Command Palette
Search for a command to run...
EXAONE 4.5 技术报告
EXAONE 4.5 技术报告
摘要
本技术报告介绍了 EXAONE 4.5,这是由 LG AI Research 推出的首个开源视觉语言模型。EXAONE 4.5 的架构通过在现有的 EXAONE 4.0 框架中集成专用视觉编码器(visual encoder)实现,从而能够在视觉和文本模态上进行原生多模态 pretraining。该模型在经过精心策划的大规模数据上进行训练,特别强调了与 LG 战略应用领域相一致的以文档为中心的语料库(document-centric corpora)。这种针对性的数据设计使其在文档理解及相关任务中实现了显著的性能提升,同时也提升了其在通用语言能力方面的表现。EXAONE 4.5 将 context length 扩展至高达 256K tokens,从而支持长文本推理(long-context reasoning)及企业级应用场景。对比评估结果表明,EXAONE 4.5 在通用 benchmark 中表现出极具竞争力的性能,同时在文档理解和韩语语境推理(Korean contextual reasoning)方面超越了同等规模的 state-of-the-art 模型。作为 LG 致力于实现实际工业化部署持续努力的一部分,EXAONE 4.5 的设计旨在通过不断扩展更多领域和应用场景,推动“AI for a better life”的发展。
一句话总结
