Command Palette
Search for a command to run...
INSPATIO-WORLD:一种基于时空 Autoregressive Modeling 的实时 4D 世界 Simulator
INSPATIO-WORLD:一种基于时空 Autoregressive Modeling 的实时 4D 世界 Simulator
摘要
构建具有空间一致性(spatial consistency)和实时交互性的世界模型(world models),仍然是计算机视觉领域的一项根本性挑战。目前的视频生成范式往往面临空间持久性(spatial persistence)缺失和视觉逼真度不足的问题,导致难以支持在复杂环境中的无缝导航。为了应对这些挑战,我们提出了 INSPATIO-WORLD,这是一个全新的实时框架,能够从单段参考视频中恢复并生成高保真、动态的交互式场景。我们方法的核心是 时空自回归(Spatiotemporal Autoregressive, STAR) 架构,通过两个紧密耦合的组件实现一致且可控的场景演变:隐式时空缓存(Implicit Spatiotemporal Cache) 将参考观测与历史观测聚合为潜在的世界表示(latent world representation),从而确保在长程导航(long-horizon navigation)过程中的全局一致性;显式空间约束模块(Explicit Spatial Constraint Module) 则用于强化几何结构,并将用户交互转化为精确且符合物理规律的相机轨迹。此外,我们还引入了 联合分布匹配蒸馏(Joint Distribution Matching Distillation, JDMD)。通过使用真实世界的数据分布作为正则化引导,JDMD 有效克服了因过度依赖合成数据而导致的保真度下降问题。广泛的实验表明,INSPATIO-WORLD 在空间一致性和交互精度方面显著优于现有的最先进(SOTA)模型,在 WorldScore-Dynamic benchmark 上实时交互方法的排名位居第一,并为从单目视频重建的 4D 环境导航建立了一条实用的 pipeline。
一句话总结
所提出的 INSPATIO-WORLD 框架作为一个实时 4D 世界模拟器,通过利用由用于全局一致性的隐式时空缓存(Implicit Spatiotemporal Cache)、用于物理合理导航的显式空间约束模块(Explicit Spatial Constraint Module)以及用于维持视觉真实感的联合分布匹配蒸馏(Joint Distribution Matching Distillation)组成的时空自回归(Spatiotemporal Autoregressive)架构,能够从单个参考视频中生成高保真、动态的交互式场景。
