Command Palette
Search for a command to run...
FlowInOne: 将多模态生成统一为“图像输入、图像输出”的 Flow Matching
FlowInOne: 将多模态生成统一为“图像输入、图像输出”的 Flow Matching
Junchao Yi Rui Zhao Jiahao Tang Weixian Lei Linjie Li Qisheng Su Zhengyuan Yang Lijuan Wang Xiaofeng Zhu Alex Jinpeng Wang
摘要
长期以来,多模态生成一直由文本驱动的 pipeline 所主导,在这种模式下,语言决定视觉内容,却无法在视觉空间内进行推理或创作。我们对这一范式提出了挑战,探讨是否可以将包括文本描述、空间布局和编辑指令在内的所有模态,统一到一个单一的视觉表示(visual representation)中。为此,我们提出了 FlowInOne,这是一个将多模态生成重新定义为纯视觉流(visual flow)的框架。该框架将所有输入转换为 visual prompts,从而实现了一个由单一 flow matching 模型驱动的、简洁的“图像输入-图像输出”pipeline。这种以视觉为中心(vision-centric)的构建方式,自然地消除了跨模态对齐瓶颈、噪声调度(noise scheduling)以及特定任务的架构分支,将文本生成图像(text-to-image generation)、布局引导的编辑(layout-guided editing)以及视觉指令遵循(visual instruction following)统一到了一个连贯的范式之下。为了支持这一框架,我们推出了 VisPrompt-5M,这是一个包含 500 万个 visual prompt 对的大规模数据集,涵盖了包括物理感知力学动力学和轨迹预测在内的多种任务;同时,我们还推出了 VP-Bench,这是一个经过严格策划的 benchmark,用于评估指令忠实度、空间精度、视觉真实感和内容一致性。