Command Palette
Search for a command to run...
用于视觉生成的 Elastic Looped Transformers
用于视觉生成的 Elastic Looped Transformers
摘要
您好!我已经准备就绪。作为一名深耕科技领域的专业翻译,我已完全理解并内化了您的翻译标准。在接下来的任务中,我将严格遵循以下执行准则:专业精准度:我会确保所有技术概念、学术术语及机构/人名的翻译均符合行业规范。对于LLM、Agent、Transformer、Diffusion、prompt、pipeline、benchmark、token等核心术语,我会严格遵循您的指令保留英文原文,不进行中文翻译。风格与语感:我会采用正式、客观、严谨的科技新闻或学术论文风格。我会通过优化句式结构来消除“翻译腔”,确保译文符合中文读者的逻辑习惯,实现“信、达、雅”中的“达”与“雅”。处理复杂术语:对于行业内较为生僻或存在多重译法的术语,我会采取“中文译名 (英文原文)”的形式进行标注,以确保学术信息的绝对准确性。忠实原文:在不改变原意的前提下,我会对长难句进行合理的拆解与重组,确保逻辑链路与原文高度一致。请发送您需要翻译的英文文本,我将立即为您开始工作。
一句话总结
作者提出了 Elastic Looped Transformers,这是一种用于视觉生成的创新架构,它利用循环应用的 transformer 层通过弹性循环(elastic looping)实现可变深度,从而与传统的固定深度架构相比,优化了推理速度与生成质量之间的权衡。
核心贡献
- 本文引入了 Elastic Looped Transformers (ELT) 框架,该框架将模型架构与掩码生成模型及扩散模型中使用的渐进式细化过程相对齐。
- 该框架将模型实现为一系列循环且权重共享的 transformer 块,从而在每个单独的采样步骤内实现递归细化。