核心贡献
- 本文引入了 INSPATIO-WORLD,这是一种实时 4D 生成式世界模型,它利用时空自回归(STAR)架构,实现了从单个参考视频进行高保真、交互式场景生成。该框架结合了用于长期全局一致性的隐式时空缓存,以及将用户交互转化为物理合理相机轨迹的显式空间约束模块。
- 提出了一种多条件因果初始化(Multi-conditional Causal Initialization)策略,通过在地面真值(ground-truth)数据或教师模型轨迹上进行分块自回归多步演练,来改进多条件可控生成。该方法在初始训练阶段建立了前序帧、参考图像和几何约束等异构输入之间的准确关联。
- 该工作提出了联合分布匹配蒸馏(JDMD),这是一种双教师范式,利用现实世界的数据分布来解耦并优化运动保真度和感知真实感。实验结果表明,该方法弥合了合成领域与物理领域之间的差距,在 24 FPS 的性能下实现了最先进的空间连续性和视觉精度。
引言
构建交互式 4D 世界模型对于推进具身智能和自动驾驶至关重要,因为它允许在模拟环境中进行真实的、高自由度的导航。然而,当前的视频扩散模型由于空间持久性退化、视觉纹理中显著的合成到现实(synthetic-to-real)差距以及对用户定义相机轨迹的控制不精确,在长程漫游方面面临挑战。作者利用时空自回归(STAR)架构来克服这些瓶颈,使用隐式时空缓存来实现全局一致性,并使用显式空间约束来实现精确的几何推理。此外,他们引入了联合分布匹配蒸馏(JDMD),这是一个双教师学习框架,通过将模型特征与现实世界的数据分布对齐,在不牺牲运动可控性的情况下确保高视觉保真度。
方法
作者利用时空自回归框架,在多模态约束下实现了长程、交互式视频生成。该框架通过将生成过程分解为一系列分块(chunks)来运行,每个分块由 K 个连续帧组成,并将潜在序列 Z1:I 建模为条件概率的乘积。每个数据块 zi 的生成受三个不同条件的引导:历史上下文、参考引导和几何约束,从而确保时间连续性和空间一致性。如下图所示,系统的核心是 Diffusion Transformer (DiT) 模块,它接收以这些输入为条件的去噪潜在表示,以生成下一个视频数据块。
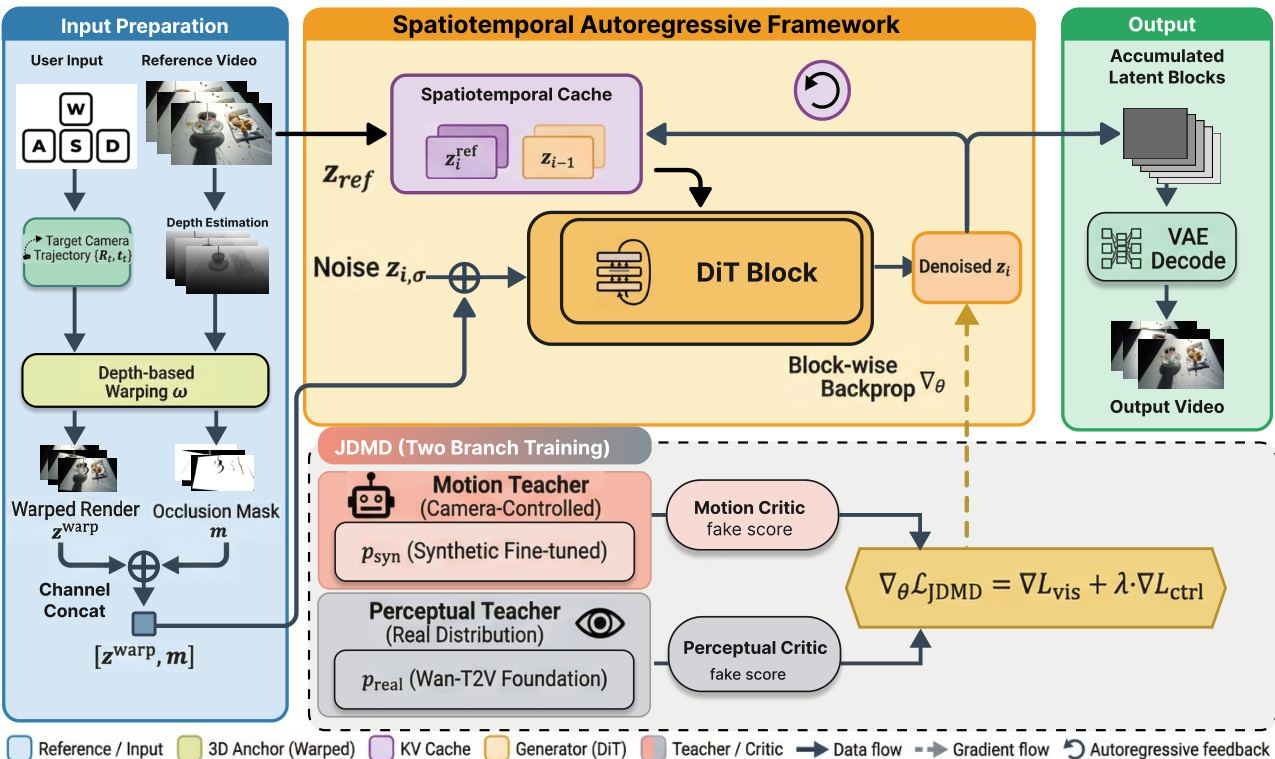