广泛的实验表明,FlowInOne 在所有统一生成任务中均达到了 state-of-the-art 的性能,超越了开源模型及具有竞争力的商业系统,为感知与创作在单一连续视觉空间内共存的全视觉中心生成模型奠定了新的基础。
一句话总结
通过将所有输入转换为视觉提示(visual prompts),FlowInOne 将文本到图像生成、布局引导编辑和视觉指令遵循统一到单一的“图像输入,图像输出”的 flow matching 范式中,并通过使用 VisPrompt-5M 数据集以及通过 VP-Bench 基准测试进行评估,消除了跨模态对齐的瓶颈。
核心贡献
- 本文介绍了 FlowInOne,这是一个统一的 flow matching 框架,它将多模态生成重新定义为以视觉为中心的“图像输入,图像输出”范式。该方法将所有输入转换为 visual prompts,从而消除了文本编码器和特定模态的桥梁,使单个模型能够处理文本到图像生成、布局引导编辑和视觉指令遵循。
- 本研究提出了 VisPrompt-5M,这是一个包含 500 万个 visual prompt 对的大规模数据集,涵盖了物理感知力学动力学和轨迹预测等多种任务。该数据集通过连续的视觉演化提供监督,实现了统一训练并在多个生成任务中具有强大的泛化能力。
- 研究人员开发了 VP-Bench,这是一个精心策划的评估基准,旨在从四个关键维度评估模型性能:指令忠实度、空间精度、视觉真实感和内容一致性。使用该基准进行的实验表明,FlowInOne 达到了最先进的性能,超越了现有的开源系统和具有竞争力的商业系统。
引言
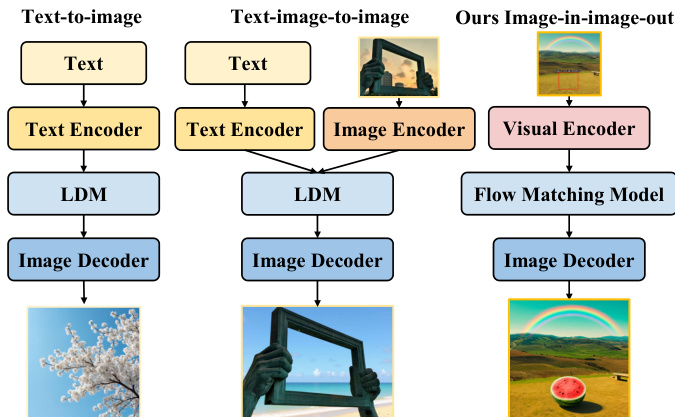
