HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

生成式人工智能通过对称扩散学习实现基于功能磁共振成像的脑结构网络构建

面向边缘智能的早期退出预测编码神经网络



























生成式人工智能通过对称扩散学习实现基于功能磁共振成像的脑结构网络构建
面向边缘智能的早期退出预测编码神经网络
二次梯度:一种通过综合 Hessian 矩阵与梯度来桥接梯度下降法与牛顿类方法的统一框架
乘积广播信道类的容量区域
Colon-Bench:一种用于全周期结肠镜视频中可扩展致密病灶标注的智能体工作流
TOOLACE:在 LLM 函数调用中胜出
LightMover:具备颜色与强度控制的生成式光照运动
基于强化学习与对手位姿估计的自主超车轨迹优化
Make It Up:合成图像在广义少样本语义分割中的真实收益
面向基于 LLM 的多说话人语音识别的基于门控交叉注意力适配器的两阶段声学自适应方法
手术人工智能比较研究:数据集、基础模型与医疗通用人工智能的障碍
文本数据集成
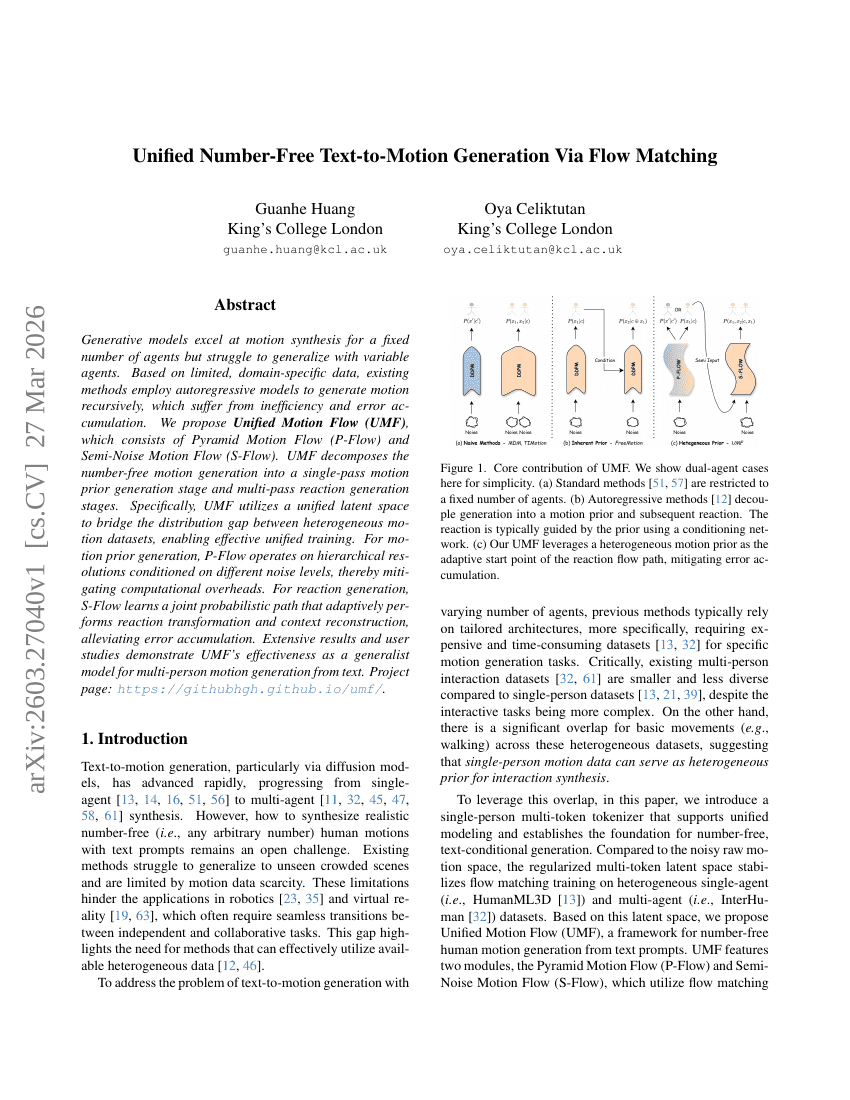
基于流匹配的无数字统一文本到动作生成
SEAR:基于模式的 LLM 网关评估与路由
面向扩散 Transformer 中丰富多样性的上下文空间即时排斥机制
EpochX:构建涌现智能体文明的基础设施
TAPS:面向推测采样的任务感知提议分布
具有推理轨迹的长尾驾驶场景:KITScenes 长尾数据集
RealChart2Code:基于真实数据与多任务评估推进图表到代码生成研究