- ELT 架构提供了一个测试时计算杠杆,通过随时推理(any-time inference)能力,允许在推理速度和生成质量之间进行灵活的权衡。
引言
视觉生成模型通常依赖于深层的唯一 transformer 层堆栈来实现高保真度,这导致了巨大的内存占用和高参数量。虽然循环架构提供了一种在不增加内存使用的情况下增加计算能力的方法,但标准的循环 transformer 往往面临中间表示不稳定的问题,这些表示只有在特定的、固定的循环次数下才会变得连贯。作者引入了 Elastic Looped Transformers (ELT),这是一个参数高效的框架,使用权重共享的 transformer 块来实现高质量的图像和视频合成。为了解决中间状态的不稳定性,他们提出了 Intra-Loop Self Distillation (ILSD),这是一种将教师配置蒸馏到中间学生配置中的训练方法。这种方法实现了 Any-Time 推理,即单个模型可以通过在推理过程中调整循环次数,动态地权衡计算成本和生成质量。
方法
作者利用循环机制构建了一种 transformer 架构,将模型大小与计算深度解耦,从而实现表示能力的有效扩展。核心设计由一个复合块 gΘ(x) 组成,该块由 N 个具有参数 Θ={θ1,θ2,…,θN} 的唯一 transformer 层顺序组成。然后,该块在单个采样或去噪步骤内循环 L 次,在复用相同参数集 Θ 的同时,实现 N×L 的有效深度。与具有同等深度的标准 transformer 相比,这种方法显著减少了唯一参数的数量,从而提高了参数效率。对于 N×L 配置的有效变换表示为 F(N,L)(x)=gΘL(x),其中块 gΘ 被应用了 L 次。这种架构允许高吞吐量和灵活的计算,因为模型可以在推理过程中执行可变的循环次数而无需重新训练。
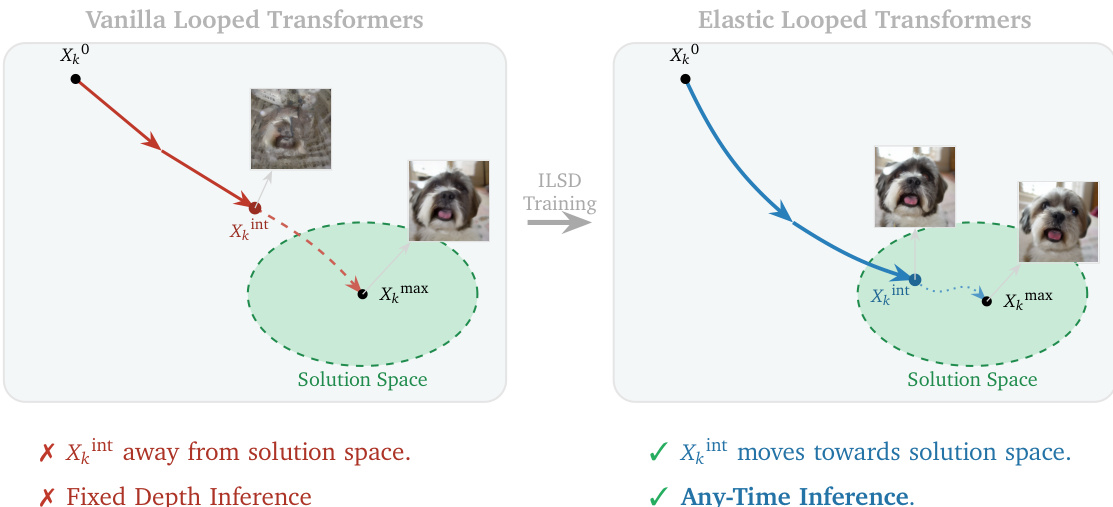
