Command Palette
Search for a command to run...
GrandCode: 通过 Agentic Reinforcement Learning 实现竞技编程中的 Grandmaster 水平
GrandCode: 通过 Agentic Reinforcement Learning 实现竞技编程中的 Grandmaster 水平
DeepReinforce Team Xiaoya Li Xiaofei Sun Guoyin Wang Songqiao Su Chris Shum Jiwei Li
摘要
算法竞赛(Competitive programming)仍是人类在编程领域对抗 AI 的最后几大阵地之一。迄今为止,最顶尖的 AI 系统在算法竞赛中的表现仍逊于人类顶尖选手:即便在非实战竞赛环境下评估,Google 最新的 Gemini 3 Deep Think 也仅获得了第 8 名。在本项研究中,我们推出了 GrandCode,这是一个专为算法竞赛设计的 multi-agent RL 系统。GrandCode 的卓越能力归功于两个关键因素:(1) 它编排了多种 agentic 模块(包括假设提出、解题器、测试用例生成、总结等),并通过 post-training 和在线 test-time RL 对这些模块进行协同优化;(2) 我们引入了专门为多阶段 agent rollouts 设计的 Agentic GRPO,以应对 agentic RL 中普遍存在的延迟奖励(delayed rewards)和严重的 off-policy drift 问题。GrandCode 是首个在算法竞赛实战中持续击败所有人类参赛者的 AI 系统:在最近的三场 Codeforces 实战竞赛中,即 Round 1087(2026年3月21日)、Round 1088(2026年3月28日)和 Round 1089(2026年3月29日),GrandCode 全部荣获第一名,超越了包括传奇 Grandmaster 在内的所有人类选手。GrandCode 的表现表明,AI 系统已达到在最具竞争力的编程任务上超越最强人类程序员的水平。
一句话总结
DeepReinforce 团队推出了 GrandCode,这是一个 multi-agent reinforcement learning 系统,它通过编排专门的 agentic 模块,并利用一种新颖的 Agentic GRPO 方法来解决多阶段 rollouts 和延迟奖励问题,最终成为第一个在 Codeforces 实时竞赛中持续获得第一名并超越人类 grandmasters 的 AI 系统。
核心贡献
- 本文介绍了 GrandCode,这是一个 multi-agent reinforcement learning 系统,通过 post-training 和 online test-time reinforcement learning,编排了包括假设提出、求解器和测试用例生成器在内的各种 agentic 模块。