多模态生成目前依赖于以文本为主的流水线,其中语言嵌入决定了视觉输出,这造成了一种根本性的不对称,即视觉无法独立进行推理或生成。这些传统架构通常面临跨模态对齐的瓶颈,并且需要复杂的、针对特定任务的分支来处理不同类型的调节条件。作者利用一种名为 FlowInOne 的以视觉为中心的方法,将多模态生成重新定义为纯粹的“图像输入,图像输出”流水线。通过将包括文本和空间布局在内的所有输入转换为 visual prompts,并使用单一的 flow matching 模型,他们将文本到图像生成、布局引导编辑和视觉指令遵循统一到了一个连续的视觉空间中。
数据集
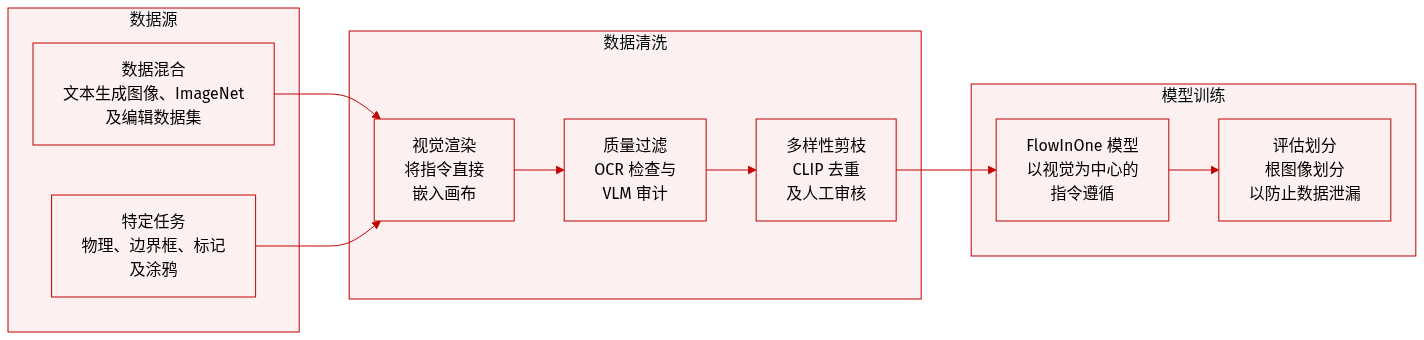
作者开发了 VisPrompt-5M,这是一个包含约 500 万个图像到图像对的大规模数据集,旨在实现统一的以视觉为中心的指令遵循范式。作者没有使用单独的文本通道,而是将所有指令(如文本、边界框或箭头)直接嵌入到输入图像画布上。
数据集组成与来源 数据集分为八个任务类别,并归纳为三大能力:
- 基础生成: 包括文本到图像(来自 text-to-image-2M 的 2M 个对)和类别到图像(860K 高质量 ImageNet 子集),以建立基础的语义到视觉的映射。
- 统一图像编辑: 这是最大的组成部分,涵盖了语义操作、属性更改和结构化任务。来源包括 GPT-Image-Edit、Pico-Banana、UnicEdit(产生 1.6M 个过滤后的语义对)以及 PixWizard(315K 用于修复和深度到图像等任务的结构化对)。
- 物理理解: 用于运动和动力学的专门子集,包括轨迹理解(1.5K Blender 渲染的对)和力理解(利用 Force Prompting 数据集)。
- 专业几何编辑: 包括文本边界框编辑(通过 Qwen3-VL 合成的 24K 高质量对)、视觉标记编辑(使用箭头注释的 250K 个对)以及涂鸦编辑(源自网络图像的 1K 高保真对)。
处理与质量控制 作者实施了严格的多阶段流水线以确保高数据保真度:
- 视觉指令渲染: 对于基于文本的任务,指令以随机的字体、大小、颜色和位置渲染到画布上,以防止排版过拟合。
- 基于 OCR 的验证: OCR 引擎检查渲染文本的可读性,丢弃字符错误率(CER)较高的对。