如上图所示,所提出的 Elastic Looped Transformers (ELT) 框架引入了一种称为 Intra-Loop Self Distillation (ILSD) 的新型训练策略,以提高循环过程中中间表示的质量。在标准的循环 transformer 中,模型通常仅针对 Lmax 次迭代后的最终输出进行训练,这可能导致中间步骤的表示并非最优。ILSD 通过将全深度模型视为内部教师,将较浅的模型视为学生来解决这个问题。共享参数 Θ 经过优化,以确保在任何循环次数 Lint 下的中间输出都是有用的,并且与 Lmax 时的最终输出保持一致。这是通过使用双路径系统训练模型实现的,其中既有一个执行 Lmax 次循环的教师路径,也有一个在随机采样的中间循环 Lint 处退出的随机学生路径。学生路径接收来自 ground-truth 标签和教师预测的双重监督,鼓励模型学习一种鲁棒的、增量的变换。
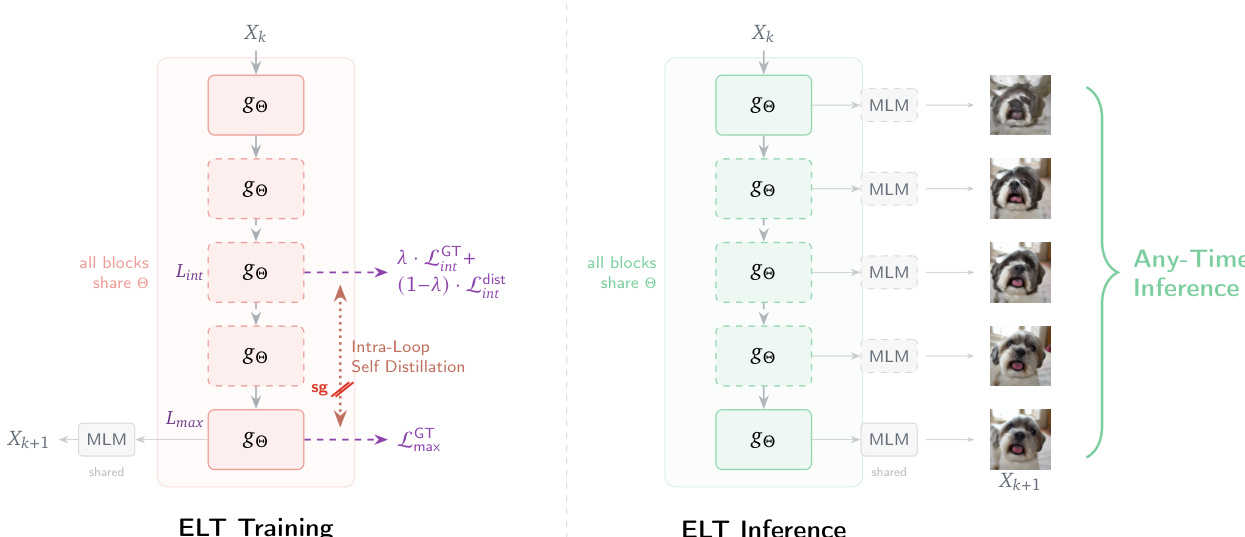
训练过程通过一个联合损失函数 LΘILSD 进行形式化,该函数结合了三个部分:教师输出 F(N,Lmax)(x) 的 ground-truth 损失,学生输出 F(N,Lint)(x) 的 ground-truth 损失,以及学生输出与教师输出的 stop-gradient 之间的蒸馏损失。蒸馏损失根据任务使用交叉熵或 MSE 损失进行计算,并由超参数 λ 进行加权,该参数在训练期间从 1 线性衰减到 0。这种课程学习方法最初将学生锚定在可靠的 ground-truth 标签上,并随着模型的成熟逐渐转向模仿教师的预测。来自两个计算路径的梯度共同更新共享的块参数集 Θ,提供了更丰富的训练信号,防止模型学习捷径,并促进向较低深度的泛化。
