Command Palette
Search for a command to run...
往事并非过往:基于 Memory 增强的 Dynamic Reward Shaping
往事并非过往:基于 Memory 增强的 Dynamic Reward Shaping
Yang Liu Enxi Wang Yufei Gao Weixin Zhang Bo Wang Zhiyuan Zeng Yikai Zhang Yining Zheng Xipeng Qiu
摘要
尽管强化学习在大型语言模型(LLM)的应用中取得了显著成功,但一种常见的失效模式是采样多样性降低,即策略会重复生成相似的错误行为。传统的熵正则化(entropy regularization)旨在鼓励当前策略下的随机性,但并未显式地抑制在多次 rollout 过程中反复出现的失败模式。为此,我们提出了 MEDS,这是一个记忆增强型动态奖励塑造(Memory-Enhanced Dynamic reward Shaping)框架,它将历史行为信号纳入奖励设计之中。通过存储并利用模型的中间表示(intermediate model representations),我们能够捕获过往 rollout 的特征,并利用基于密度的聚类(density-based clustering)算法来识别频繁出现的错误模式。被分配到更普遍错误簇(error clusters)中的 rollout 会受到更严厉的惩罚,从而在减少重复错误的同时,鼓励更广泛的探索。在五个数据集和三个基础模型上的实验表明,MEDS 的平均性能始终优于现有的 baseline,其 pass@1 和 pass@128 指标分别实现了高达 4.13 个点和 4.37 个点的提升。通过基于 LLM 的标注以及定量多样性指标进行的进一步分析表明,MEDS 显著增加了采样过程中的行为多样性。
