Command Palette
Search for a command to run...
TC-AE:解锁深度压缩 Autoencoders 的 Token 容量
TC-AE:解锁深度压缩 Autoencoders 的 Token 容量
Teng Li Ziyuan Huang Cong Chen Yangfu Li Yuanhuiyi Lyu Dandan Zheng Chunhua Shen Jun Zhang
摘要
我们提出了 TC-AE,一种基于 ViT 的深度压缩 autoencoder 架构。现有方法通常通过增加潜在表示(latent representations)的通道数,以在高压缩比下维持重建质量。然而,这种策略往往会导致潜在表示崩溃(latent representation collapse),从而降低生成性能。TC-AE 并不依赖日益复杂的架构或多阶段训练方案,而是从 token 空间(即像素与图像 latent 之间的关键桥梁)的角度出发,通过两项互补的创新来应对这一挑战:首先,我们在固定的 latent 预算下,通过调整 ViT 中的 patch size 来研究 token 数量缩放(token number scaling)问题,并发现激进的 token-to-latent 压缩是限制有效缩放的关键因素。为了解决这一问题,我们将 token-to-latent 压缩分解为两个阶段,旨在减少结构信息损失,并实现有利于生成的有效 token 数量缩放。其次,为了进一步缓解潜在表示崩溃,我们通过联合自监督训练(joint self-supervised training)增强了图像 token 的语义结构,从而获得对生成更加友好的 latents。凭借这些设计,TC-AE 在深度压缩下实现了显著提升的重建与生成性能。我们希望这项研究能够推动基于 ViT 的视觉生成 tokenizer 的发展。
一句话总结
TC-AE 是一种基于 Vision Transformer 的深度压缩 autoencoder 架构,它通过将 token 到 latent 的压缩分解为两个阶段,并采用联合自监督训练来增强语义结构,从而解决了 latent representation collapse 问题,实现了有效的 token 扩展,并取得了卓越的重建和生成性能。
核心贡献
- 本文介绍了 TC-AE,这是一种基于 Vision Transformer 的架构,专为深度压缩 autoencoder 设计,通过优化 token 空间来防止 latent representation collapse。
- 该工作提出了一种分阶段 token 压缩策略,将压缩过程重新分配到不同的 encoder 阶段,以减轻信息损失并实现 token 数量的有效扩展。
- 该方法结合了自监督联合训练机制,以增强图像 token 的语义结构,从而在 ImageNet 上提升了重建和生成性能。
引言
Latent diffusion models 依赖 tokenizer 将图像压缩为高效的 latent representations 以进行生成建模。虽然最近的研究通过降低空间分辨率来推动更深层次的压缩,但现有方法通常通过增加通道数来补偿,这往往会导致 latent representation collapse 并降低生成性能。作者利用 token 空间作为像素与 latent 之间的关键桥梁来解决这些限制。他们引入了 TC-AE,这是一种基于 ViT 的架构,利用分阶段 token 压缩来防止结构信息丢失,并结合了联合自监督训练目标来增强语义结构。这种方法实现了有效的 token 数量扩展,在高压缩率下显著提高了重建和生成质量。
方法