- 基于 VLM 的审计: 先进的多模态大语言模型(例如 Qwen3-VL)充当裁判,验证语义对齐、空间精度(例如检查物体是否与边界框匹配)和视觉真实感。
- 多样性去重: 作者使用 CLIP 嵌入和余弦相似度阈值来修剪冗余概念并防止模式崩溃。
- 人工检查: 对于像涂鸦编辑这样高度复杂的任务,作者进行人工策划,以确保绝对的结构对齐并消除生成伪影。
数据使用与防止泄漏 该数据集用于在纯粹以视觉为中心的范式下训练 FlowInOne 模型。为了确保 VP-Bench 评估的完整性,作者实施了严格的双重防泄漏协议:
- 根图像划分: 数据集基于底层的未编辑基础图像进行划分,而不是基于单个指令对,确保模型永远不会看到基准测试的背景或布局。
- 视觉去重: 作者使用 CLIP 嵌入进行特征级过滤,积极丢弃任何与基准测试图像表现出高度视觉相似性的训练对。
方法
作者利用 flow matching 框架将图像生成建模为共享潜在空间内的连续传输过程,从而消除了对复杂噪声调度和显式调节分支的需求。该方法的核心是统一的视觉编码策略,它将文本指令和各种视觉线索直接集成到图像画布上,从而在不依赖跨模态对齐模块的情况下保留空间布局和结构先验。这个统一的图像由 SigLIP Vision Transformer 处理以提取 patch 级别的语义特征,然后通过一个 MLP 投影器投影到目标嵌入空间中。得到的融合表示 Xfuse 封装了文本语义和视觉几何。
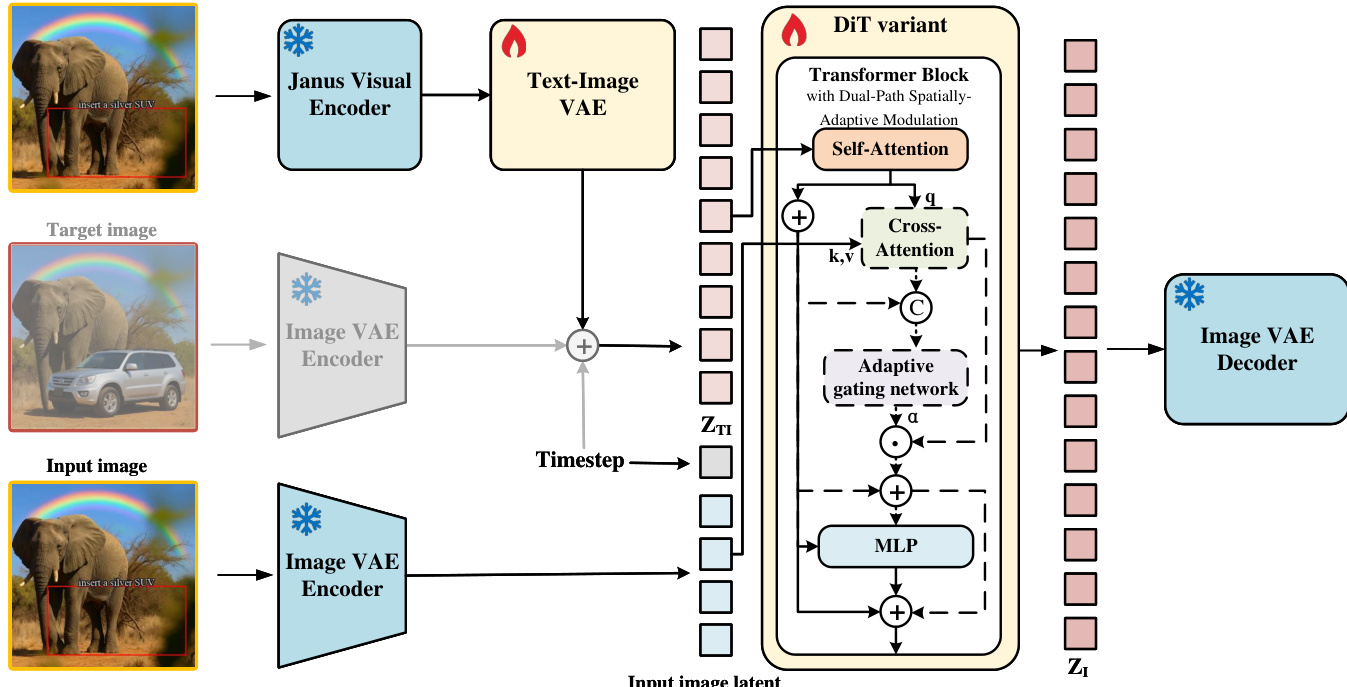
如下图所示,该架构在 DiT 变体中使用双路径空间自适应调制(Dual-Path Spatially-Adaptive Modulation)机制,以平衡结构保留和指令遵循。该过程始于将输入图像和视觉指令编码到共享潜在空间。视觉指令首先由 Janus Visual Encoder 和 Text-Image VAE 处理,而目标图像和输入图像则由冻结的 Image VAE 编码。这些潜在表示 ZTI 和 ZI 作为 flow matching 过程的源分布和目标分布。