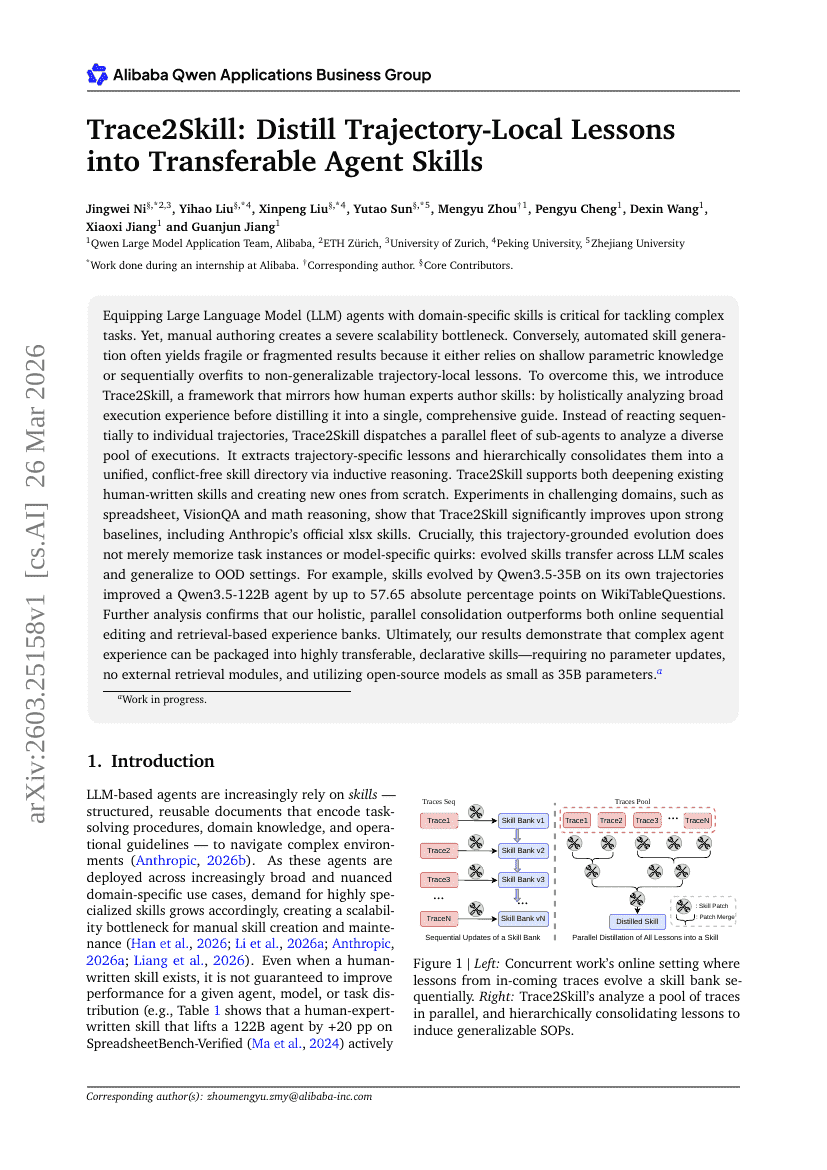
Trace2Skill:将轨迹局部经验蒸馏为可迁移的 Agent 技能
PackForcing:短视频训练足以支持长视频采样与长上下文推理
ShotStream:面向交互式叙事的流式多镜头视频生成
视而不见,心却不忘:面向动态视频世界模型的混合记忆机制
BeSafe-Bench:揭示功能性环境中 Situated Agents 的行为安全风险
世界推理竞技场
MSA:面向高效端到端记忆模型扩展至 1 亿 tokens 的稀疏记忆注意力机制
Voxtral TTS
RealRestorer:面向基于大规模图像编辑模型的通用真实世界图像复原
Calibri:通过参数高效校准增强 Diffusion Transformer
Intern-S1-Pro:万亿级科学多模态基础模型
PixelSmile:迈向细粒度面部表情编辑
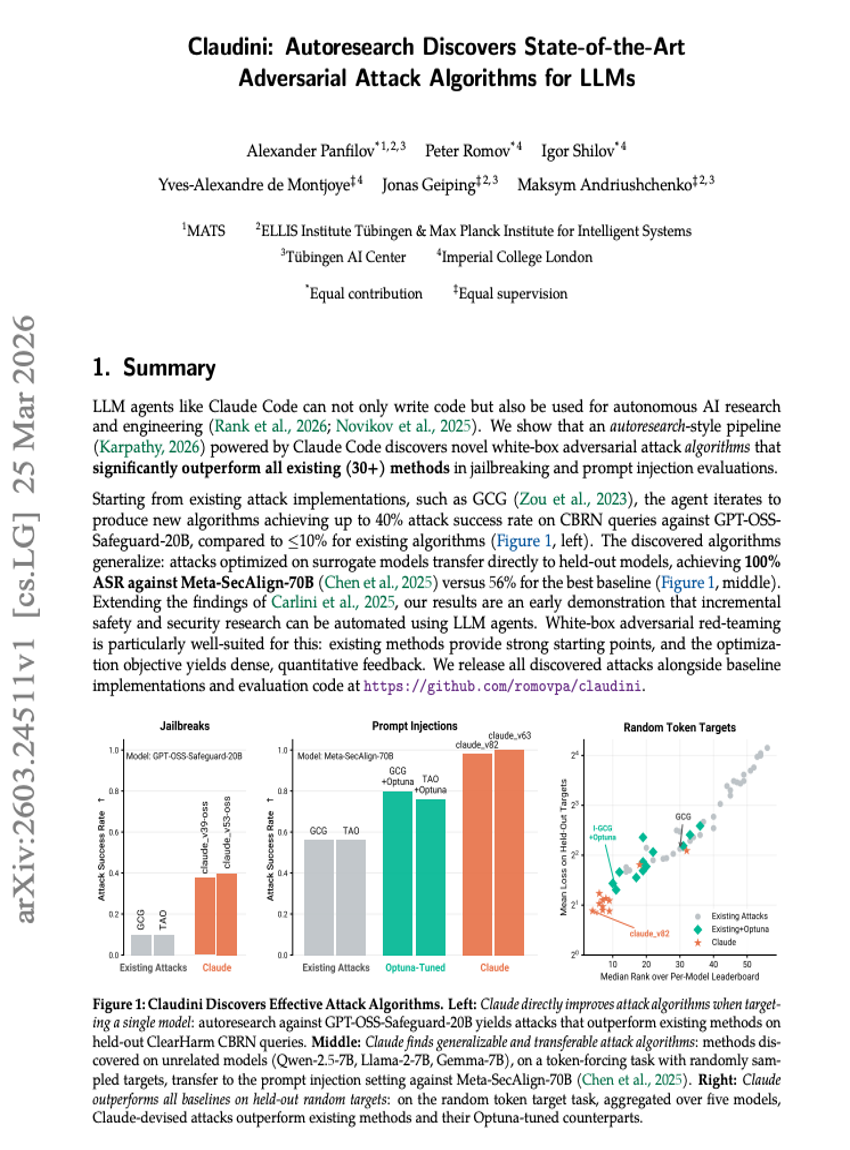
Claudini: Autoresearch 发现适用于 LLMs 的最先进(State-of-the-Art)对抗攻击算法
二次梯度:一种通过综合 Hessian 矩阵与梯度来桥接梯度下降法与牛顿类方法的统一框架
乘积广播信道类的容量区域
Colon-Bench:一种用于全周期结肠镜视频中可扩展致密病灶标注的智能体工作流
TOOLACE:在 LLM 函数调用中胜出
LightMover:具备颜色与强度控制的生成式光照运动
基于强化学习与对手位姿估计的自主超车轨迹优化
Make It Up:合成图像在广义少样本语义分割中的真实收益