作者利用基于 Vision Transformer (ViT) 的框架进行图像 autoencoding,其中 encoder E 将输入图像 X∈RH×W×3 压缩为 latent representation z∈Rh×w×c,随后由 decoder D 进行重建。该过程始于 patch embedding 层 ϕp(⋅),它将图像划分为不重叠的 p×p patches,将每个 patch 投影为 d 维向量,并将网格展平为 N=HW/p2 个 tokens 的序列 T∈RN×d。这些 tokens 由一叠 Transformer 层 TF(⋅) 处理,然后通过 bottleneck 层 B(⋅) 进行压缩,以产生最终的 latent representation。从像素到 latent 空间的空间压缩率分解为两个阶段:像素到 token 的压缩 fpix→tok=p2 和 token 到 latent 的压缩 ftok→lat=N/(h⋅w),其中图像 tokens 作为输入域和 latent 域之间的信息桥梁。
为了增强 token 空间的语义结构并提高生成性能,作者引入了使用 iBOT 的联合自监督学习 (SSL) 目标。该框架采用学生-教师蒸馏范式,其中教师是学生的指数移动平均 (EMA)。学生通过两个增强流水线处理输入图像:Augstu(⋅) 生成带有随机 patch masking 和额外局部 crops 的全局 crops,而 Augtea(⋅) 产生两个全局 crops。对于 masked 全局 crops,学生被训练去预测教师的 patch-token 输出,从而形成掩码图像建模目标 LMIM。对于局部 crops,学生的 class-token 预测与教师进行对齐以强制语义一致性,从而产生 class-token 蒸馏损失 L[CLS]。组合后的自监督目标为 LiBOT=LMIM+L[CLS],这鼓励了 token representation 中的局部和全局语义结构。
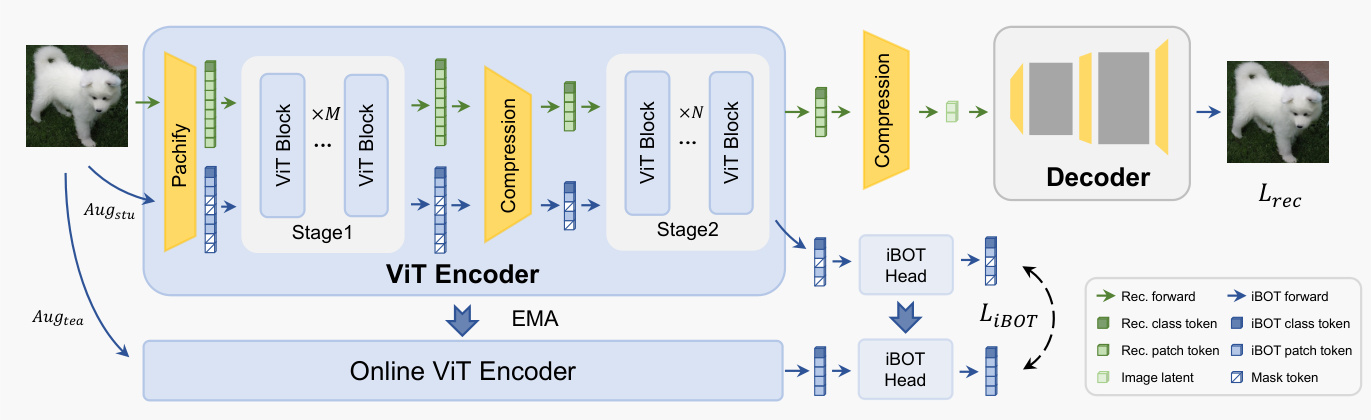
如下图所示,所提出的 TC-AE 架构由一个 ViT encoder、一个 latent bottleneck 和一个结构对称的 decoder 组成。encoder 设计结合了分阶段 token 压缩,以减轻 bottleneck 处的结构信息丢失。它首先使用较小的 patch size p 的 patch embedding 层来生成高分辨率的图像 tokens,从而减少初始像素到 token 阶段的信息损失。这些细粒度的 tokens 由前 M 个 ViT blocks 处理,以捕获丰富的视觉细节和语义结构。随后,一个中间 bottleneck 将 token 序列压缩为其长度的四分之一,产生紧凑且结构化的中间表示。这个压缩后的序列由剩余的 N 个 ViT blocks 进一步处理,之后第二个 bottleneck 产生用于下游生成建模的最终 latent representation。
TC-AE 的训练方案将 tokenizer 与自监督目标进行联合优化,使 ViT encoder 能够在不需要外部大规模预训练的情况下,学习具有更强语义正则化的 latent representations。这种轻量级的训练方法与 VTP 等方法形成对比,使得 TC-AE 在有限的计算资源下具有实用性。总训练目标将标准重建损失与自监督目标相结合:LTC-AE=αLrec+LiBOT。重建损失 Lrec 定义为 Lpix+λpLp+λqLq,其中 Lpix 是像素级 ℓ1 损失,Lp 是针对高层语义差异的感知损失,Lq 是增强重建图像真实感的对抗损失。分阶段 token 压缩与联合自监督训练的结合加速了 diffusion model 的收敛。
实验
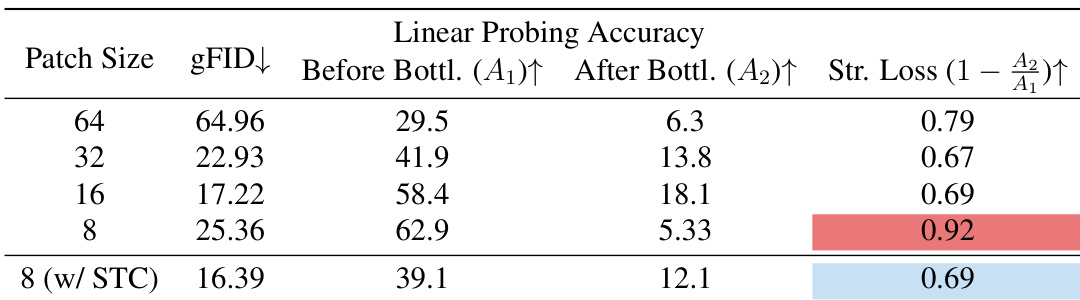
实验评估了扩展 token 数量和压缩策略如何影响深度压缩 autoencoder 的重建和生成性能。虽然增加图像 tokens 可以提高重建质量,但由于压缩 bottleneck 处严重的语义信息丢失,它无法增强生成性能。为了解决这个问题,作者提出了分阶段 token 压缩和自监督学习,这有效地保留了语义结构,并使生成质量能够随 token 密度进行扩展。这些方法协同工作,提高了训练效率,并以较低的计算成本实现了比现有 tokenizer 更优的生成结果。