该框架集成了时空缓存机制,以高效地维持长期记忆。该机制将由先前生成的潜在变量 zi−1 表示的短期历史信息,与从参考视频中检索到的长期参考信息 ziref 相结合。这些信息被聚合到一个隐式 ST-Cache 中,为生成过程提供稳定的时空锚点。为了缓解旋转位置嵌入(RoPE)中由序列长度增长引起的分布偏移,采用了位置索引固定策略,将当前数据块、参考锚点和历史数据块的起始位置锚定到固定的坐标原点。这稳定了模型的表示空间并增强了空间一致性。此外,采用了分块反向传播策略来解决训练期间的可微性和内存瓶颈问题。该策略将前向推理与反向优化解耦,允许在每个分块内实现全链路可微,同时显著降低了峰值内存占用。
为了实现精确的相机控制,系统结合了源自用户交互指令的显式几何约束。用户的旋转、平移和透视偏移命令被转化为 6-DoF 相对位姿变换 ΔTi,并递归累积以定义当前数据块的全局位姿 Ti。基于此位姿,参考特征通过重投影操作与当前视角进行几何对齐。如图所示,这一过程涉及通过前馈重建方法从参考视频的潜在表示中提取深度图和相机内参。生成的变形特征 ziwarp 和有效像素掩码 mi 被拼接并作为显式结构引导输入到 DiT 模块中。该机制充当了空间记忆代理,提供确定性约束,防止场景失真并确保多视图一致性。
训练过程采用联合分布匹配蒸馏(JDMD)策略,以平衡运动依从性和视觉保真度。该方法使用带有两个冻结教师模型的多任务学习范式:一个是基于合成数据训练的运动教师,用于引导精确的运动控制;另一个是源自现实世界文本到视频基础模型的感知教师,用于保持视觉丰富性。在训练期间,学生模型在两个蒸馏任务之间交替进行:一个是利用合成数据分布进行运动控制的可控视频重渲染(V2V)任务,另一个是与现实世界数据分布对齐以实现视觉保真度的文本到视频(T2V)任务。总损失是视觉蒸馏损失 Lvis 和条件控制损失 Lctrl 的加权和,使模型能够同时学习精确的时空一致性和高保真视觉真实感。实现细节表明,该框架使用三阶段训练过程,从教师模型训练开始,随后是学生初始化,最后进入 JDMD 蒸馏阶段,每个阶段都有特定的学习率。
实验
通过用于下一场景生成的 WorldScore 基准测试、用于空间持久性的长期图像到视频生成,以及用于指令遵循的相机控制视频重渲染,评估了 INSPATIO-WORLD 的有效性。结果表明,该模型通过在长序列中保持卓越的几何一致性和精确的相机控制,且不遭受结构扭曲或动力学漂移,实现了最先进的性能。此外,与现有方法相比,该框架提供了极高的计算质量权衡,具备高保真视觉生成和实时执行能力。
