Command Palette
Search for a command to run...
Matrix-Game 3.0:具有长时程 Memory 的实时流式交互式 World Model
Matrix-Game 3.0:具有长时程 Memory 的实时流式交互式 World Model
摘要
随着交互式视频生成技术的不断进步,diffusion models 已日益展现出作为世界模型(world models)的巨大潜力。然而,现有方法仍难以同时实现具备记忆能力的长期时间一致性(long-term temporal consistency)与高分辨率实时生成,这限制了其在现实场景中的应用。为了解决这一问题,我们推出了 Matrix-Game 3.0,这是一款专为 720p 实时长视频生成设计的记忆增强型交互式世界模型。在 Matrix-Game 2.0 的基础上,我们从数据、模型和 inference 三个维度进行了系统性的改进。首先,我们开发了一个升级后的工业级无限数据引擎,该引擎整合了基于 Unreal Engine 的合成数据、来自 AAA 游戏的大规模自动化采集数据,以及现实世界的视频增强数据,从而实现大规模生产高质量的“视频-姿态-动作-prompt”四元组数据。其次,我们提出了一种针对长程一致性(long-horizon consistency)的训练框架:通过对预测残差(prediction residuals)进行建模,并在训练过程中重新注入不完美的生成帧,使基础模型具备自我修正能力;同时,通过感知摄像机的记忆检索与注入,使基础模型能够实现长程时空一致性。第三,我们设计了一种基于分布匹配蒸馏(Distribution Matching Distillation, DMD)的多段自回归蒸馏策略,并结合模型量化与 VAE decoder 剪枝技术,以实现高效的实时 inference。实验结果表明,Matrix-Game 3.0 在使用 5B 参数模型时,能够在 720p 分辨率下达到高达 40 FPS 的实时生成速度,同时在长达数分钟的序列中保持稳定的记忆一致性。将规模扩展至 2x14B 模型后,生成质量、动态效果及泛化能力得到了进一步提升。我们的方法为实现工业级可部署的世界模型提供了一条切实可行的路径。
一句话总结
作者提出了 Matrix-Game 3.0,这是一个增强型记忆的交互式世界模型,旨在实现 720p 实时长视频生成。该模型利用工业级无限数据引擎,并结合了包含预测残差建模和相机感知记忆检索的训练框架,以实现长时空一致性。
核心贡献
- 本文介绍了 Matrix-Game 3.0,这是一个增强型记忆的交互式世界模型,能够实时生成 720p 高分辨率视频。