- 本研究提出了 Agentic GRPO,这是 Group Relative Policy Optimization 的一种专门变体,它利用延迟修正机制来解决 off-policy drift 问题,并改进多阶段 agent rollouts 过程中的 credit assignment。
- 结果表明,GrandCode 是第一个在实时编程竞赛中持续超越人类参赛者的 AI 系统,在 2026 年 3 月连续三次 Codeforces 轮次中获得第一名。
引言
竞技编程是评估人工智能推理和编程能力的关键基准。虽然最近的大语言模型取得了显著进展,但现有系统在匹配精英人类程序员的表现方面仍面临挑战,特别是在实时竞赛条件下。以往的方法在多阶段推理以及复杂、多轮 agentic rollouts 期间发生的严重 off-policy drift 方面经常遇到困难。为了解决这些问题,作者推出了 GrandCode,这是一个 multi-agent reinforcement learning 系统,它编排了用于假设提出、求解和测试用例生成的专门模块。作者利用了一种称为 Agentic GRPO 的新颖优化方法,该方法利用延迟修正机制来改进长 agentic loops 中的 credit assignment。该系统代表了第一个在 Codeforces 实时竞赛中持续获得第一名的 AI,甚至超越了传奇级的人类 grandmasters。
数据集
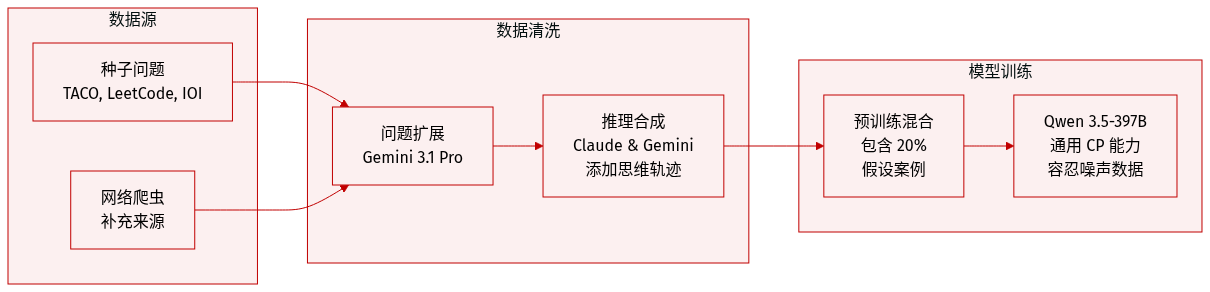
数据集概览
作者通过多阶段合成方法构建了一个大规模的竞技编程训练语料库:
-
数据集组成与来源
- 该过程始于一个来自 TACO、LeetCode、USACO、CodeContests 和 IOI 的竞技编程问题种子集,并辅以额外的网络爬取数据。
- 使用 Gemini 3.1 Pro 将该种子集扩展为一个规模更大、更多样化的语料库。
-
数据处理与元数据构建
- 为了促进推理训练,作者使用 Claude 4.6 和 Gemini 3.1 为问题生成详细的思维过程。
- 这产生了一个由问题、思维过程和解决方案组成的结构化数据集。
- 为了让模型准备好应对假设驱动的场景,20% 的持续预训练样本被随机转换为假设条件案例。在这些实例中,由特定 policy 生成的假设会在生成推理轨迹之前被纳入 prompt 中。
-
训练用途与策略
- 合成数据用于 Qwen 3.5-397B 模型的持续预训练。
- 作者在此阶段采取了在噪声数据上进行训练的策略,承认某些合成的推理轨迹或答案可能是错误的。
- 此阶段的主要目标是增强通用的竞技编程能力,而不是提供精确的监督,细粒度的过滤和高质量监督保留给随后的 Supervised Fine Tuning (SFT) 阶段。
方法