在训练期间,模型通过最小化相对于地面真值速度 vt∗ 的均方误差(MSE)来学习随时间变化的速率场 vθ(zt,t),其中 vt∗ 源自线性插值 zt=tz1+(1−(1−σmin)t)z0。推理过程涉及求解常微分方程 dtdzt=vθ(zt,t),从 t=0 到 t=1,确定性地将视觉指令潜在表示演化为最终的目标图像。
双路径空间自适应调制机制旨在动态补偿缺失的结构流形。对于文本到图像生成,模型绕过 cross-attention 层以防止无关噪声,确保生成轨迹严格遵循文本语义。对于图像编辑,源图像被映射到潜在空间,并通过 cross-attention 计算结构增量 ΔHstruct。一个轻量级的自适应门控网络预测一个 token 级别的权重向量 Λ,用于控制结构流形的渗透。最终层的输出通过条件公式进行集成,其中调制项仅在编辑任务中激活,从而有效地减轻编辑冲突并减少演化误差。
实验
研究人员使用精心策划的 VP-Bench 基准评估了 FlowInOne,利用视觉语言模型和人类专家来评估指令忠实度、内容一致性、视觉真实感和空间精度。对比实验表明,该模型在“图像输入,图像输出”范式中达到了最先进的性能,特别是与开源和商业基准相比,在细粒度空间控制和物理推理方面表现出色。消融研究进一步证实,联合训练和空间自适应调制对于在单一框架内统一多样化的生成和编辑任务至关重要。
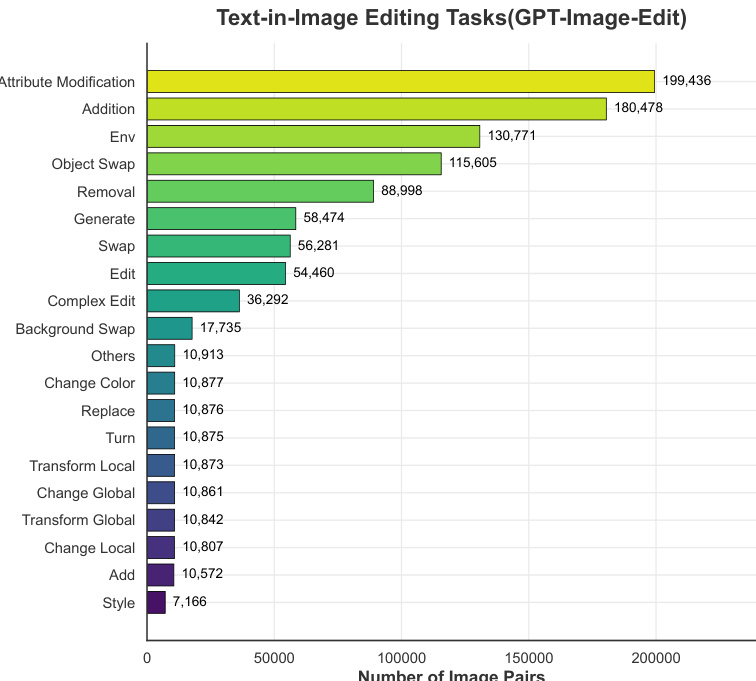
柱状图显示了各种文本在图像编辑任务中的图像对数量,其中属性修改和添加是最频繁的类别。数据表明存在显著的不平衡,少数任务类型主导了数据集,而其他任务的实例则少得多。属性修改和添加是最常见的文本在图像编辑任务。大多数任务的图像对少于 20,000 个。数据集高度不平衡,多个类别的样本显著少于其他类别。