- 开发了一种升级的工业级无限数据引擎,通过整合 Unreal Engine 合成数据、自动化 AAA 游戏采集和真实世界视频增强,生成高质量的 Video-Pose-Action-Prompt 四元组。
- 提出了一种用于长时一致性的新型训练框架,该框架利用预测残差建模和重新注入生成帧进行自我修正,并结合相机感知记忆检索与注入来维持时空一致性。
引言
交互式世界模型通过根据用户动作预测未来观测,对于在机器人、游戏和扩展现实中模拟复杂环境至关重要。虽然扩散模型推动了视频合成的发展,但现有方法难以在长时空一致性与实际部署所需的高分辨率、实时性能之间取得平衡。当前的方法通常面临权衡问题,即增加记忆或上下文长度会导致难以承受的延迟或几何稳定性的丧失。
作者通过在数据、建模和部署方面的协同设计框架引入了 Matrix-Game 3.0。他们利用 Unreal Engine 5 和 AAA 游戏采集开发了工业级数据引擎,以提供高质量的 video-pose-action-prompt 四元组。为了确保稳定性,作者实现了一种相机感知记忆检索机制和一个错误感知训练框架,使模型能够学习自我修正。最后,他们利用多段自回归蒸馏策略,结合模型量化和 VAE 剪枝,实现了高达 40 FPS 的 720p 生成。
数据集
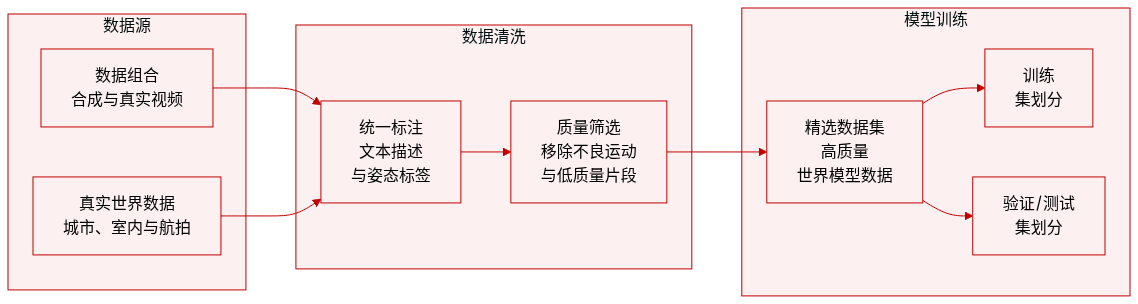
作者通过统一的流水线整合合成数据和真实世界数据,开发了一个旨在用于大规模世界模型训练的强大数据系统。
-
数据集构成与来源 该数据集结合了来自基于 Unreal Engine 的第一人称生成和 AAA 游戏录制的合成数据,以及四个主要的真实世界视频源:
- DL3DV-10K: 涵盖 65 个兴趣点类别的超过 10,000 个 4K 视频序列。
- RealEstate10K: 包含静态场景和清晰相机轨迹的室内房地产漫游视频。
- OmniWorld-CityWalk: 来自 YouTube 的第一人称城市步行镜头,涵盖各种天气和光照条件。
- SpatialVid-HD: 其中最大的子集,涵盖高清行人、驾驶和无人机航拍场景,以提高长尾视角覆盖率。
-
数据处理与元数据构建
- 统一重标注: 为了确保坐标约定和姿态表示的一致性,作者使用 ViPE 对所有真实世界数据进行重标注,而不是依赖捆绑的标注。
- 分层文本标注: 使用 InternVL3.5-8B,作者基于四层架构为每个片段生成结构化描述:用于整体总结的叙述性字幕、用于外观建模的静态场景字幕、用于事件和运动标签的密集时间字幕,以及感知质量评分。
- 感知质量评分: 每个片段在五个维度上进行 0 到 10 的评分:运动平滑度、背景动态、场景复杂度、物理合理性和整体质量。
-