面向基于 LLM 的多说话人语音识别的基于门控交叉注意力适配器的两阶段声学自适应方法
手术人工智能比较研究:数据集、基础模型与医疗通用人工智能的障碍
文本数据集成
基于流匹配的无数字统一文本到动作生成
SEAR:基于模式的 LLM 网关评估与路由
面向扩散 Transformer 中丰富多样性的上下文空间即时排斥机制
EpochX:构建涌现智能体文明的基础设施
TAPS:面向推测采样的任务感知提议分布
具有推理轨迹的长尾驾驶场景:KITScenes 长尾数据集
RealChart2Code:基于真实数据与多任务评估推进图表到代码生成研究
Trace2Skill:将轨迹局部经验蒸馏为可迁移的 Agent 技能
PackForcing:短视频训练足以支持长视频采样与长上下文推理
ShotStream:面向交互式叙事的流式多镜头视频生成
视而不见,心却不忘:面向动态视频世界模型的混合记忆机制
BeSafe-Bench:揭示功能性环境中 Situated Agents 的行为安全风险
世界推理竞技场
MSA:面向高效端到端记忆模型扩展至 1 亿 tokens 的稀疏记忆注意力机制
Voxtral TTS
RealRestorer:面向基于大规模图像编辑模型的通用真实世界图像复原
Calibri:通过参数高效校准增强 Diffusion Transformer
Intern-S1-Pro:万亿级科学多模态基础模型
PixelSmile:迈向细粒度面部表情编辑
Claudini: Autoresearch 发现适用于 LLMs 的最先进(State-of-the-Art)对抗攻击算法