Command Palette
Search for a command to run...
WildDet3D: 在野外环境下扩展 Promptable 3D Detection
WildDet3D: 在野外环境下扩展 Promptable 3D Detection
摘要
从单张图像中理解 3D 物体是空间智能(spatial intelligence)的基石。实现这一目标的关键步骤是单目 3D 物体检测——即从输入的 RGB 图像中恢复物体的范围、位置和朝向。为了在开放世界中具备实用性,此类检测器必须能够超越闭集类别的限制进行泛化,支持多样化的 prompt 模态,并在可用时利用几何线索。然而,目前的研究进展受到了两个瓶颈的阻碍:首先,现有方法多针对单一的 prompt 类型设计,且缺乏整合额外几何线索的机制;其次,目前的 3D 数据集仅涵盖受控环境下的狭窄类别,限制了其在开放世界中的迁移能力。在本文中,我们针对这两个缺陷提出了解决方案。首先,我们引入了 WildDet3D,这是一种统一的几何感知架构,能够原生支持 text、point 和 box prompt,并可以在 inference 阶段整合辅助的深度信号。其次,我们推出了 WildDet3D-Data,这是迄今为止规模最大的开放 3D 检测数据集。该数据集通过从现有的 2D 标注中生成候选 3D box,并仅保留经人工验证的部分构建而成,涵盖了多样化真实场景中的 1.35 万个类别,包含超过 100 万张图像。WildDet3D 在多个 benchmark 和设置下均刷新了最先进的水平(SOTA)。在开放世界设置下,在使用 text 和 box prompt 时,它在我们新推出的 WildDet3D-Bench 上分别达到了 22.6/24.8 的 AP3D。在 Omni3D 数据集上,它在使用 text 和 box prompt 时分别达到了 34.2/36.4 的 AP3D。在 zero-shot 评估中,它在 Argoverse 2 和 ScanNet 上分别实现了 40.3/48.9 的 ODS。值得注意的是,在 inference 阶段引入深度线索可带来显著的额外增益(在不同设置下的平均提升达 +20.7 AP)。
一句话总结