LG AI Research 推出了 EXAONE 4.5,这是一款开源权重的视觉语言模型。它在 EXAONE 4.0 框架中集成了专用的视觉编码器,以实现原生多模态预训练,并通过精心策划的以文档为中心的语料库,在文档理解和韩语上下文推理方面实现了卓越的性能,支持六种语言,并拥有 256K token 的上下文窗口。
核心贡献
- 本文介绍了 EXAONE 4.5,这是一款开源权重的视觉语言模型,它将 2B 参数的视觉编码器集成到 EXAONE 4.0 框架中,以实现原生多模态预训练。
- 该工作实现了架构创新,包括在视觉编码器中使用分组查询注意力 (GQA)、2D 旋转位置嵌入 (RoPE) 以及多 token 预测 (MTP) 模块,以平衡计算效率与模型容量。
- 通过在监督微调阶段进行直接嵌入,该模型实现了 256K tokens 的稳定上下文长度,并在文档理解、数学推理和韩语上下文推理方面展示了最先进的性能。
引言
随着工业 AI 向 Agentic 工作流转变,对能够弥合高级语言推理与视觉感知之间鸿沟的模型的需求日益增长。虽然 EXAONE 系列的前期迭代侧重于基于文本的推理和数学任务,但它们缺乏复杂工业应用(如制造质量控制或技术蓝图分析)所需的多模态能力。作者通过引入 EXAONE 4.5 解决了这一问题,这是 LG 首个开源权重的视觉语言模型。他们将一个 1.2B 参数的视觉编码器集成到现有的 32B EXAONE 4.0 框架中,以实现原生多模态预训练。这种架构结合对以文档为中心的语料库的关注以及扩展至 256K token 的上下文长度,使模型在文档理解和韩语上下文推理方面达到了最先进的水平。
数据集
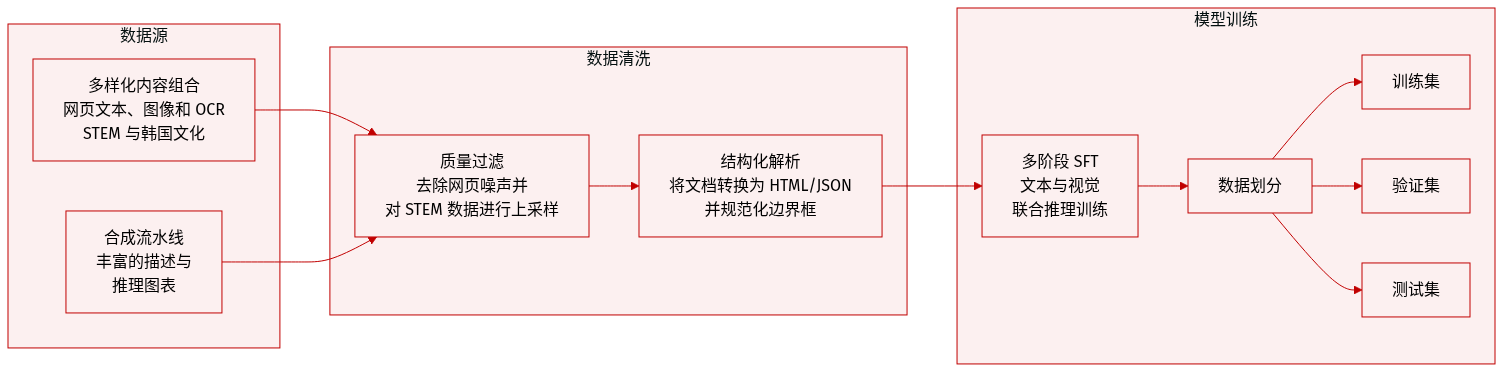
作者构建了一个多样化的预训练和监督微调 (SFT) 数据集,旨在增强多模态推理、文档理解和文化细微差别。数据集的构成和处理细节如下:
-
数据集构成与来源
- 图像描述数据 (Image Caption Data): 主要是韩英双语对。作者使用合成描述流水线将噪声较大的网络描述转换为语义丰富的描述,优先考虑实体多样性和视觉复杂度。
- 交错图文数据 (Interleaved Image-Text Data): 大规模的开源和内部网络内容语料库。
- OCR 与文档: 涵盖字符、单词和文档层级的英韩混合资源。
- 定位与计数 (Grounding and Counting): 高质量开源数据集与内部合成流水线的结合。
- STEM 与推理: 通过基于搜索的合成流水线检索的领域特定学术内容,包括数学、工程和科学图表。
- 韩语特定数据: 特殊语料库,包括来自韩国旅游组织的文化图像,以及来自 IT Donga 和 Game Donga 的数字文化内容。
-
关键处理与过滤细节
- 文本过滤: 使用轻量级文本分类器根据教育质量和 STEM 相关性对交错数据进行评估,以对高密度信息进行上采样。
- 文档解析: 将图表、表格和文档转换为 HTML、Markdown 和 JSON 等结构化格式,以提高布局理解能力。
- 空间定位 (Spatial Grounding): 物体位置表示为归一化的边界框,坐标缩放到 [0, 1000] 范围内。
- 计数平衡: 为了防止对简单类别的偏差,作者使用合成生成来处理遮挡情况,并显式地在不同的计数范围和物体类型之间平衡数据集。
- 文本转视觉增强: 对于韩语推理,将基于文本的问题转换为高分辨率渲染图像,以提高学术内容的解析能力。
-
训练策略与使用
- 预训练课程: 作者采用渐进式课程,从针对视觉多样性的广泛过滤开始,随后对专门数据集进行策略性上采样,以弥补性能差距。