过滤与筛选 作者实施了多阶段过滤过程,剔除了 20% 的原始数据以确保高质量:
- 轨迹与速度过滤: 使用三个标准来消除异常运动:局部几何一致性(通过深度重投影误差)、全局运动异常(通过最大到中值位移比)以及相机速度过滤(基于中值速度)。
- 质量过滤: 使用感知质量评分对片段进行进一步审核,以确保最终训练集经过高度精选。
方法
Matrix-Game 3.0 框架旨在解决交互式世界模型中长时生成和实时推理的挑战。该系统集成了四个关键组件:错误感知交互基础模型、相机感知长时记忆机制、训练推理对齐的少步蒸馏流水线,以及实时推理加速模块。这些组件协同工作,以实现大模型的稳定、高分辨率和实时生成。
框架的核心是错误感知交互基础模型,它构建在双向扩散 Transformer 之上。这种架构确保了模型在长期的自回归生成过程中能够保持一致性,同时支持精确的动作控制。模型处理一系列视频 latents,这些 latents 被划分为作为历史条件的过去帧和待预测的当前帧。在当前帧与过去帧拼接并输入 Transformer 之前,会向当前帧添加高斯噪声。训练目标是仅应用于当前帧的 flow-matching loss。为了实现鲁棒的动作控制,通过专门的 Cross-Attention 模块引入离散的键盘动作,而连续的鼠标控制信号则通过 Self-Attention 注入。模型还使用不完美的历史上下文进行训练,以确保与随后的蒸馏阶段保持一致。该设计的一个关键方面是自我修正公式,它使用错误缓冲区来收集并注入残差,从而在训练期间模拟曝光误差。
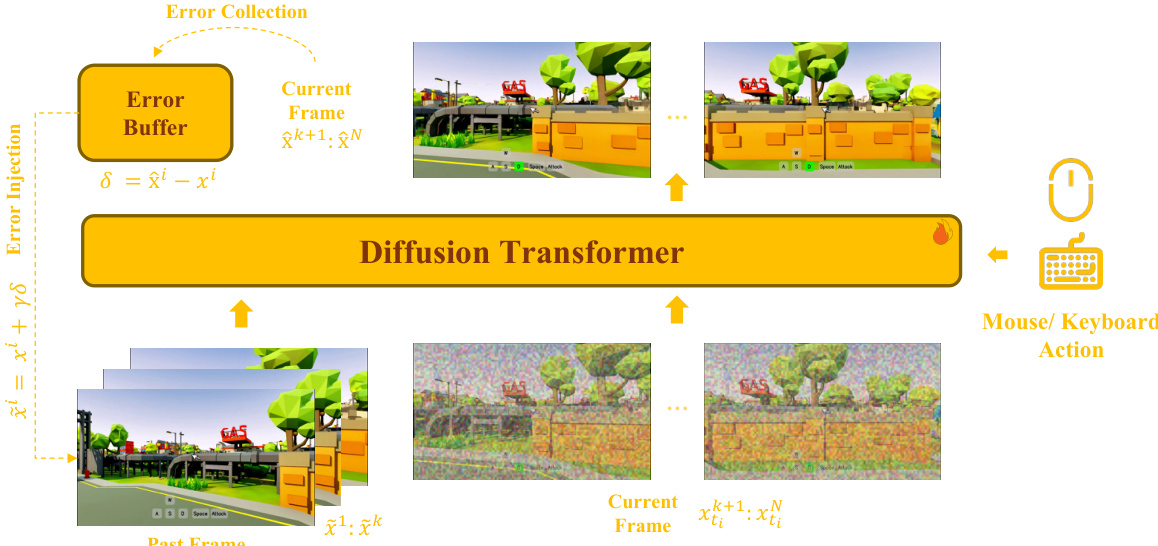
为了增强长时生成,框架引入了相机感知长时记忆机制。该机制构建在基础模型之上,并使用统一的 Diffusion Transformer (DiT) 来共同建模长期记忆、短期历史和当前预测目标。该机制并不将记忆视为一个独立的分支,而是将检索到的记忆 latents、过去帧 latents 和当前预测 latents 置于相同的注意力空间中,从而允许直接的信息交换。这种联合建模比独立的记忆路径更兼容流式生成。记忆选择是相机感知的,根据相机姿态和视场重叠来检索帧,以确保仅使用与视角相关的内容。当前目标与所选记忆之间的相对几何关系使用 Plücker 风格的线索进行编码,以帮助模型推理不同视角之间的场景对齐。为了减少训练与推理之间的不匹配,记忆路径在检索到的记忆和过去帧上也都使用了错误收集与注入。此外,通过将原始帧索引注入旋转位置编码(RoPE),并引入逐头扰动的 RoPE 基准,增强了模型的时序感知能力,从而减轻位置混叠并防止对远期记忆的过度依赖。