为了实现可扩展的开放世界单目 3D 物体检测,作者推出了 WildDet3D,这是一种统一的几何感知架构,支持文本、点和框 prompt,同时结合了辅助深度信号;此外还推出了 WildDet3D-Data,这是一个包含超过 1M 张图像、涵盖 13.5K 个类别的数据集,使模型能够在多个基准测试中达到新的 SOTA 水平。
核心贡献
- 本文引入了 WildDet3D,一种统一的几何感知架构,通过专门的深度融合模块支持文本、点和框 prompt,并结合了辅助深度信号。
- 本研究提出了 WildDet3D-Data,这是一个大规模数据集,包含超过 1M 张图像和 13.5K 个类别,通过多模型候选生成流水线结合人工和 VLM 验证构建而成。
- 实验结果表明,WildDet3D 在 Omni3D 基准测试上达到了 SOTA 性能,并在 Argoverse 2 和 ScanNet 等多样化数据集上展现出强大的 zero-shot 泛化能力。
引言
单目 3D 物体检测对于机器人、AR/VR 和移动设备等应用中的空间智能至关重要。然而,现有方法通常局限于闭集类别和固定的交互模式,通常仅支持单一类型的 prompt。此外,目前的 3D 数据集往往受限于狭窄的类别和受控环境,这阻碍了开放世界的泛化。作者通过引入 WildDet3D 来应对这些挑战,这是一种统一的几何感知架构,能够原生接受文本、点和框 prompt,同时允许在推理时集成辅助深度信号。为了支持该模型,他们还提出了 WildDet3D-Data,这是一个包含超过 100 万张经过人工验证的图像、涵盖 13.5K 个类别的海量数据集,旨在实现鲁棒的开放词汇 3D 感知。
数据集

WildDet3D-Data 概览
作者推出了 WildDet3D-Data,这是一个专为多样化真实世界环境中的开放词汇 3D 检测设计的大规模数据集。它具有超过 1M 张图像、3.7M 个有效的 3D 标注和 13.5K 个物体类别,与 Omni3D 等现有数据集相比,类别覆盖范围增加了 138 倍。
数据集组成与来源 该数据集基于来自四个主要大规模来源的密集 2D 标注构建:
- COCO: 118K 训练图像和 5K 验证图像。
- LVIS: 具有长尾标注的 COCO 图像,覆盖超过 1,200 个类别。
- Objects365: 涵盖 365 个类别的 609K 训练图像和 30K 验证图像。
- V3Det: 183K 训练图像和 30K 验证图像。
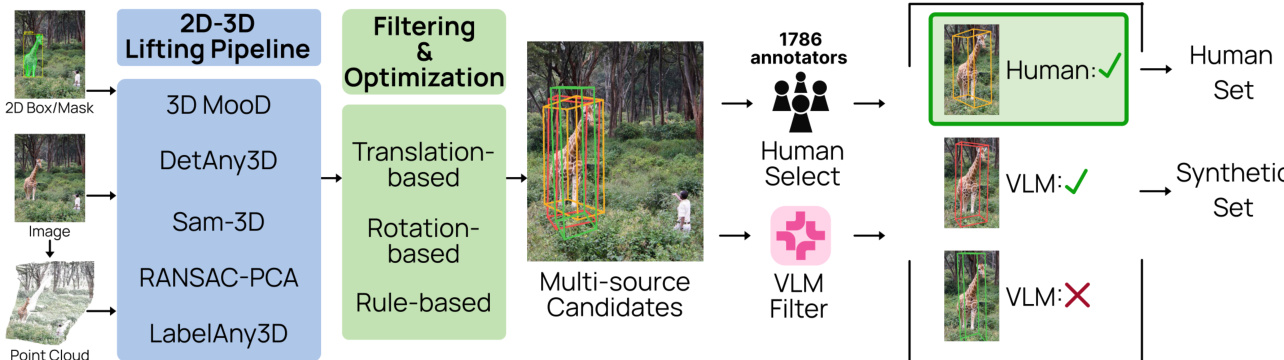