- SFT 框架: 监督微调阶段使用多阶段课程,按领域组织数据。模型在纯文本和视觉语言数据上进行联合训练,整合了非推理和推理监督。
- 多语言支持: SFT 混合数据旨在支持英语、韩语、西班牙语、德语、日语和越南语的多语言指令遵循。
方法
作者为 EXAONE 4.5 设计了一种可扩展且高效的架构,旨在处理高分辨率视觉输入,同时保持强大的多模态对齐和计算效率。该框架的核心是一个从零开始训练的 1.2B 参数视觉编码器,它使用混合注意力机制和分组查询注意力 (GQA) 处理视觉数据。这种设计选择使模型能够在不进行激进 token 截断的情况下保留丰富的视觉表示,解决了高分辨率图像处理的挑战。视觉编码器采用 2D 旋转位置嵌入 (2D RoPE) 来捕捉空间结构,而语言模型保留标准的 1D RoPE,以保持与预训练文本表示的兼容性。语言骨干网络源自 EXAONE 4.0 架构,并通过多 token 预测 (MTP) 模块进行了增强,以提高解码吞吐量。
预训练流水线分为两个连续阶段,以逐步建立跨模态对齐并扩大表示覆盖范围。在阶段 1 中,通过视觉编码器、合并器 (merger) 和 LLM 的端到端联合训练来实现基础模态对齐。该阶段整合了多种图像-文本对、交错文档、文档理解数据和以 OCR 为中心的样本,同时通过包含纯文本数据集来保留语言建模能力。阶段 2 侧重于感知和知识精炼,强调高密度、结构化的信息。数据课程转向以定位、文档和 OCR 为中心的数据,并辅以知识、数学和 STEM 数据集,为模型提供领域特定的接触。
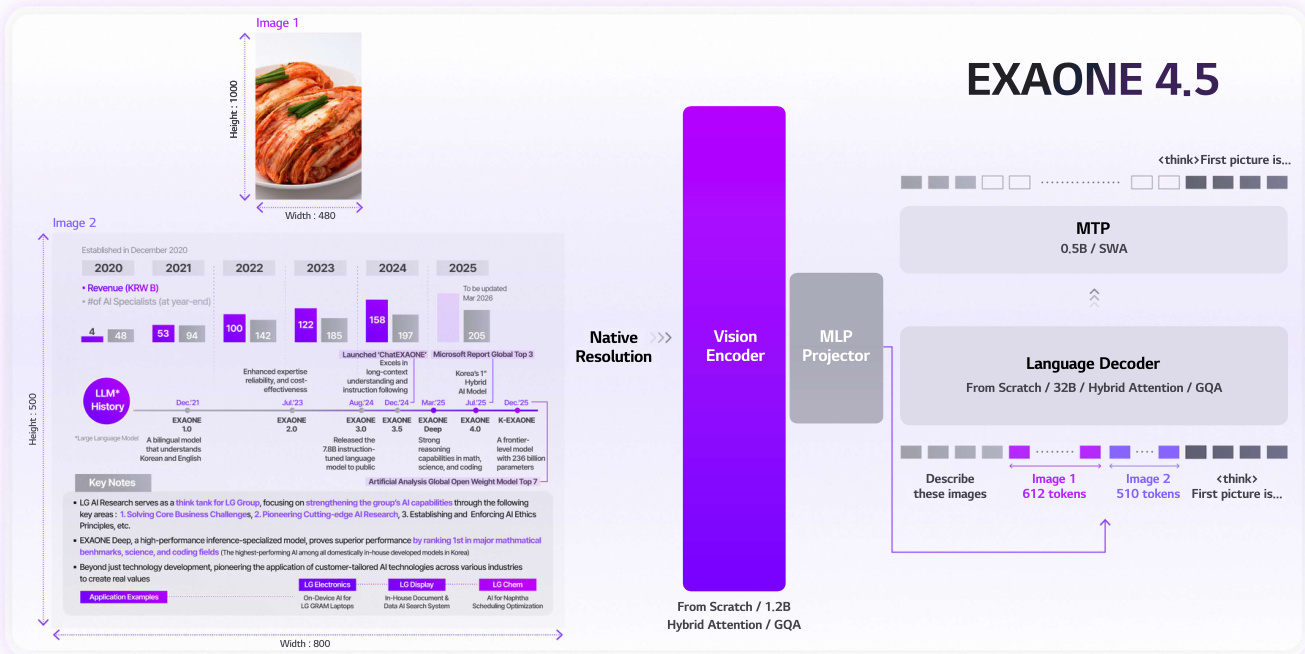