作者在 WorldScore 基准测试上评估了 INSPATIO-WORLD,并将其与多个最先进的模型进行了比较。结果显示,INSPATIO-WORLD 在保持高计算效率的同时,在相机控制和光度质量方面取得了卓越的性能。与所有列出的方法相比,INSPATIO-WORLD 在相机控制精度和平移误差方面取得了最佳结果。在对比的模型中,该方法以最低的 FID 和 FVD 分数展示了最高的生成质量。INSPATIO-WORLD 在控制精度和视觉质量指标上均优于其他模型。
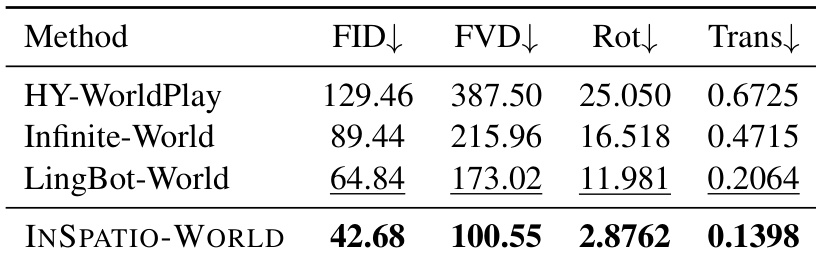
作者使用两个数据集在相机控制视频重渲染任务上将 INSPATIO-WORLD 与最先进的方法进行了对比。结果表明,INSPATIO-WORLD 在生成质量和相机控制方面表现优异,同时与参考视频保持高度一致。在两个数据集的视频质量指标上,INSPATIO-WORLD 均优于基准模型。该方法以极小的轨迹误差实现了高相机控制精度。与现有方法相比,它与输入参考视频保持了更优的一致性。

作者在 WorldScore 基准测试上评估了 INSPATIO-WORLD,并将其与最先进的模型进行了比较。结果显示,INSPATIO-WORLD 在相机控制和光度质量方面达到了顶尖性能,同时保持了强大的整体动态评分,在关键指标上优于其他方法。在所有方法中,INSPATIO-WORLD 在相机控制和光度质量方面获得了最高分。该模型在运动平滑度和 3D 一致性方面优于其他模型,展示了强大的时空生成能力。INSPATIO-WORLD 在整体动态和静态评分中排名第一,在交互式和非交互式设置下均表现出卓越的性能。

结果表明,INSPATIO-WORLD 在 WorldScore 基准测试上实现了高性能,并具有卓越的计算效率。该模型在以较低计算成本运行的同时,在动态指标上优于其他模型,表明在质量和资源使用之间具有强大的权衡能力。INSPATIO-WORLD 在动态指标上达到顶尖性能,同时所需的计算资源显著降低。该模型在运动平滑度、相机控制精度和光度质量方面优于现有方法。它展示了卓越的计算质量权衡,打破了几何控制与生成保真度之间传统的零和关系。
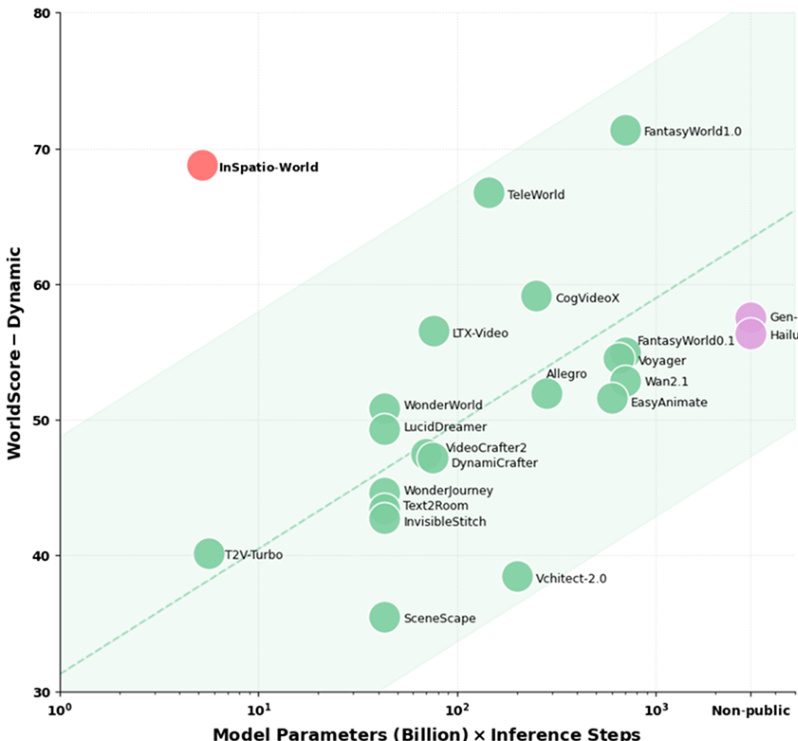
作者利用 WorldScore 基准测试和各种视频重渲染数据集,将 INSPATIO-WORLD 与最先进的模型进行了对比,以验证其在相机控制和视觉保真度方面的性能。结果表明,该模型在保持高运动平滑度的同时,实现了卓越的相机控制精度、光度质量和时间一致性。此外,INSPATIO-WORLD 在生成质量和计算效率之间提供了极佳的平衡,有效地克服了几何控制与视觉细节之间的传统权衡。