数据处理与候选生成 为了将 2D 标注提升到 3D 空间,作者采用了多阶段流水线:
- 几何提升 (Geometric Lifting): 在估计度量深度和相机内参之前,图像会经过 4 倍超分辨率处理。随后使用五种互补方法生成候选 3D 框:3D-MOOD、DetAny3D、SAM-3D、RANSAC-PCA 和 LabelAny3D。
- 精细化 (Refinement): 初始候选框经过平移和旋转优化,以与估计的深度图和 2D 投影约束对齐。
- 多阶段过滤:
- 几何过滤器: 根据边缘接触、遮挡率或不切实际的 3D 到 2D 投影尺寸移除候选框。
- 语义过滤器: 使用 VLM (Qwen3.5-9B) 移除描绘的物体(例如图片或反射)以及合成图像。
- 尺寸与几何过滤器: 使用 GPT-4o-mini 估计物理尺寸,以过滤掉不合理的尺度、深度与宽度比以及轴比例。
- 最终选择: 作者使用两条路径来最终确定标注:
- 人工选择: 对约 103K 张图像的子集进行众包标注员验证,由其对候选质量进行评分。
- VLM 选择: 对于剩余的约 896K 张图像,使用经过微调的 Molmo2 模型根据六项感知标准自动选择最佳候选。
训练与评估使用 作者在三阶段训练课程中使用这些数据:
- 阶段 1: 在 Omni3D 上进行初始训练。
- 阶段 2: 在 Omni3D、WildDet3D-Data(包括人工和合成子集)以及补充数据集(CA-1M、Waymo、3EED 和 FoundationPose)的混合数据上进行微调。
- 阶段 3: 在 Omni3D 和 WildDet3D-Data 的人工标注部分上,使用 mask 引导的点和框训练进行最终微调。
在评估方面,作者构建了 WildDet3D-Bench,这是一个包含 700 多个开放词汇类别的野外 (in-the-wild) 基准测试。该基准测试使用平衡采样策略,以确保覆盖稀有、常见和频繁类别。
方法
WildDet3D 框架旨在通过用户指定的 prompt 引导,从单张 RGB 图像(可选增强相机内参和深度信息)中执行 3D 物体检测。该架构围绕三个主要组件构建:处理视觉和几何输入的双视觉编码器系统、根据多样化 prompt 类型进行条件检测的可提示检测器 (promptable detector),以及产生具有明确方向的度量 3D 边界框的 3D 检测头。框架概览如图 3 所示,展示了从输入经过特征提取与融合到多任务预测的模块化流程。