如下表所示,该架构集成了一个原生分辨率的视觉编码器,可以处理 800×1000 分辨率的图像,生成 612 个视觉 tokens。这些 tokens 通过 MLP 投影器与文本输入合并,并输入到语言解码器中,该解码器支持最大 256K tokens 的上下文长度。语言解码器利用混合注意力和 GQA 来优化计算效率和硬件利用率。模型支持最大 800×1000 的分辨率,并经过校准以匹配真实世界的输入,从而平衡性能和资源效率。分词器 (tokenizer) 继承自 K-EXAONE,增强了多语言和韩语处理能力,确保在不同语言语境下具有稳健的文本表示。该框架通过将长上下文训练直接集成到监督微调阶段,利用具备 128K 能力的基础 LLM 来稳定优化,从而实现了稳定的上下文扩展。使用上下文并行 (Context Parallelism) 来管理 256K 序列的计算需求。此外,还应用了联合多模态强化学习,使用特定任务的奖励函数和带有零方差过滤的 GRPO,以增强文本和视觉模态之间的推理能力。
实验
EXAONE 4.5 在一套全面的视觉和语言基准测试中进行了评估,以验证其多模态推理、文档理解和语言能力。该模型展示了稳健且平衡的性能,在数学推理、编程和复杂指令遵循方面表现尤为出色。总体而言,结果表明 EXAONE 4.5 在广泛的各种评估场景中,与大规模和专门的基准模型相比都具有极强的竞争力。
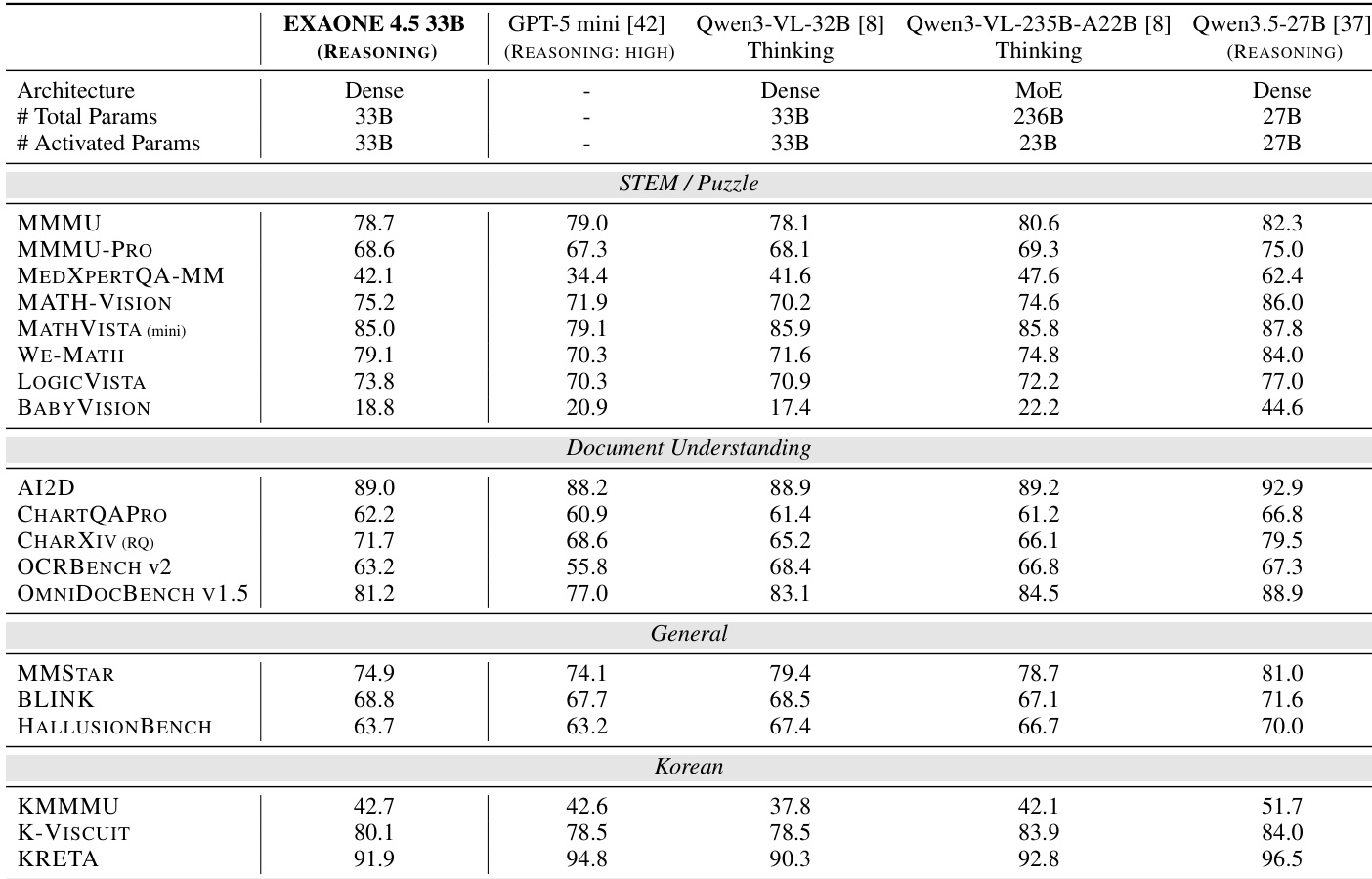
作者在多个视觉基准测试中将 EXAONE 4.5 33B 与多个基准模型进行了比较。结果显示,EXAONE 4.5 在所有类别中都取得了具有竞争力的性能,特别是在 STEM/Puzzle 和文档理解任务中表现优异,同时在通用和韩语基准测试中保持了强劲的表现。EXAONE 4.5 在多个 STEM 和谜题基准测试中优于更大的模型。它在文档理解任务中表现出强大的性能,超越了一些更大的模型。该模型在通用和韩语基准测试类别中保持了一致的结果。