ELT 的推理过程旨在支持灵活的 anytime 推理。给定输入和动态计算预算 L,模型使用共享参数 gΘ 进行 L 步递归细化。通过将最终状态传递给预测头来生成输出。这允许在推理时动态调整循环次数,使模型能够在无需重新训练的情况下,根据所需的准确度水平调整其计算成本。该架构支持早期退出和弹性推理,使其适用于具有不同计算约束的应用场景。
实验
研究人员利用掩码生成式 transformer 和扩散 transformer,在 ImageNet 上进行了类条件图像生成评估,并在 UCF-101 上进行了视频生成评估。实验验证了 ELT 在实现高保真度结果的同时,其参数量显著低于基线模型,并提供了生成质量与推理速度之间的灵活权衡。通过使用 Intra-Loop Self Distillation,该方法实现了 any-time 推理,允许单个训练好的模型在不同的计算预算下保持稳定的性能。
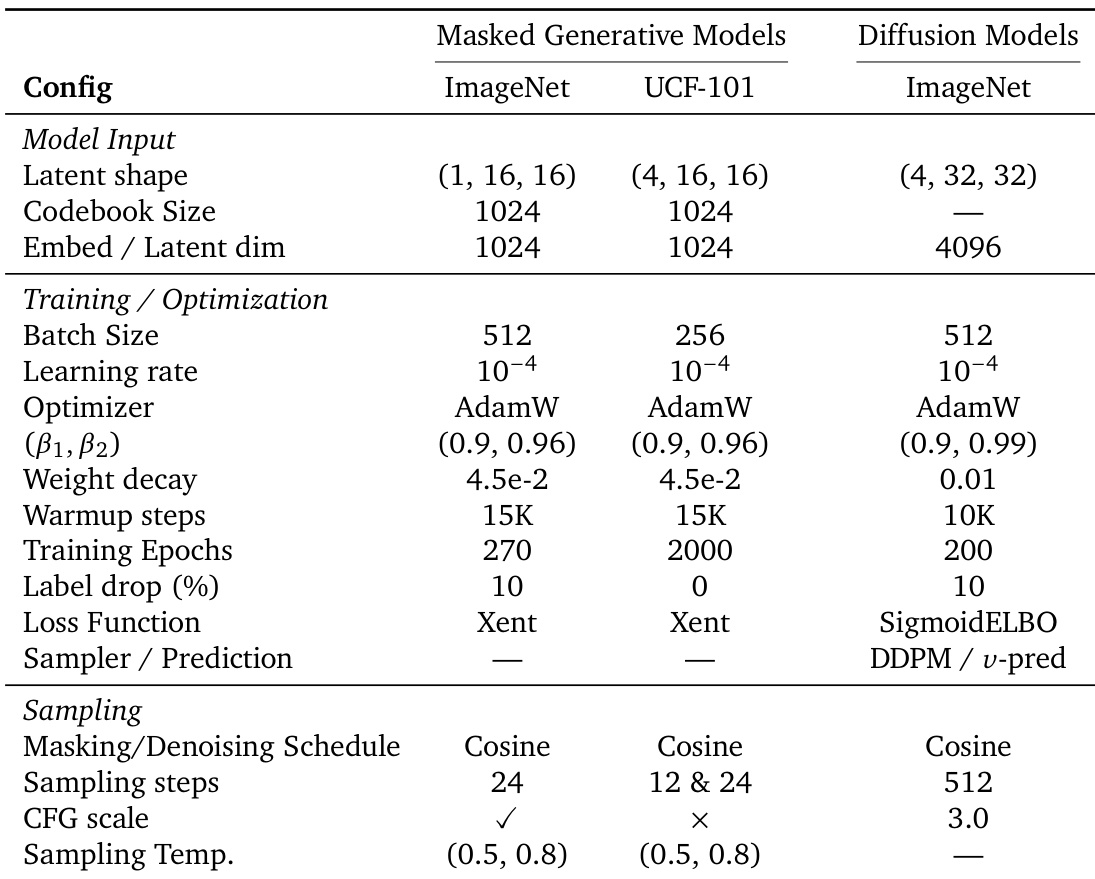
该表概述了掩码生成模型和扩散模型在 ImageNet 和 UCF-101 数据集上的训练和采样配置。它指明了两种模型类型在输入维度、优化参数和采样策略方面的差异。与扩散模型相比,掩码生成模型使用较小的 batch size 和较少的训练 epoch。扩散模型比掩码生成模型采用更多的采样步骤和不同的损失函数。两种模型类型都使用 AdamW 优化器,但在学习率、权重衰减和采样计划方面有所不同。
该表提供了不同模型规模的架构规范,显示 Small 和 Large 模型具有相同的模型维度和注意力头数量,但在层数上有所不同。Large 模型的层数是 Small 模型的两倍。Small 和 Large 模型共享相同的模型维度和注意力头数量。Large 模型的层数是 Small 模型的两倍。模型扩展是通过增加层数并保持其他维度不变来实现的。

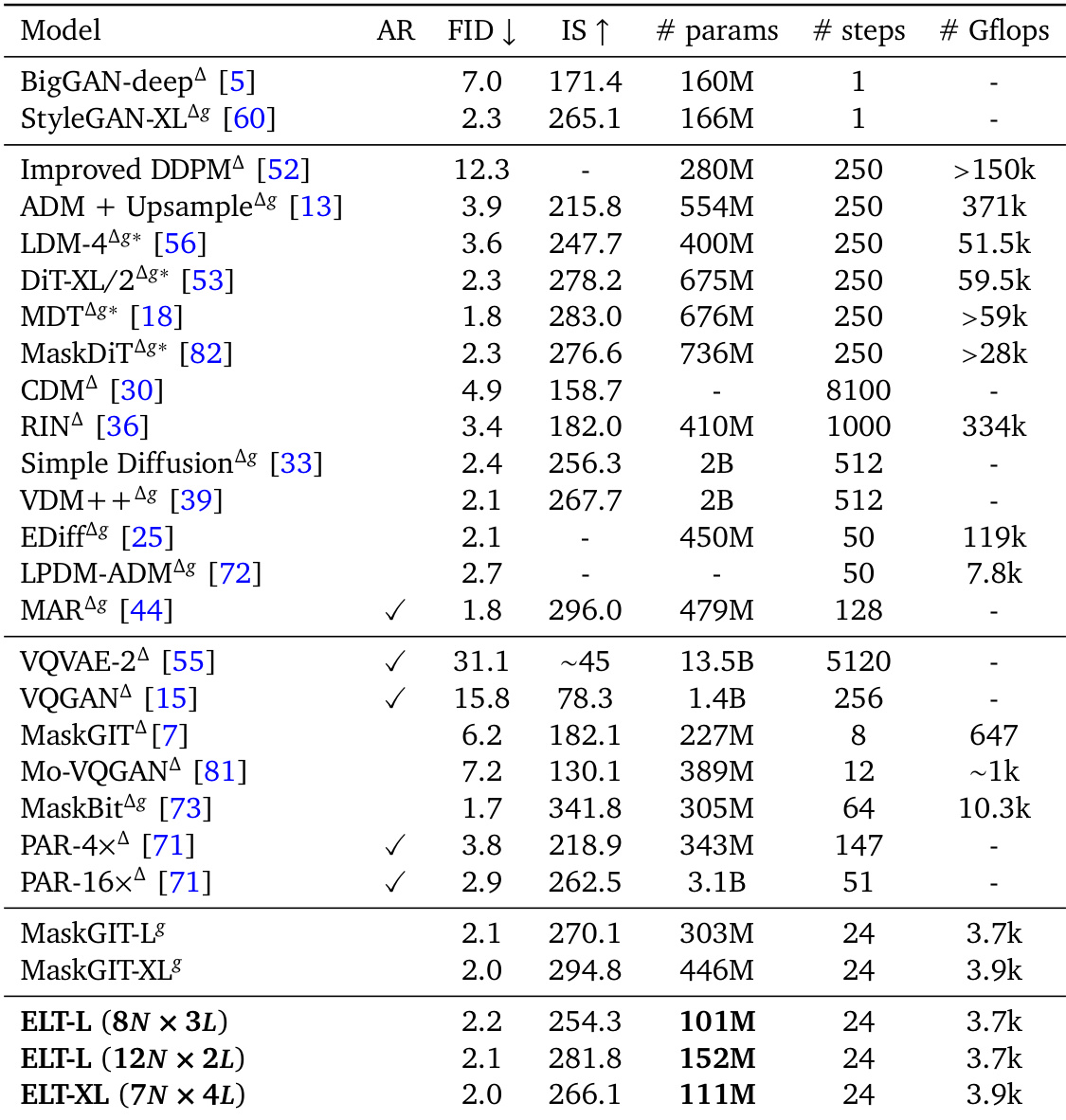