双视觉编码器系统解耦了语义和几何特征提取,以解决检测质量与度量深度估计之间固有的权衡。它由一个图像编码器和一个 RGBD 编码器组成。图像编码器是一个带有 SimpleFPN 颈部的 Vision Transformer (ViT-H),它从分割预训练检查点初始化,并提取高分辨率、多尺度的语义特征。RGBD 编码器基于 DINOv2 ViT-L/14 主干网络,处理同一图像以及可选的深度图,通过卷积颈部产生深度 latents。这两个编码器独立运行,允许架构利用针对各自任务优化的不同预训练模型——图像编码器用于语义分割,RGBD 编码器用于度量深度估计。深度融合模块(在图 3 中以黄色标出)通过将深度 latents 注入图像编码器的特征图中来合并这两个流。这是通过残差连接实现的,其中深度 latents 在双线性上采样以匹配视觉特征分辨率并通过 LayerNorm 归一化后,使用零初始化的 1×1 卷积投影到视觉特征维度。这种设计确保了预训练的视觉特征在训练期间保持稳定,而深度贡献是逐渐学习的。
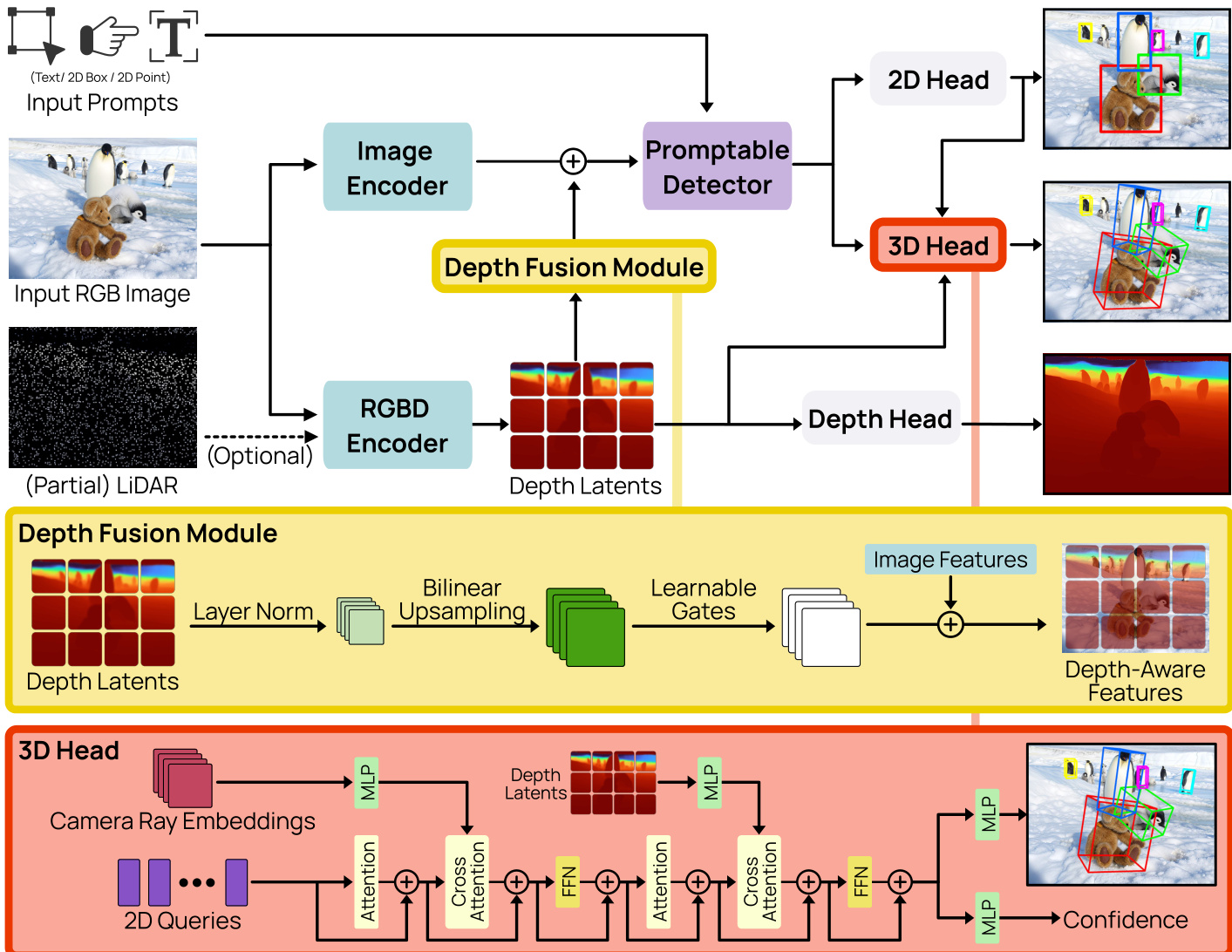
可提示检测器(如图 3 中的紫色模块所示)将各种输入 prompt 类型统一为检测头的单一表示。它接受四种 prompt 模态:文本、点、框和示例 (exemplar)。每种 prompt 类型分别进行编码:文本 prompt 被 token 化并通过因果文本 Transformer 传递;几何 prompt(点和框)通过求和直接坐标投影、ROI 对齐特征和正弦位置编码来编码,并由 cross-attention Transformer 进行精细化。示例 prompt 使用类似的编码,但通过特殊的 token 和多目标匹配策略进行区分。来自所有 prompt 类型的编码后的 tokens 被拼接成一个单一序列,在随后的检测阶段中充当 cross-attention 记忆。该组件采用基于单个 prompt 的批处理策略,即训练 batch 是围绕唯一的 prompt 实例而非图像构建的,从而实现了细粒度监督并能处理每张图像中任意数量的类别。