该系统采用了一种专为竞技编程问题求解设计的多组件架构,将主求解器与用于假设生成、总结和测试用例创建的辅助模块集成在一起。总体框架如图 1 所示,包含两个主要阶段:post-training 和 test-time solving。在 post-training 期间,模型在噪声竞技编程数据上进行持续预训练,随后在高质量的(问题,思维过程,解决方案)三元组上进行 supervised fine-tuning (SFT)。此 SFT 阶段独立训练主求解器 πmain、假设模型 πhypothesis 和总结模型 πsummary。最后一个阶段是 multi-component reinforcement learning (RL),其中这些组件被联合优化,以在最终目标下提高协作能力。在测试时,模型利用难度感知路由来确定合适的策略:对于简单问题,它使用直接生成;而对于较难的问题,它会进入 test-time RL 循环。
系统的推理核心由假设生成与验证模块引导。如图 2 所示,该过程始于模型提出一个中间假设,例如问题的紧凑数学特征描述。然后通过生成小的随机实例,并将假设的结果与暴力求解器计算出的精确解进行比较来验证该假设。不匹配会触发假设修订循环。当问题可以转化为符号形式时,此阶段还可以利用 Wolfram Alpha 等符号工具来简化或求解表达式。通过这种迭代验证的假设将被提升,用于指导主解决方案的合成过程。
为了管理长推理轨迹的计算成本,系统采用了独立的总结模型 πsummary。该模型经过训练,可以将长的思维轨迹逐步压缩成一个紧凑的状态,该状态保留了下游求解所需的必要信息。训练过程包含两个阶段:首先,每个局部总结步骤使用 RL 进行优化,其 reward 鼓励总结保留剩余轨迹和最终答案所需的信息。其次,使用最终答案的似然度作为终端 reward,对整个渐进链进行端到端训练。这种模块化训练方法提供了更密集的中间监督,并确保总结器在集成到整个系统之前得到了充分优化。

系统还结合了对抗性测试用例生成以提高鲁棒性。这通过两种策略实现:差异驱动的测试生成,即生成能够暴露多个候选解之间行为差异的输入;以及解攻击,即直接将候选解与标准解进行比较,以识别 bug 并生成对抗性案例。这些生成的测试用于微调模型,使其能够按需产生此类对抗性示例。
在 test-time solving 期间,模型使用基于难度的分类器来路由问题。对于简单问题,它执行直接生成和评估。对于较难的问题,它进入 test-time RL 循环。该循环涉及生成候选解,使用一组对抗性测试对其进行评估,并使用验证反馈通过 LoRA(一种轻量级适配方法)来更新 policy。该循环还维护搜索历史的全局总结,这有助于引导探索。整体架构设计注重效率,主 MoE 求解器 policy 运行在专用的分布式 GPU mesh 上,而较小的辅助 policy 则在单独的 GPU 池上异步运行,代码执行由 CPU sandbox 处理。
实验
评估通过 Codeforces 实时竞赛、真实世界问题求解以及包括持续训练、supervised fine-tuning 和 reinforcement learning 在内的各种训练阶段来衡量 GrandCode。结果表明,该系统达到了顶尖的竞赛水平,甚至在实时竞赛中超越了精英人类选手。此外,实验表明,虽然 offline reinforcement learning 显著提升了核心问题求解能力,但 test-time reinforcement learning 在解决最困难的挑战方面特别有效。