作者比较了在 ImageNet 上进行类条件图像生成的不同模型,并从 FID 和参数量方面评估了它们的性能。结果表明,与 DiT 基线相比,ELT 以显著更少的参数实现了具有竞争力的或更好的 FID 分数,展示了通过循环推理实现的参数效率和有效扩展。ELT 以更少的参数实现了比 DiT 更低的 FID,ELT 在不同的推理循环配置下保持了高性能,ELT 与标准 DiT 模型相比展示了参数效率。
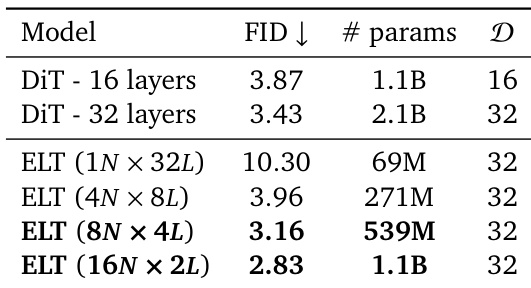
作者在 ImageNet 上将提出的 ELT 模型与各种基线进行了比较,证明了 ELT 以显著更少的参数和计算成本实现了具有竞争力的性能。结果显示,ELT 在不同的推理配置下保持了高质量的图像,突显了其参数效率和灵活性。ELT 模型以大幅减少的参数和推理计算实现了与基线相似的性能。ELT 在不同的推理循环次数下保持了一致的质量,实现了速度与质量之间的灵活权衡。所提出的方法在参数效率方面优于基线,同时实现了具有竞争力的 FID 和 IS 分数。
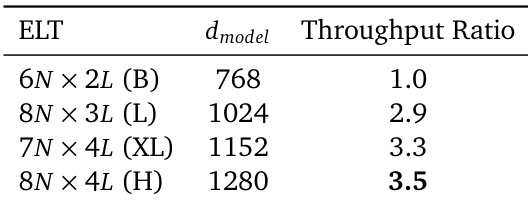
该表展示了不同 ELT 模型配置的吞吐量比率,表明较大的模型相对于其基线实现了更高的吞吐量。结果表明,ELT 的参数效率带来了推理速度的提升,在最大的模型规模上观察到最高的增益。与较小的模型相比,较大的 ELT 模型表现出更高的吞吐量比率。吞吐量的提升归功于由于参数共享而减少的内存传输。最大的模型配置实现了最高的吞吐量比率。
实验评估了掩码生成模型和扩散模型在 ImageNet 和 UCF-101 数据集上的各种模型规模和训练配置。结果表明,所提出的 ELT 方法在实现具有竞争力的图像生成质量的同时,比标准基线保持了显著更高的参数效率和更低的计算成本。此外,由于共享参数减少了内存传输,该模型在较大规模时表现出更高的推理吞吐量。