一句话总结
为了缓解大语言模型在强化学习中采样多样性降低的问题,本文提出的 Memory-Enhanced Dynamic reward Shaping (MEDS) 框架利用中间模型表示和基于密度的聚类来惩罚重复的错误模式,最终在五个数据集和三个基础模型上将性能提升了高达 4.37 个 pass@128 点。
核心贡献
- 本文引入了 MEDS,这是一种 Memory-Enhanced Dynamic reward Shaping 框架,旨在通过将历史行为信号纳入 reward 设计中,来惩罚循环出现的失败模式。
- 该方法利用层级 logits 作为推理轨迹的轻量级表示来进行基于密度的聚类,从而识别并抑制强化学习过程中频繁出现的错误模式。
- 在五个数据集和三个基础模型上的实验结果表明,MEDS 将推理性能提升了高达 4.37 个 pass@128 点,并增加了采样过程中的行为多样性。
引言
强化学习是优化大语言模型推理能力的关键驱动力。然而,on-policy 优化经常面临采样多样性崩溃的问题,即模型陷入重复且错误的推理模式中。虽然传统的熵正则化试图通过增加当前策略的随机性来缓解这一问题,但它无法显式地阻止在不同训练 rollout 中反复出现的特定失败模式。作者利用名为 MEDS (Memory-Enhanced Dynamic reward Shaping) 的框架来解决这一问题,通过将历史行为信号纳入 reward 设计中。通过使用层级 logits 作为推理轨迹的轻量级表示,作者采用基于密度的聚类来识别并惩罚频繁出现的错误模式,从而鼓励更广泛的探索,并防止模型陷入自我强化的错误中。