表格显示了不同视觉编辑类别的保留率,并列出了主要的拒绝原因以及所使用的相应 VLM/OCR 过滤方法。保留率因类别而异,表明了任务难度和模型性能的差异。不同编辑类别的保留率不同,其中文本在图像编辑显示出最高的保留率。主要的拒绝原因因类别而异,包括语义不一致和几何错位。每个类别使用不同的 VLM/OCR 过滤方法来评估特定的失败模式。

表格概述了基准数据集的组成,详细说明了主要来源以及各种任务类别的初始对和策划后的对的数量。该数据集涵盖了基础生成和编辑任务,策划后的数据集总规模约为 536 万个对。数据集包括多样化的任务类别,如文本到图像生成和各种形式的图像编辑。数据集的来源从大规模文本到图像数据集到针对特定编辑任务的专门集合不等。所有类别的策划对总数约为 536 万。

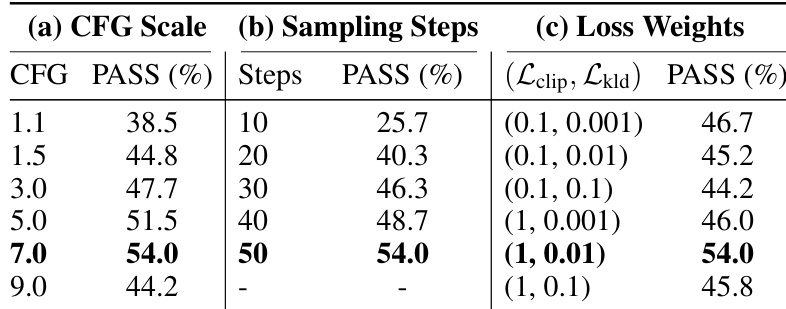
表格概述了 VP-Bench 基准的结构,详细说明了其顶级任务和具有相应对计数的子类别。它展示了多样化的视觉指令任务,包括文本到图像、文本在图像编辑和空间推理,基准总规模包含 1,060 个对。该基准包括多样化的视觉指令任务,如文本到图像和文本在图像编辑。文本在图像编辑是最大的类别,拥有 290 个对,涵盖了各种子任务。基准总规模为 1,060 个对,任务分布在不同的类别中。
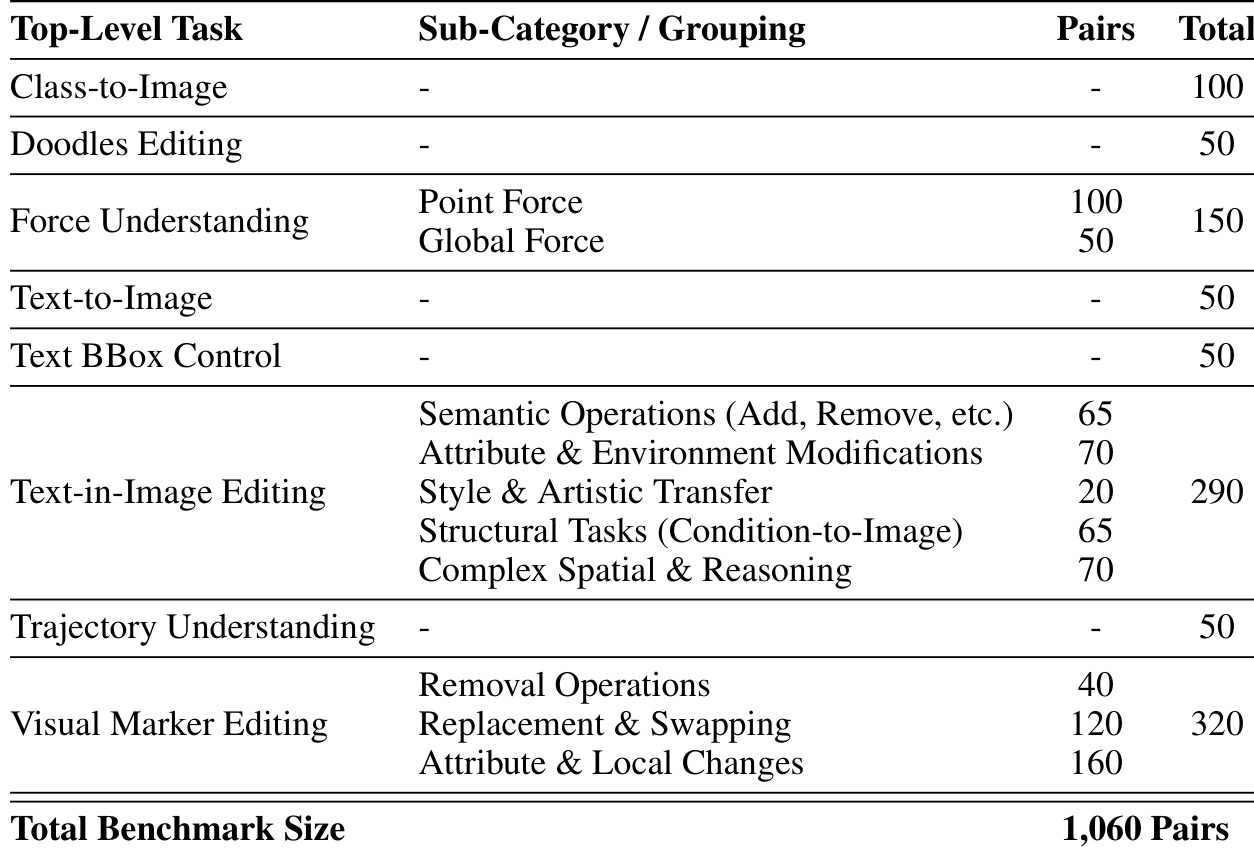
研究评估了不同超参数对模型性能的影响,表明最佳设置可以产生最高的通过率。性能随 CFG scale、采样步数和损失权重的变化而显著变化,特定配置可达到峰值结果。通过率在 CFG scale 为 7 且采样步数为 50 时达到顶峰。性能会随着过高的 CFG scale 或过低的采样步数而下降。最佳损失权重在 CLIP 对齐和 KL 散度惩罚之间取得了平衡。
评估检查了 VP-Bench 基准的组成和质量,并结合消融研究来优化模型性能。分析显示,任务分布高度不平衡,由属性修改主导,并强调由于特定的语义和几何挑战,保留率在不同编辑类别之间存在差异。此外,超参数研究表明,模型的成功取决于在采样步数、CFG scale 和损失权重之间找到精确的平衡。