3D 检测头(如图 3 中的红色部分所示)负责生成最终的 3D 边界框预测。它获取来自可提示检测器的查询特征,并利用多源信息对其进行增强。对于每个 decoder 层,它首先通过从相机内参生成逐像素射线方向并使用 8 阶实球谐函数对其进行编码,从而引入相机几何信息。该射线特征通过 cross-attention 进行融合。随后,它使用另一个 cross-attention 模块融合来自 RGBD 编码器的深度 latents。融合后的查询特征随后通过一个两层 MLP,以预测 3D 框的 12 维编码,其中包括中心偏移、log-深度、log-尺寸和 6D 旋转表示。为了解决 3D 框方向中固有的歧义,对真值和预测值均应用了两步无歧义旋转归一化:对尺寸进行排序使得宽度小于或等于长度,并将偏航角 (yaw angle) 折叠到区间 [0,π) 内。这种归一化确保了框几何形状与回归目标之间的一一映射。在推理时,通过将预测的偏移量和深度进行反向投影来恢复 3D 中心。一个并行的置信度分支(也是一个两层 MLP)预测标量分数 s3D∈[0,1],该分数使用 IoU 感知的 focal BCE 损失进行训练,并结合了深度预测质量和 3D IoU 的软目标。最终的检测分数是 2D 物体性分数与 3D 置信度的加权和。

实验
研究人员通过在新的野外基准测试、标准数据集(如 Omni3D)以及 zero-shot 迁移任务上的广泛测试来评估 WildDet3D,以验证其开放词汇能力和几何准确性。实验表明,该模型在检测多样化、长尾物体类别方面显著优于现有方法,并在不同环境中实现了有效的泛化。此外,结果表明该架构成功利用了可选的深度线索来解决尺度歧义,并为机器人、AR/VR 和移动计算中的现实世界应用提供了多功能的基础。
该模型使用三阶段训练流水线,从零开始并逐步经过数据混合和 mask 引导训练。每个阶段采用特定的数据组合和学习率调度方案来逐步提高性能。训练从零开始,并以复杂度递增的方式分为三个阶段。阶段 2 以特定的数据混合比例结合多个数据集,并使用阶段 1 的输出作为初始化。阶段 3 使用不同的数据混合方式和 mask 引导方法,进一步精细化阶段 2 的模型。

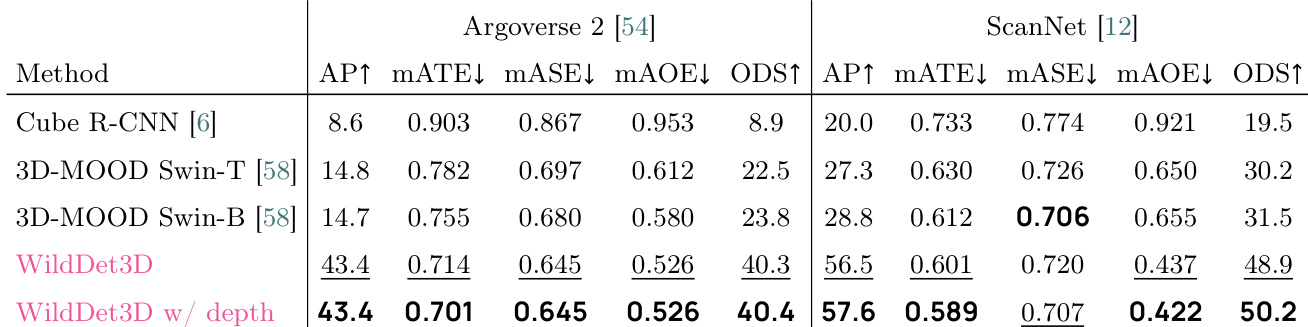
作者在 Argoverse 2 和 ScanNet 基准测试上评估了 WildDet3D,结果显示在检测和几何准确性方面较之前的方法有显著提升。该模型实现了更高的 AP 和 ODS 分数,同时减少了平移、尺度和方向误差,尤其是在深度信息可用时。与基准模型相比,WildDet3D 在 Argoverse 2 和 ScanNet 上实现了更优越的检测和几何准确性。模型减少了平移、尺度和方向误差,提高了定位精度。当引入深度信息时,性能提升更为明显,尤其是在 ScanNet 上。