数据集
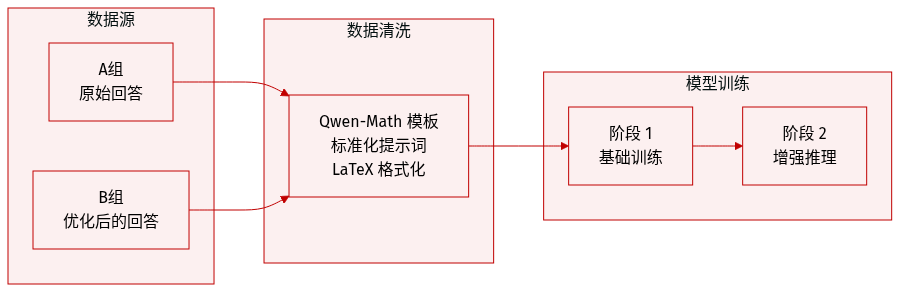
数据集概览
作者使用了一个专为数学推理设计的结构化数据集,其组成部分如下:
-
数据集组成与子集
- Group A: 该子集由初始训练阶段使用的原始答案组成。
- Group B: 该子集包含在后期训练阶段引入的额外答案,用于进一步优化模型性能。
-
数据处理与格式化
- 标准化模板: 所有训练和评估问题都通过 Qwen-Math 模板进行处理。这确保了统一的 prompt 结构,指示模型进行逐步推理,并将最终结果置于 LaTeX 方框格式中。
- Prompt 结构: 模板利用特定的控制 token 来定义系统指令、用户问题和助手回答,为数学问题求解创造了一个标准化的环境。
-
模型使用
- 训练阶段: 数据应用于多阶段训练方法,其中 Group A 作为基础训练集,Group B 在随后的阶段中被整合以增强推理能力。
方法
MEDS 框架通过一个三阶段过程运行,旨在通过识别并惩罚响应中共同的推理模式来减轻错误的重复发生。总体架构如流程图所示,由逻辑特征提取、基于记忆的聚类和 reward shaping 组成。
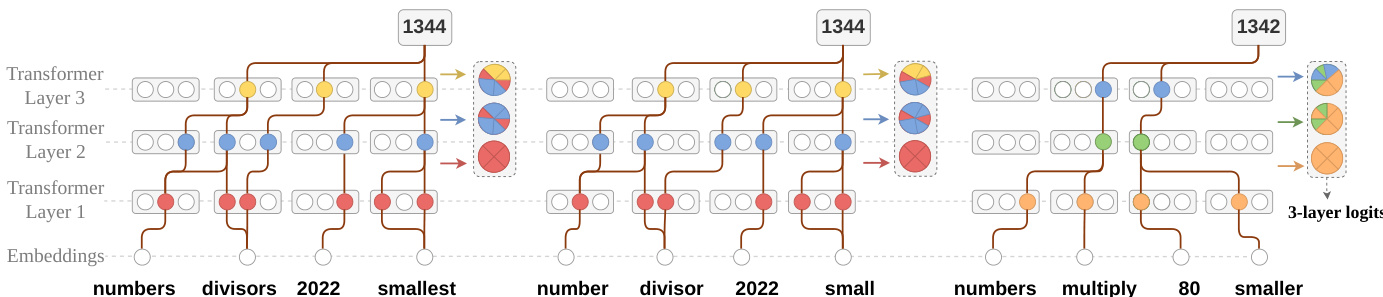