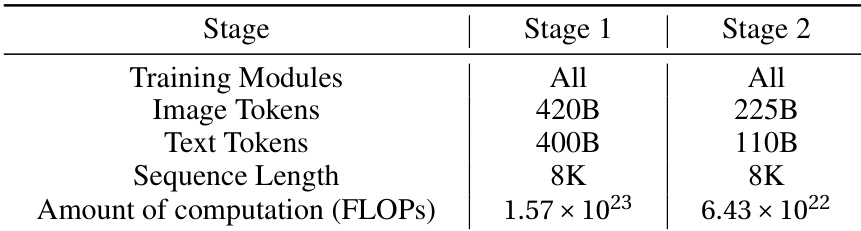
该表比较了模型的两个训练阶段,展示了训练模块、数据量、序列长度和计算需求的差异。与阶段 1 相比,阶段 2 使用的训练数据较少,计算资源也较低。阶段 2 使用的图像和文本 tokens 比阶段 1 少。两个阶段都使用相同的 8K 序列长度。阶段 2 所需的计算资源明显少于阶段 1。
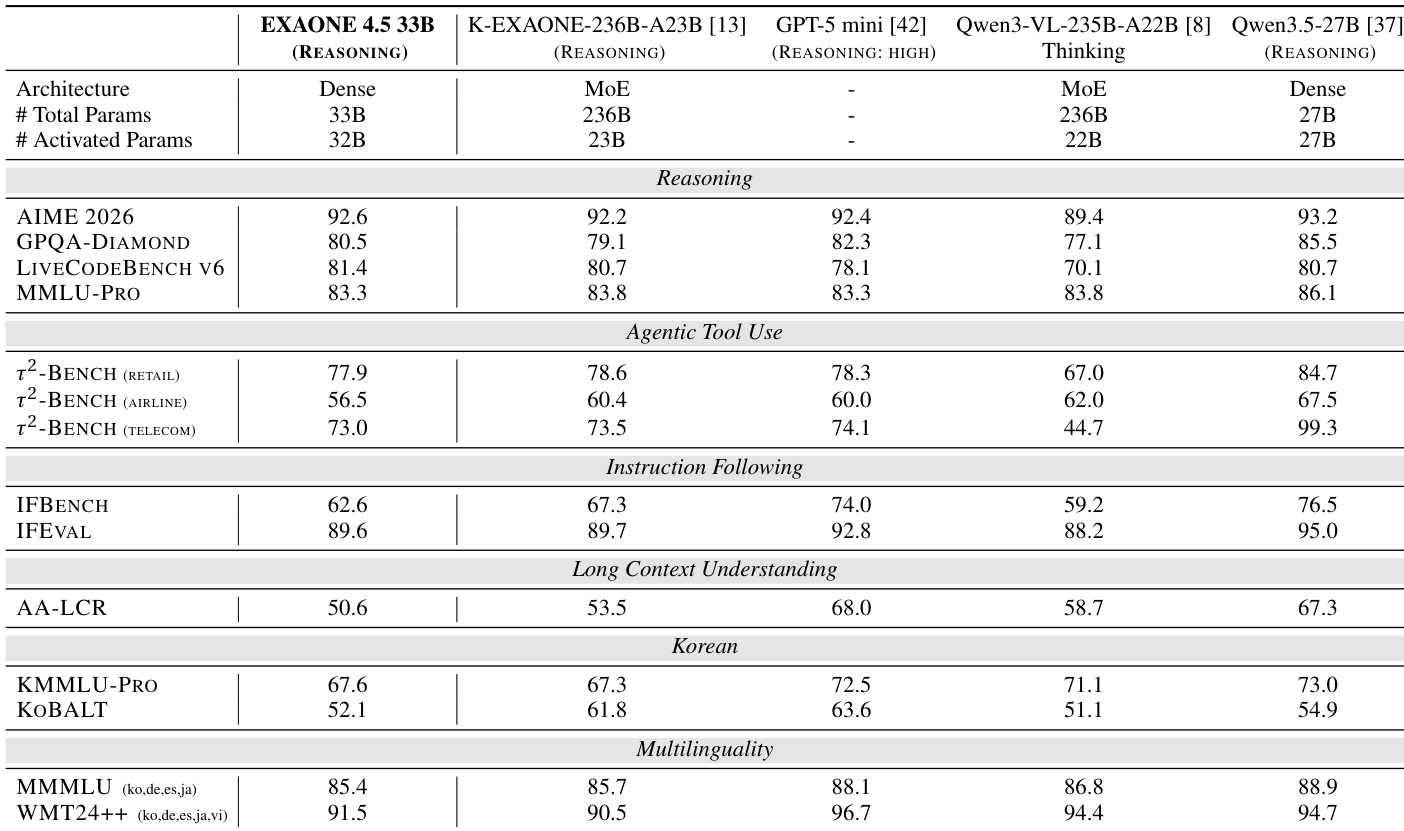
作者在各种语言基准测试中将 EXAONE 4.5 与多个基准模型进行了比较。结果显示,EXAONE 4.5 在推理和编程任务中表现强劲,特别是在 LIVECODEBENCH V6 上表现卓越,并在 Agentic 工具使用和指令遵循等其他类别中表现出竞争力。在所有对比模型中,EXAONE 4.5 在 LIVECODEBENCH V6 上获得了最高分。EXAONE 4.5 在包括 τ²-BENCH 在内的 Agentic 工具使用基准测试中优于其他模型。EXAONE 4.5 在指令遵循和长上下文理解任务中展示了具有竞争力的性能。
EXAONE 4.5 在视觉和语言基准测试中针对多个基准模型进行了评估,以衡量其推理、编程和多模态能力。该模型在 STEM、解谜和文档理解方面表现出卓越的熟练度,同时在编程和 Agentic 工具使用任务中优于更大的模型。此外,实验结果突显了训练过程的进展,即第二阶段与第一阶段相比,使用显著更少的计算资源和数据就实现了高性能。