作者在真实的 Codeforces 问题上评估了测试用例生成,展示了通过迭代改进带来的提升。通过测试套件的每个增强阶段,通过率都会提高,最终实现完全覆盖。经过差异驱动的测试用例生成和解攻击后,通过率从 42 提高到 48。利用提交反馈和在线生成进行进一步改进后,通过率提高到 50。经过迭代测试套件优化后,所有 50 个测试用例均通过。

作者使用 100 个问题的基准测试评估了不同训练阶段对模型性能的影响。结果显示,持续训练和 supervised fine-tuning 提高了接受率和加权得分,而添加总结模块会导致性能轻微下降。与基础模型相比,持续训练提高了接受率和加权得分。Supervised fine-tuning 进一步提高了接受率和难度加权得分方面的性能。尽管接受率更高,但引入总结会导致性能轻微下降。

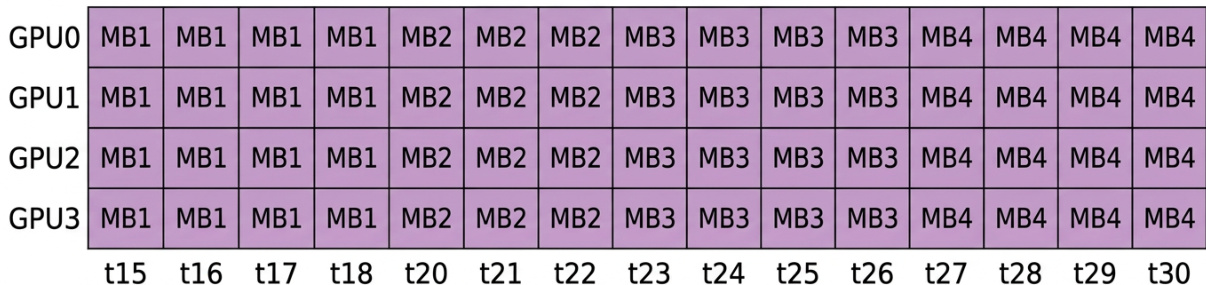
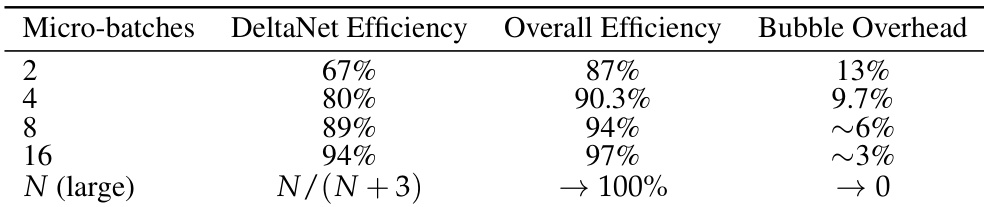
该表比较了不同 micro-batch 大小下的效率指标,显示较大的 micro-batches 在减少 bubble overhead 的同时提高了整体效率。DeltaNet 效率随 micro-batch 大小增加而提高,并在 batch size 变大时趋于最大值。整体效率随较大的 micro-batches 而提高。DeltaNet 效率随 micro-batch 大小增加。随着 micro-batch 大小增加,Bubble overhead 降低。
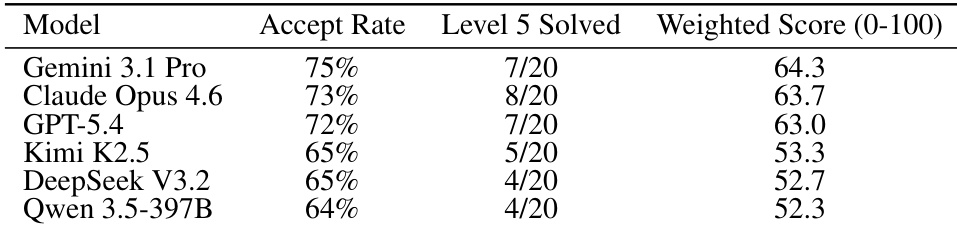
作者在 100 个问题的基准测试上比较了多个模型,测量了接受率、解决的最难问题数量以及难度加权得分。结果显示,Gemini 3.1 Pro 在所有指标上均实现了最高性能,其次是 Claude Opus 4.6 和 GPT-5.4,而 Qwen 3.5-397B 表现最低。Gemini 3.1 Pro 在评估的模型中实现了最高的接受率和加权得分。Claude Opus 4.6 解决的 Level 5 问题比除 Gemini 3.1 Pro 以外的其他模型都多。Qwen 3.5-397B 在所有评估指标中表现最低。
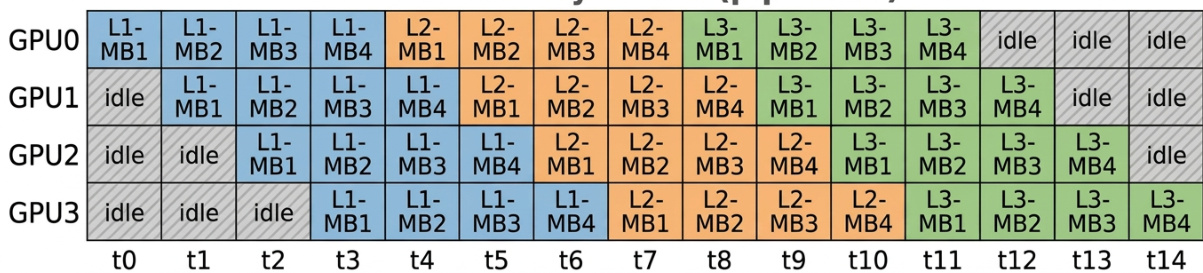
该表显示了四个 GPU 随时间分配任务的情况,每个 GPU 在不同时间点处理不同等级和模块。GPU 在执行阶段大部分时间处于活跃状态,但在某些时期会出现空闲,特别是在早期和后期阶段。任务随时间分布在四个具有不同等级和模块的 GPU 上。GPU 在执行阶段处于活跃状态,并在某些间隔处于空闲。工作负载在整个时间线中在 GPU 之间动态转移。
实验评估了模型性能的各个方面,包括测试用例生成、训练方法、架构效率和硬件利用率。结果表明,迭代改进和 supervised fine-tuning 显著增强了测试覆盖率和问题求解能力,而较大的 micro-batch 大小通过减少 overhead 提高了计算效率。对比分析显示,Gemini 3.1 Pro 在基准任务上优于其他模型,而 GPU 利用率模式揭示了执行期间的动态工作负载分布。