在第一阶段“逻辑特征提取”中,模型处理输入 x 生成响应 y~,并从中导出逻辑特征向量 f(y~)。该向量由最终答案中第一个 token y∗ 的层级 logits 构建,具体是使用 Transformer 后半部分的层来捕捉推理模式。来自每一层 n 在 y∗ 位置的 logits 被聚合为一个特征向量 f(y~)=concat(l∗(n)∣n=N/2,…,N),其中 l∗(n) 是第 n 层中对应 y∗ 的 logit。这一过程利用了 logits 随层演变反映模型内部推理这一事实,如图中所示的 3 层模型中的 logits 聚合过程。
第二阶段“基于记忆的聚类”维护一个针对每个 prompt 的错误记忆 Gx,用于存储为给定 prompt 采样的所有历史响应的特征表示。随后使用 HDBSCAN 对该集合进行聚类,将具有相似逻辑特征的响应归为簇 Ck。簇的数量 K 是动态确定的,聚类过程能够识别推理轨迹中的模式。
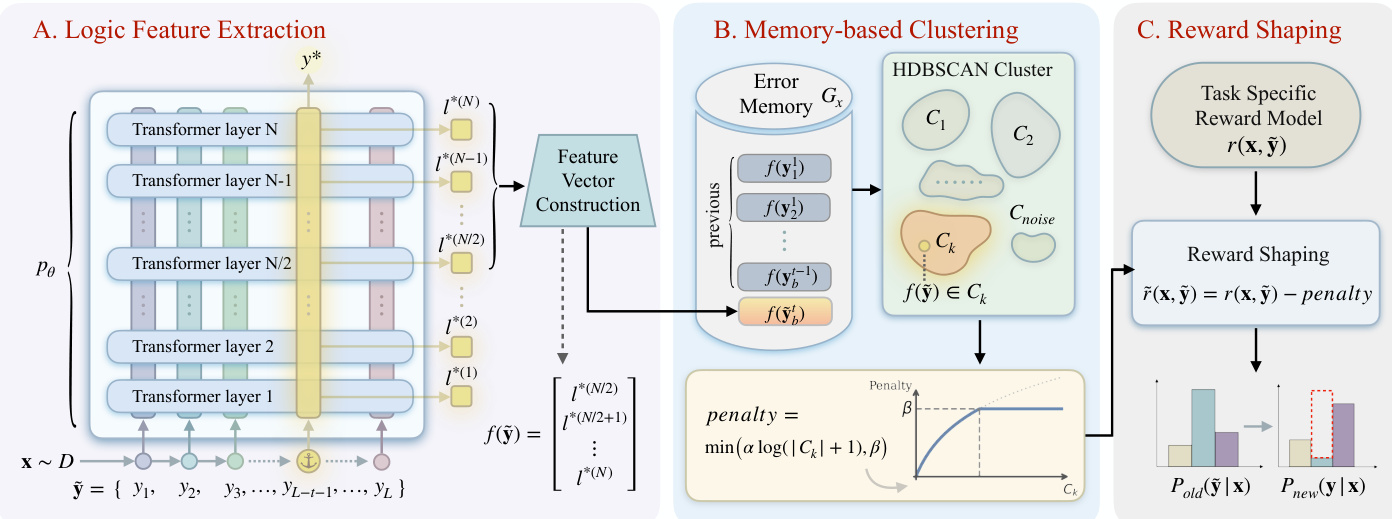
在最后阶段“reward shaping”中,指示函数 c(y~) 被定义为 log(∣Ck∣+1),其中 ∣Ck∣ 是 f(y~) 所属簇的大小。通过减去一个与簇大小成正比的惩罚项来调整 reward,该惩罚项计算为 min(αlog(∣Ck∣+1),β),从而得到塑造后的 reward r~(x,y~)=r(x,y~)−penalty。这种惩罚机制会阻止策略生成遵循过去已观察到的错误模式的响应,有效地塑造 reward 景观以促进多样化且正确的推理路径。调整后的 reward 随后被用于更新策略,如框架图所示。
实验
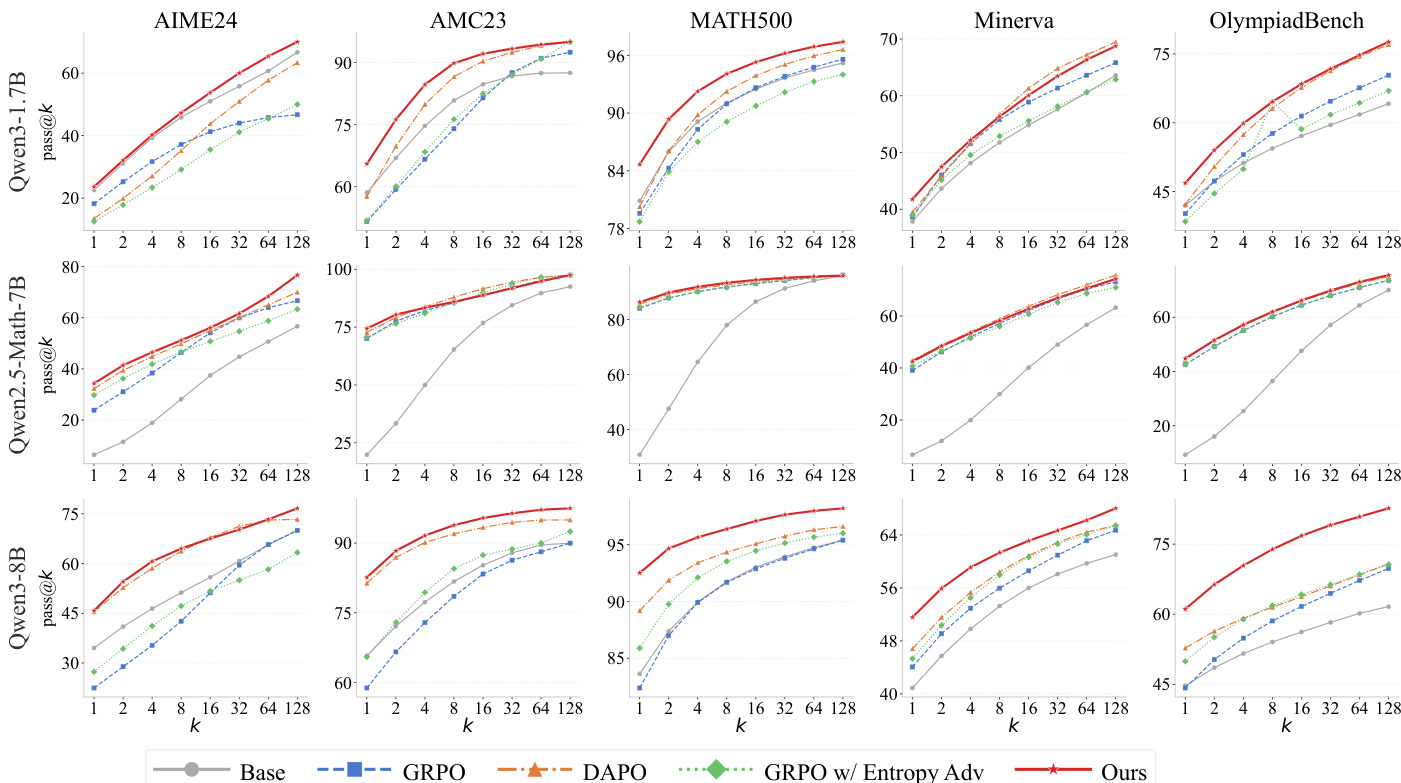