作者在 WildDet3D-Bench 上评估了 WildDet3D,证明了在不同训练数据和 prompt 模态下均较基准模型有显著改进。结果表明,加入额外数据和真值深度可以带来实质性的性能提升,特别是对于稀有和常见类别。WildDet3D 在 WildDet3D-Bench 的所有类别和 prompt 类型上均达到了最高性能。引入额外的训练数据和真值深度显著提高了检测准确性。性能提升在稀有和常见类别上最为显著,突显了对未见类别的强大泛化能力。
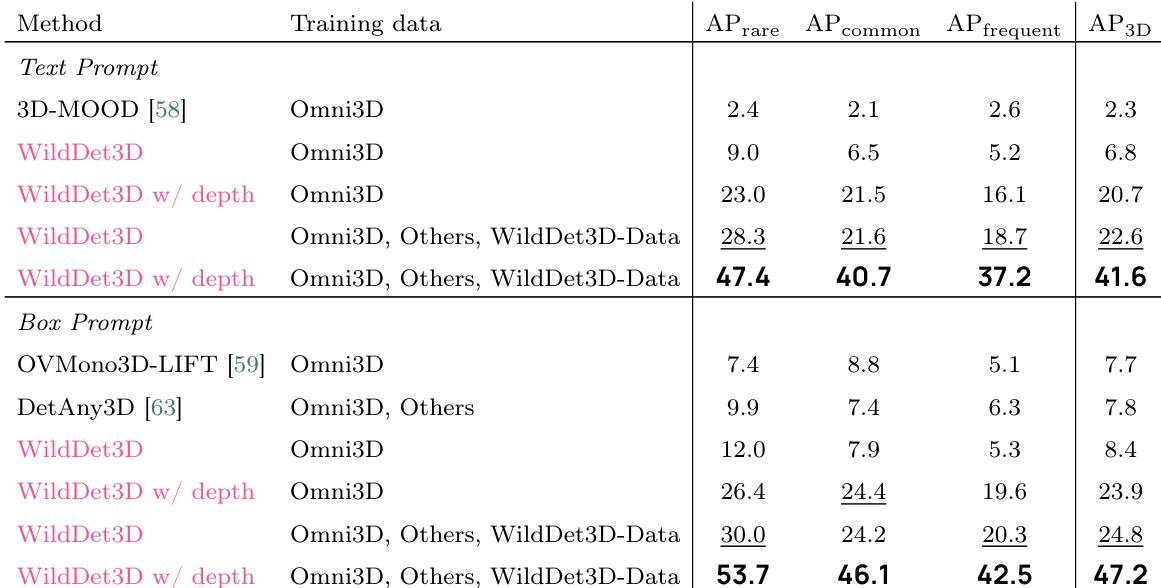
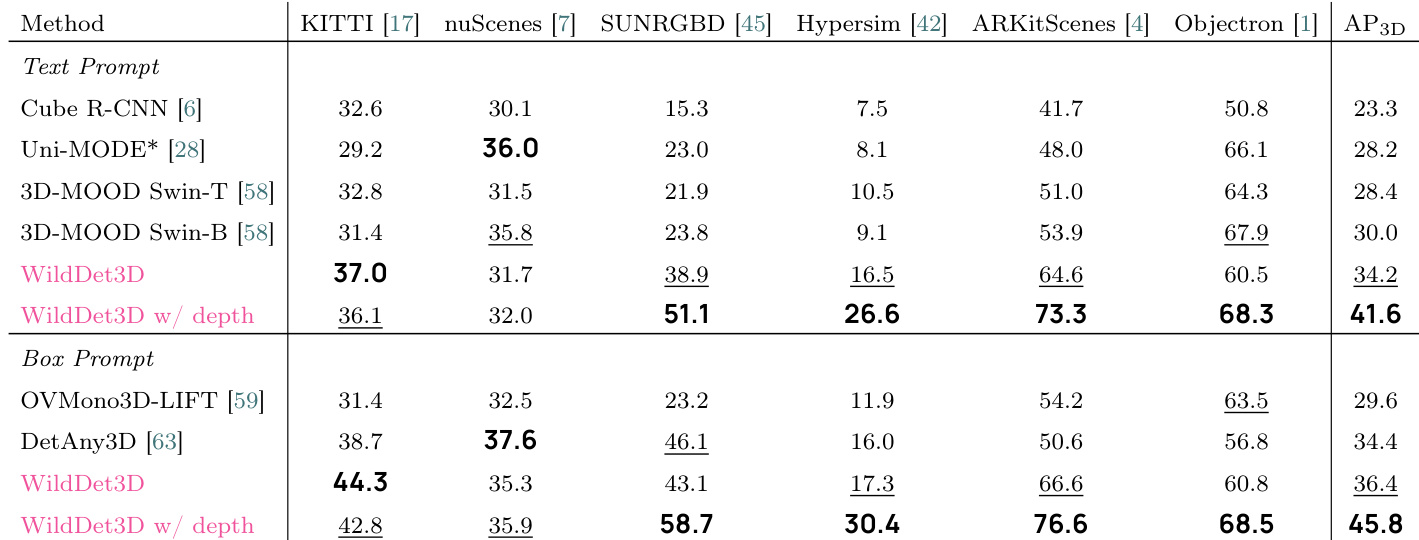
作者在多个基准测试上评估了 WildDet3D,显示出优于现有方法的性能。结果表明,引入深度信息显著增强了检测准确性,特别是在框 prompt 设置下。该模型在各种数据集上都取得了强劲的结果,展示了泛化性和鲁棒性。WildDet3D 在多个数据集上的 AP3D 高于所有基准模型。当提供深度时,性能大幅提升,尤其是在框 prompt 设置下。模型在文本和框 prompt 设置下均表现出一致的增益,其中在稀有类别上的提升最大。
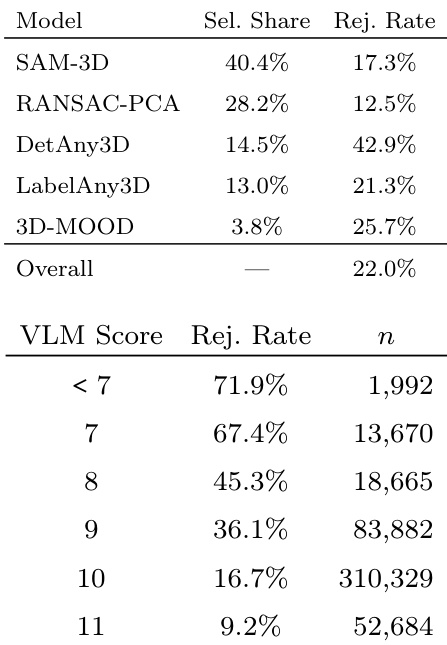
该表展示了标注流水线的验证结果,显示了人工标注员如何选择和拒绝不同的候选模型,以及 VLM 分数如何与人工判断相关联。数据表明,模型质量在不同候选者之间存在显著差异,且 VLM 评分能有效预测人工接受度,尽管它不能完全取代人工评估。人工标注员选择和拒绝候选模型的比例在不同方法之间差异很大。VLM 分数与人工拒绝率呈现完美的单调相关性,表明其具有强大的预测能力。尽管相关性很强,但由于即使在高分下拒绝率仍存在显著差距,仅靠 VLM 评分仍无法取代人工判断。
该模型通过多阶段训练流水线进行评估,并在包括 Argoverse 2、ScanNet 和 WildDet3D-Bench 在内的各种基准测试中进行测试,以验证检测准确性和几何精度。结果表明,引入深度信息和多样化的训练数据显著增强了定位和泛化能力,特别是对于稀有类别。此外,标注流水线验证表明,虽然 VLM 分数与人工判断强相关,但它们是作为一种预测工具,而非人工评估的完全替代品。