作者分析了在固定 latent budget 下,增加图像 token 数量对重建和生成质量的影响。结果表明,虽然重建质量随着更多的 tokens 而提高,但生成性能并没有提高,这是由于 bottleneck 压缩过程中严重的语义信息丢失造成的。引入分阶段 token 压缩减轻了这种损失,从而实现了更好的生成质量并随 token 数量进行扩展。增加 token 数量提高了重建质量,但由于 bottleneck 处的语义丢失,并未提高生成质量。分阶段 token 压缩减少了结构信息丢失,使生成性能能够随 token 数量扩展。与现有方法相比,所提出的方法以更少的 tokens 和更低的计算成本实现了强大的生成质量。
该表概述了 TC-AE 中联合训练和 decoder finetuning 的训练设置。它指出了两个阶段之间在 epochs、batch size、学习率、优化器和其他超参数方面的差异。与 decoder finetuning 相比,联合训练使用更多的 epochs 和更大的 batch size。联合训练的基础学习率高于 decoder finetuning。联合训练和 decoder finetuning 使用不同的优化器,但两者都使用了 AdamW。
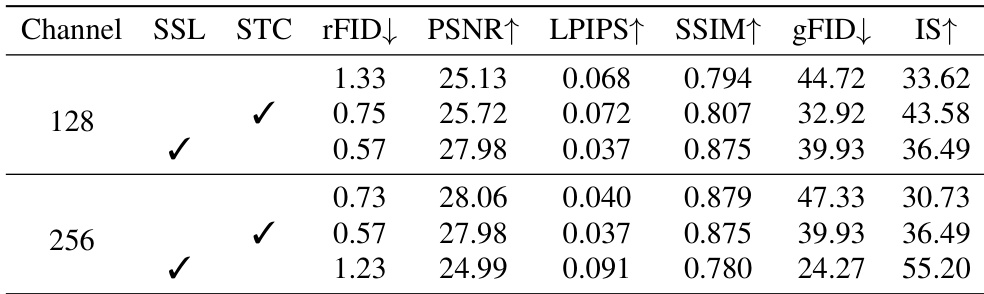
作者比较了 latent channel 维度对模型性能的影响,发现将通道大小从 128 增加到 256 会导致结果不一。虽然一些重建指标有所提高,但生成性能却有所下降,这表明更高的通道维度可能会加剧 representation collapse。将 latent channel 维度从 128 增加到 256 提高了重建质量,但降低了生成性能。重建保真度与可生成性之间的权衡显而易见,128 个通道提供了更好的生成效果。分阶段 token 压缩和自监督在两种通道大小下都能提高性能,但在 128 个通道时收益更为显著。
作者在相同设置下比较了 TC-AE 和 DC-AE,结果表明 TC-AE 以显著更低的计算成本实现了更好的生成性能。两个模型具有相同的 latent shape,但 TC-AE 在重建和生成指标方面均表现出更优的结果。TC-AE 以更低的计算成本实现了比 DC-AE 更好的生成性能。两个模型使用相同的 latent shape,表明这是一个公平的比较。与 DC-AE 相比,TC-AE 在重建和生成质量指标上均有提升。

作者研究了在固定 latent budget 下,增加图像 token 数量对重建和生成性能的影响。结果显示,虽然重建质量随着更多的 tokens 而提高,但由于压缩过程中的严重语义信息丢失,生成性能并没有提高。引入分阶段 token 压缩减轻了这种损失,并使生成质量能够随 token 数量扩展。在固定 latent budget 下,增加 token 数量提高了重建质量,但没有提高生成性能。分阶段 token 压缩减少了压缩过程中的语义丢失,使生成性能能够随 token 数量扩展。自监督和分阶段 token 压缩共同增强了生成质量,同时保持了重建保真度。
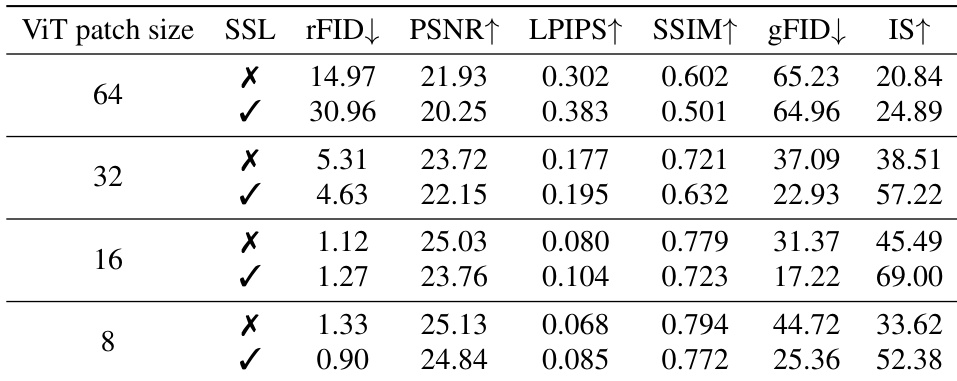
作者评估了 token 扩展、latent channel 维度和压缩策略对重建和生成性能的影响。虽然增加 token 数量或通道维度可以提高重建质量,但它们往往会导致语义丢失或 representation collapse,从而降低生成质量。通过实施分阶段 token 压缩和自监督,所提出的 TC-AE 模型有效地缓解了这些问题,与 DC-AE 相比,实现了更优的生成性能和更高的计算效率。