所提出的 MEDS 方法在三种模型规模上,使用五个数学推理基准测试进行了评估,以将其性能与 GRPO 和 DAPO 等基线进行比较。结果表明,MEDS 一致地实现了卓越的数学推理能力,且收益随基础模型能力的提升而扩展。行为和表示分析证实,该方法通过保持更高的 rollout 多样性并利用能有效捕捉不同推理模式的基于 logit 的聚类,增强了探索能力。
作者在多个数学基准测试上使用 pass@k 指标评估了其方法与基线方法的表现。结果显示,在不同的模型规模和数据集上,其方法始终优于基础模型和其他强化学习方法,且随着模型规模的增加,改进变得更加显著。所提出的方法在所有模型规模的所有基准测试中均达到了最佳性能。性能提升在较大模型上最为显著,表明其具有随模型容量扩展的可扩展性。该方法在所有设置下都一致优于 DAPO 和 GRPO 等强基线。
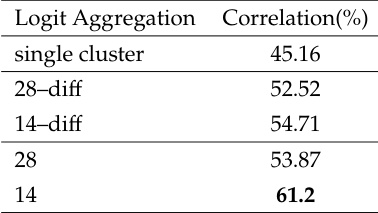
该表比较了用于聚类的不同 logit 聚合方法,并展示了它们与人工标注的相关性。使用最后 14 层达到了最高的相关性,表明其与推理模式的对齐效果更好。使用最后 14 层作为聚类特征可以获得与人工标注最高的相关性。Logit 聚合方法显示出不同程度的相关性,其中一些方法优于其他方法。相关性结果表明,更好的聚类质量与更优的下游性能是一致的。
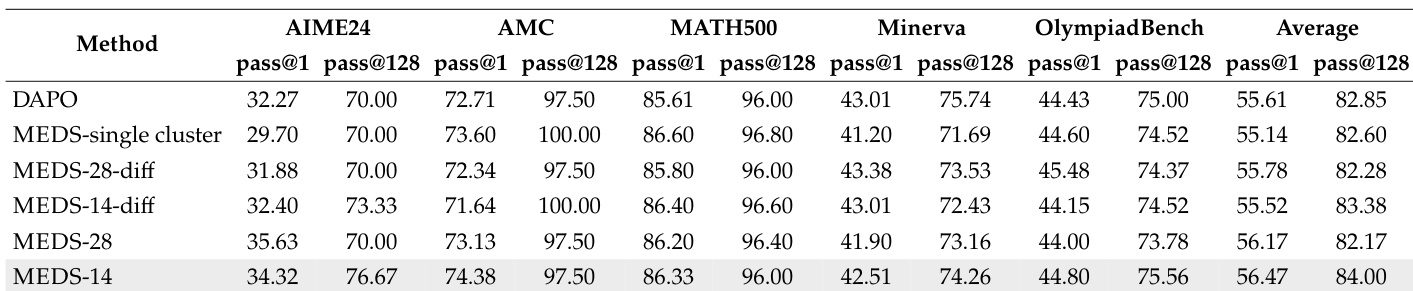
该表比较了不同方法在多个数学基准测试中的性能。所提出的 MEDS-14 方法实现了最高的平均性能,在大多数指标上始终优于 DAPO 和其他变体。MEDS-14 在所有基准测试中实现了最高的平均性能。所提出的方法在大多数单个基准测试上优于 DAPO 和其他变体。不同方法之间的性能差异显著,其中 MEDS-14 显示出最一致的改进。