训练推理对齐的少步蒸馏流水线确保了蒸馏后的模型能够执行稳定的少步长时生成。这是通过训练双向学生模型来模仿实际推理过程实现的。学生模型执行多段 rollout,其中每一段都从随机噪声开始,而过去帧则取自前一段的末尾。这种多段方案创建了一个与推理行为高度匹配的训练环境,从而减少了曝光偏差。蒸馏目标基于分布匹配蒸馏 (DMD),它最小化了学生生成的分布与采样时间步下的数据分布之间的反向 KL 散度。该目标的梯度通过数据样本与生成样本的 score functions 之间的差异来近似。
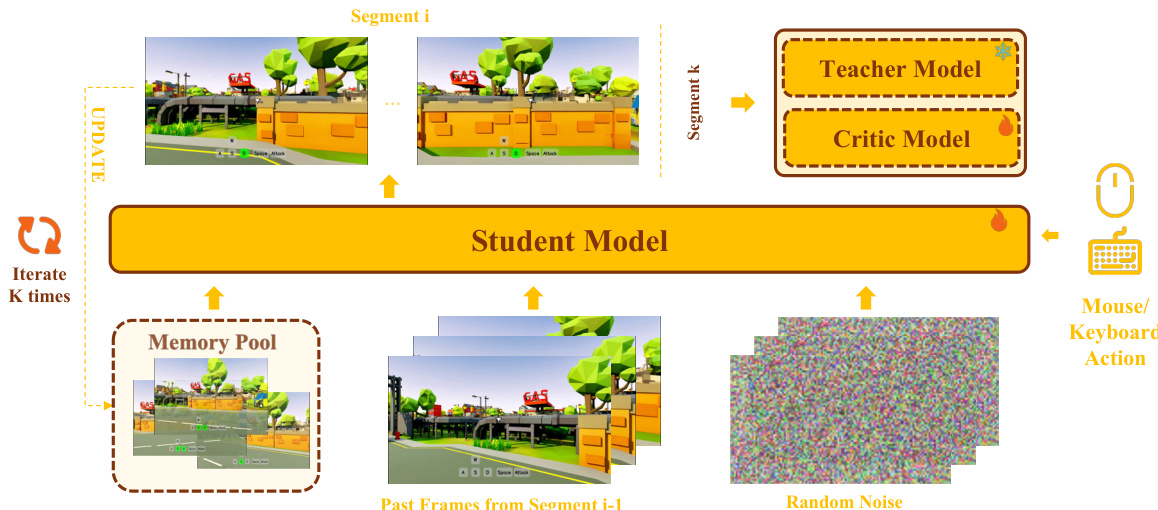
最后,实时推理加速模块确保了蒸馏模型能够实现高速推理。这通过几种策略完成:对 DiT 模型的注意力投影层进行 INT8 量化以减少计算量,通过 VAE 剪枝来加速解码,以及基于 GPU 的记忆检索。VAE 被剪枝为轻量级版本 MG-LightVAE,实现了显著的解码加速。通过使用基于 GPU 的采样近似方法进行相机感知记忆检索,加速了检索过程,这对于长迭代生成而言比精确的基于 CPU 的方法更高效。这些优化使得整个流水线在 720p 分辨率下,使用 5B 模型即可实现高达 40 FPS 的推理。
实验
评估通过测试交互式基础模型、其蒸馏版本以及各种加速策略,来验证长程场景一致性和推理效率。结果表明,增强型记忆的基础模型及其蒸馏版本能够有效地重建先前访问过的视角,并在长时生成过程中保持稳定的场景布局。此外,结合 INT8 量化、VAE 剪枝和基于 GPU 的记忆检索显著提高了吞吐量,其中剪枝后的 VAE 变体成功地在重建质量和实时性能之间取得了平衡。
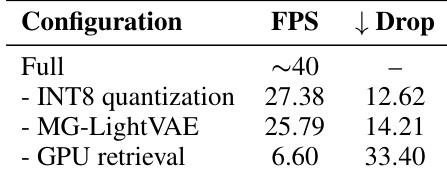
研究评估了不同加速组件对推理速度的影响。结果显示,移除单个组件会降低每秒帧数,其中 GPU 检索对性能的影响最为显著。移除 GPU 检索会导致每秒帧数下降幅度最大。INT8 量化和 MG-LightVAE 都有助于提高推理效率。完整配置实现了最高的吞吐量,表明组合优化具有协同效益。
作者将 MG-LightVAE 剪枝变体与原始 Wan2.2 VAE 的重建质量和效率进行了比较。结果表明,剪枝在保持可接受的重建保真度的同时减少了推理时间,较高的剪枝率会带来更大的加速,但代价是牺牲一定的质量。剪枝减少了全重建和仅解码器重建的推理时间。较高的剪枝率带来更大的加速,但会导致更大的质量下降。50% 剪枝变体在获得显著效率提升的同时保持了强大的重建质量。

研究评估了各种加速组件和剪枝率对推理速度和重建质量的影响。消融实验表明,结合 GPU 检索、INT8 量化和 MG-LightVAE 会产生协同效应,从而实现吞吐量最大化。此外,对 VAE 进行剪枝提供了一种显著减少推理时间的方法,适度的剪枝水平能够在效率提升与重建保真度之间成功取得平衡。