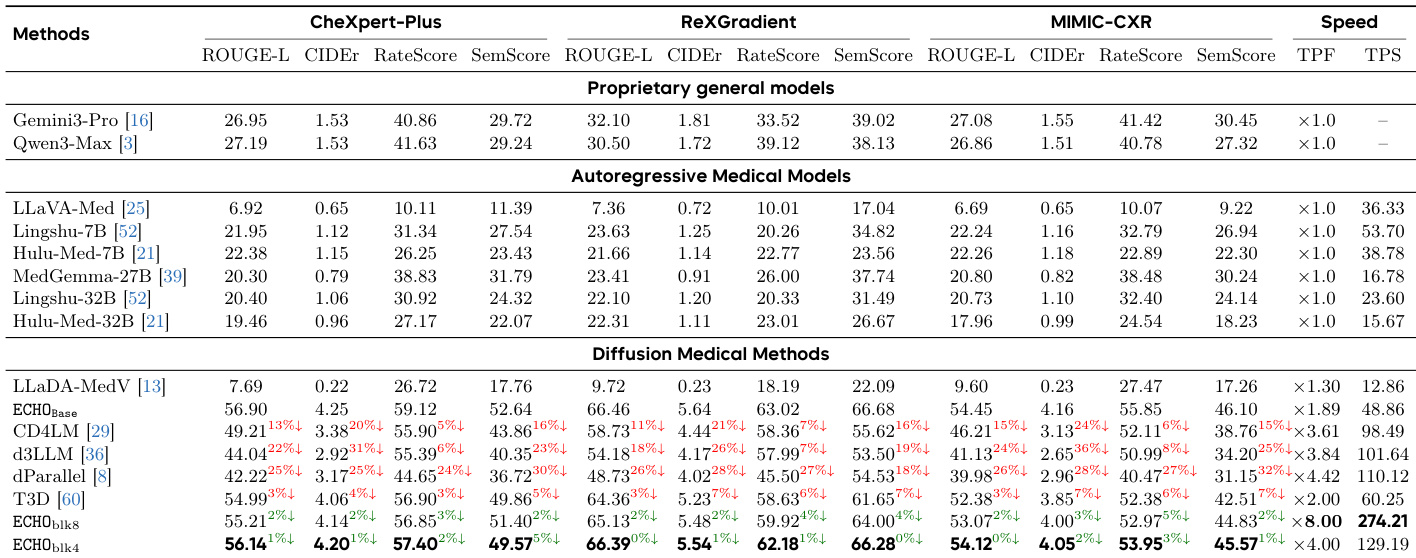
作者在商业、autoregressive 和基于 diffusion 三个类别中,将 ECHO 与各种最先进的模型进行了比较。结果显示,ECHO 在临床忠实度和语言质量方面表现优异,尤其是在英语方面,同时在中文方面也保持了强劲的结果。包括 ECHO 在内的基于 diffusion 的方法在关键指标上表现出与 autoregressive 模型相当或更好的性能。ECHO 在临床忠实度和语言质量指标上优于所有其他模型,尤其是在英语方面。包括 ECHO 在内的基于 diffusion 的模型取得了与 autoregressive 模型相当的结果,其中 ECHO 得分最高。像 Gemini3-Pro 和 Qwen3-Max 这样的商业模型在某些指标上表现良好,但在临床内容准确性和报告流畅性方面被 ECHO 超越。
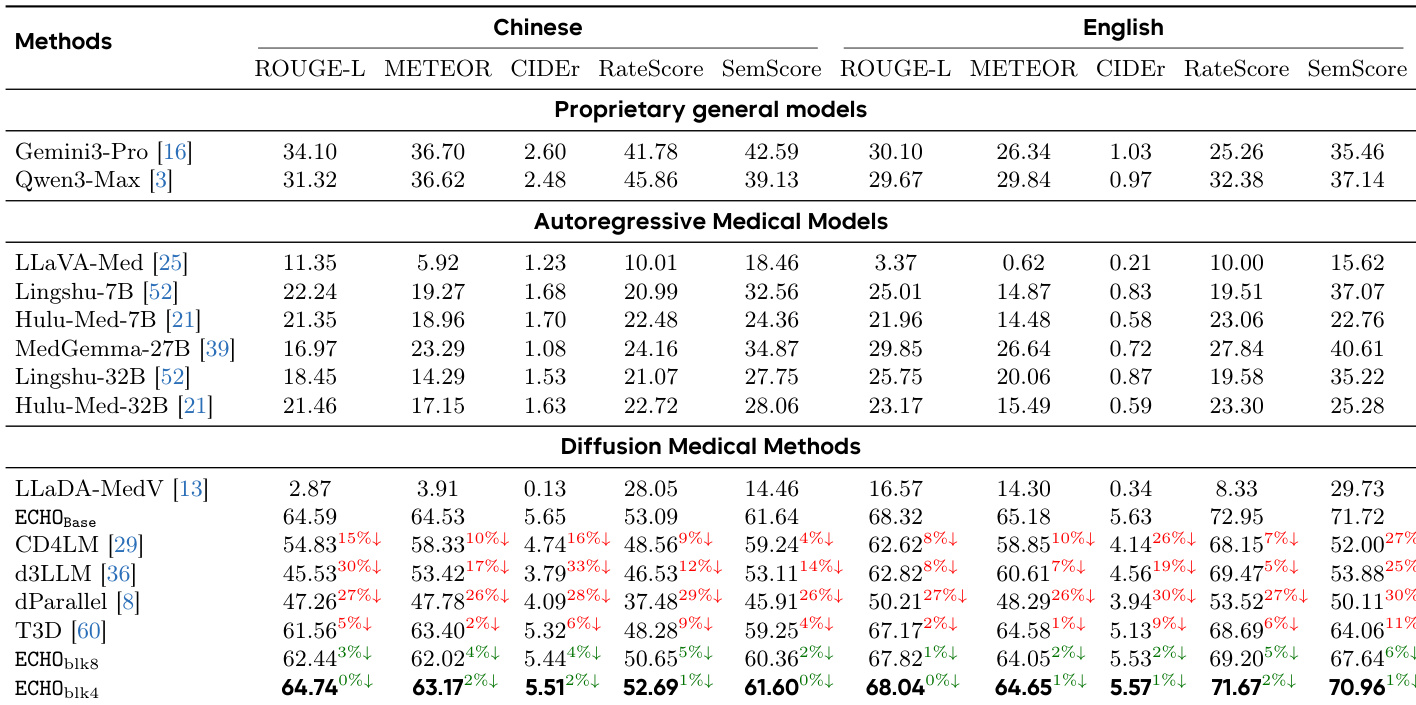
作者在多个数据集上将不同 block 大小的 ECHO 模型与其基础模型进行了比较,显示了在语言和临床指标上的提升。结果表明,ECHO 在所有基准测试中始终优于 ECHO_Base,具有更高的 ROUGE-L、CIDEr 和 SemScore 值,证明了报告质量的增强。与 ECHO_Base 相比,ECHO 模型在所有数据集上都实现了更高的 ROUGE-L、CIDEr 和 SemScore。ECHO 在语言和临床忠实度指标上较 ECHO_Base 均有持续改进。在不同的 block 大小中均观察到了性能增益,表明了 ECHO 方法的鲁棒性。

表格展示了在三个训练阶段中使用归一化报告与非归一化报告的影响。归一化报告在所有指标和阶段中始终带来更高的性能,而非归一化报告会导致性能显著下降,尤其是在临床忠实度指标上。与非归一化报告相比,归一化报告在所有阶段和指标中均产生一致更高的性能。非归一化报告导致临床忠实度指标大幅下降,特别是在阶段 III。随着训练阶段的推进,归一化与非归一化报告之间的性能差距不断扩大。

实验通过 token 置信度分析、与最先进模型的对比基准测试,以及针对 block 大小和报告归一化的消融研究,评估了 ECHO 模型的性能。与商业、autoregressive 和基于 diffusion 的模型相比,ECHO 始终表现出卓越的临床忠实度和语言质量,同时在速度和准确性之间保持了高效的平衡。此外,结果表明,使用归一化报告和优化的 block 大小可以显著增强报告质量,并确保在各种数据集上的稳健性能。