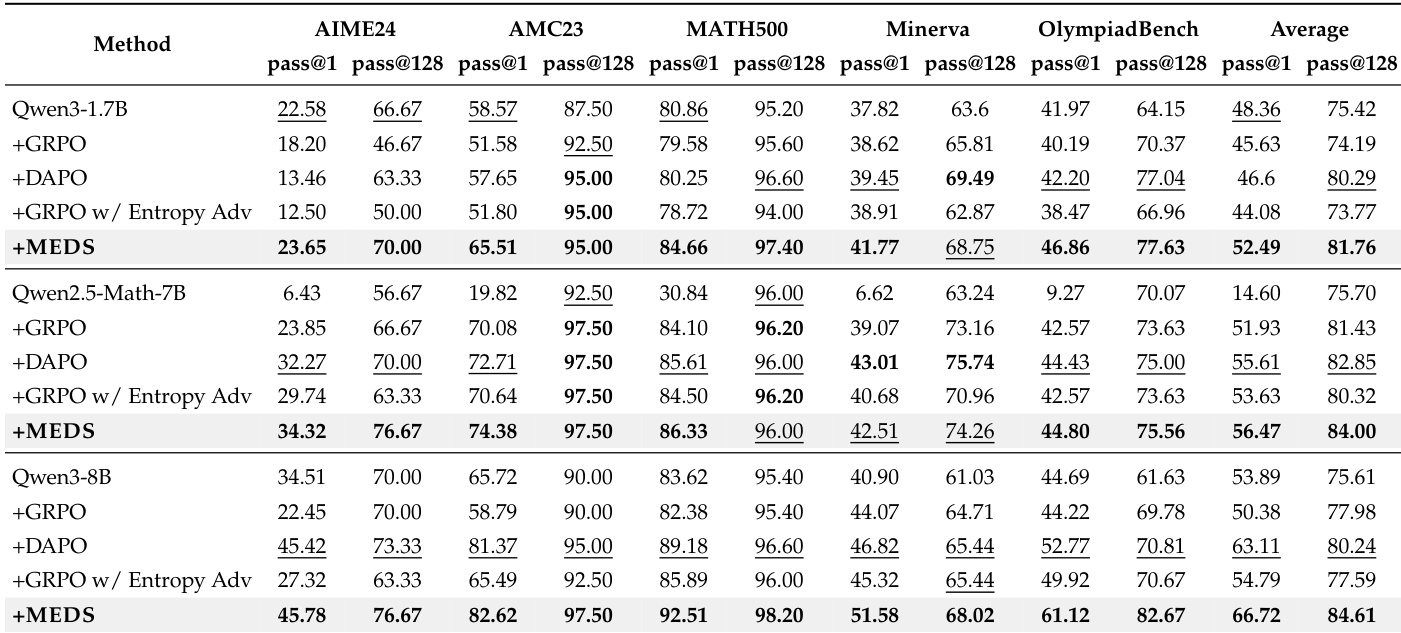
作者在多个数学基准测试和模型规模上将其方法与多个基线进行了比较。结果显示,其方法始终优于基础模型和强基线,且在较大模型上的改进更加明显。该方法还展示了增强的探索行为和对基于 logit 的聚类信号的有效利用。所提出的方法在所有基准测试和模型规模上始终实现最佳性能,优于基础模型和强基线。该方法在较大模型上表现出更强的改进,表明其收益随模型能力扩展。该方法增强了探索行为,这可以通过与基线相比更高的多样性指标和更低的 top-1 特征值比率得到证明。
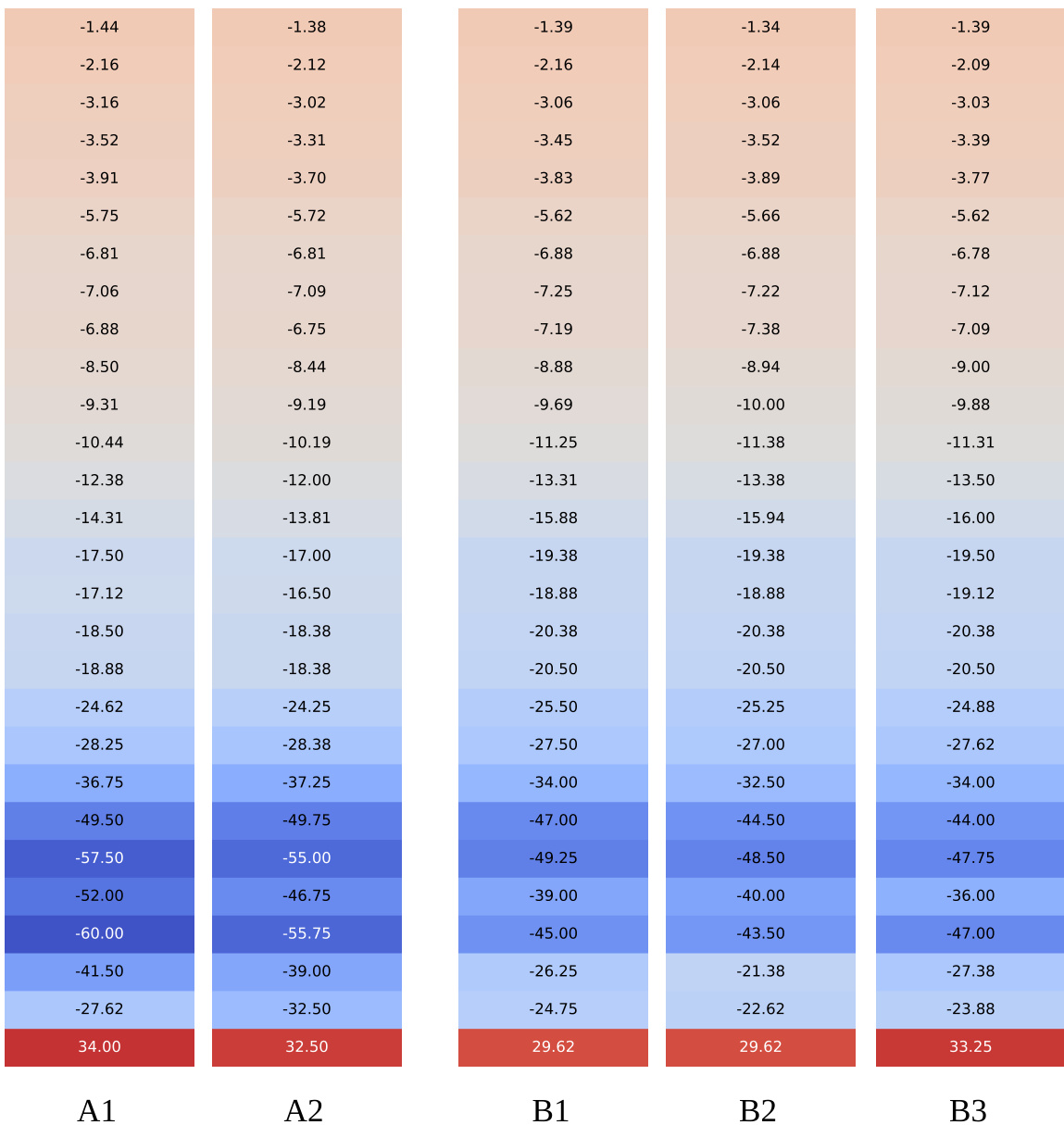
热力图可视化了模型响应在不同层中的 logit 值,显示了标记为 A1、A2、B1、B2 和 B3 的响应具有截然不同的模式。簇内的响应表现出相似的 logit 轨迹,表明具有共同的推理结构,而来自不同簇的响应表现出发散的模式,反映了不同的推理路径。簇内的响应在各层间表现出相似的 logit 轨迹,表明具有共同的推理结构。来自不同簇的响应表现出独特的 logit 模式,反映了不同的推理路径。Logit 值在后期层中变化更为显著,此时推理模式变得更加明显。
作者在多个数学基准测试和模型规模上,将所提出的方法与各种基线和 logit 聚合技术进行了评估。结果表明,该方法始终优于现有的强化学习方法,且性能增益随模型容量有效扩展。此外,对 logit 轨迹的分析表明,利用最后几层进行聚类可以提供与人类推理模式最强的对齐,并实现更有效的探索。